BYOSC Build Your Own Scalable Chatbots
1.0.0
عند التحضير لامتحانات الجامعة ، ثبت أن وجود شريك ضروري لاكتشاف فجوات المعرفة وتوضيح شكوك محددة حول الموضوع الذي عولج خلال الفصول الدراسية. في حين أن chatbots تعتمد على LLMs مثل ChatGPT و Phind و Clod يقدمون المساعدة للطلاب بالفعل ، لا يمكنهم تقديم مساعدة محاضرة/مواد خاصة في دورات الجامعة للطلاب. نقترح إنشاء نظام لضبط chatbots على مواد محددة من دورات محددة. بفضل هذا ، سنقوم بإنشاء رفاق الدراسة لدورات طالب جامعي نموذجي ، قادرين على الإجابة على الشكوك ، وإنشاء أسئلة وأكثر!
من الممكن اختبار chatbot في هذا الرابط.
النطاق الضمني للمشروع (والدورة بأكملها) هو بناء بنية تحتية قابلة للتطوير يمكنها استضافة MLOPs لدينا. لهذا السبب ، يتم تقسيم خط أنابيب ML المترابط التقليدي إلى ثلاث عمليات مختلفة: خط أنابيب الميزات ، خط أنابيب التدريب ، خط أنابيب الاستدلال .
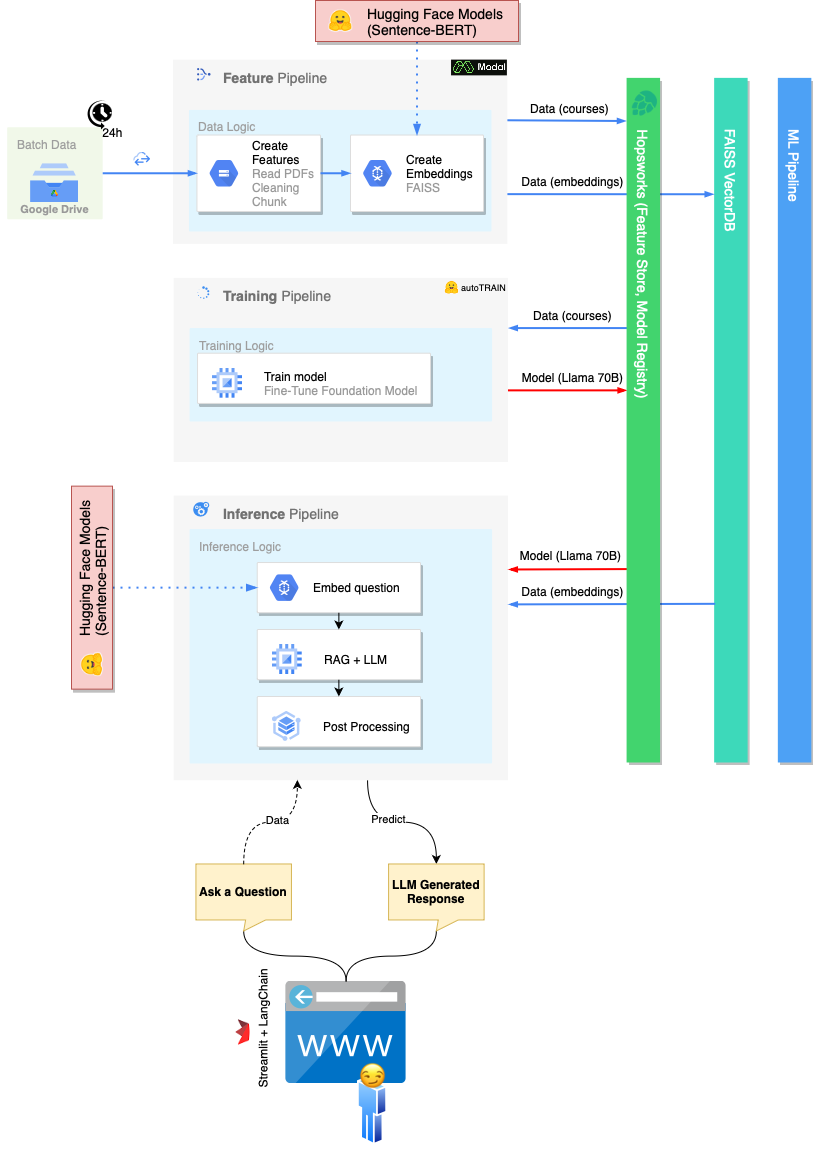
خط أنابيب الميزة مسؤول عن:
هناك العديد من الخيارات لتشغيل خط أنابيب الميزة:
FeaturePipeline/Reading.ipynbFeaturePipeline/FeaturePipeline.py باستخدام python3 FeaturePipeline/FeaturePipeline.py يتم تعديل نسخة من هذا الأخير قليلاً في ملف FeaturePipeline/FeaturePipeline_modal.py لجعلها قابلة للتشغيل على خدمة الاستضافة الوسائط باستخدام modal [run|deploy] FeaturePipeline/FeaturePipeline.py
خط أنابيب التدريب مسؤول عن:
لتنفيذ خط أنابيب التدريب ، قم بتشغيل دفتر TrainingPipeline/FineTuning.ipynb
خط أنابيب الاستدلال مسؤول عن:
لتنفيذ خط أنابيب الاستدلال ، قم streamlit run chatbot_app.py
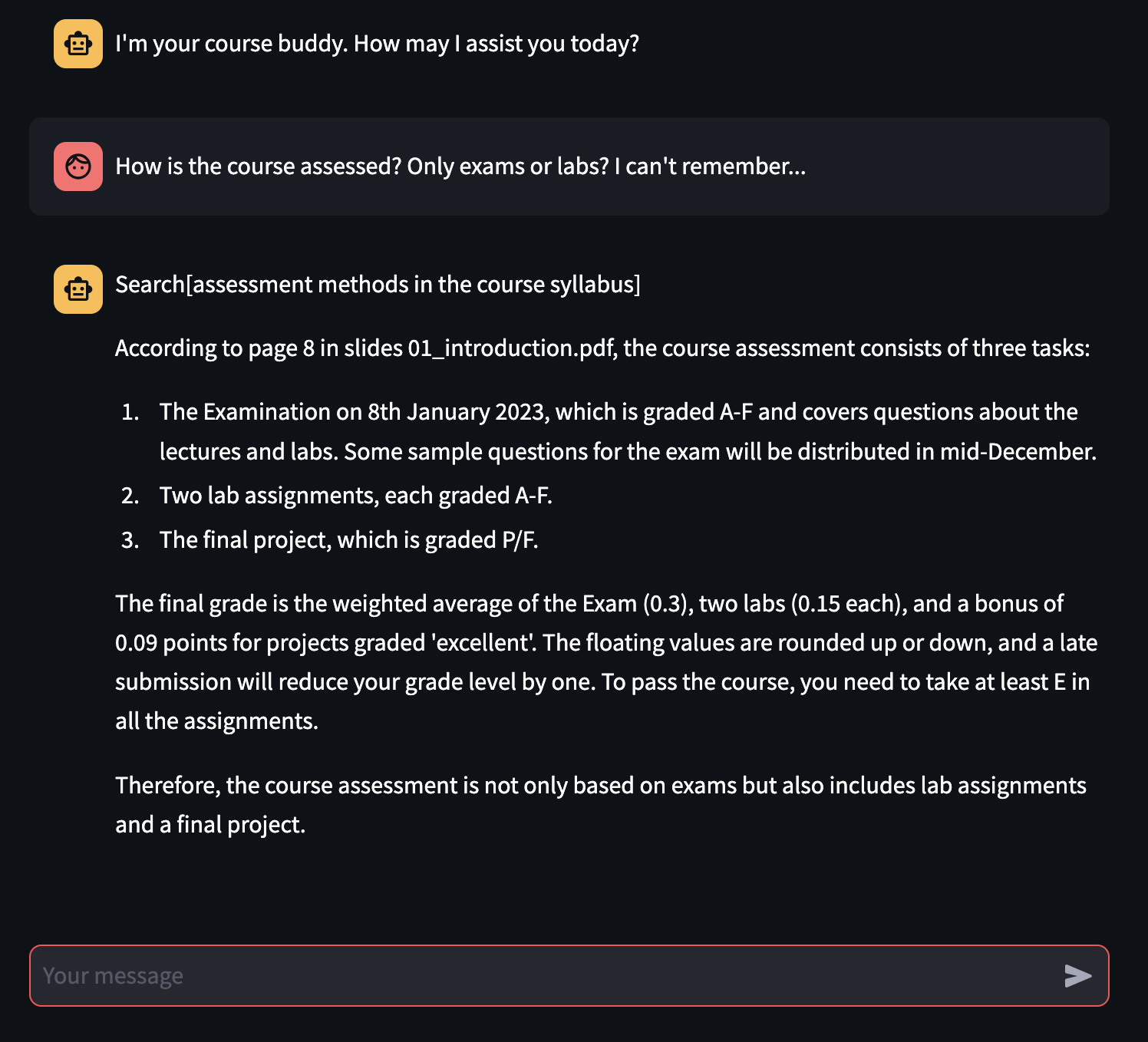
على الرغم من أن عملية الضبط بشكل تجريبي ليست كافية لجعل النموذج التأسيسي أفضل باستمرار من النموذج غير المضبط ، إلا أن chatbot التي تدعم RAG لا يمكنها فقط الإجابة على أسئلة المستخدم بشكل صحيح متابعة المادة الأصلية ، ولكنها قادرة أيضًا على إعطاء (في الغالب) المراجع الصحيحة للمكان الذي يتم فيه أخذ الإجابة من الميزة الأساسية لدراسة الطالب للامتحان الجامعي!
لا يعمل الضبط الدقيق وكذلك المقصود بسبب نقص المواد المستخدمة والموارد الحسابية. كعمل مستقبلي ، نريد تحسين عملية استخراج المعرفة واستخدام المزيد من الطاقة الحسابية لمعالجة المشكلات الموضحة في التقرير.


