BYOSC Build Your Own Scalable Chatbots
1.0.0
大学の試験の準備の際、パートナーを持つことは、授業中に扱われたトピックに関する知識のギャップを発見し、明確にするために不可欠であることが証明されています。 ChatGpt、Phind、ClodなどのLLMに基づいたチャットボットはすでに学生に助けを提供していますが、学生の大学コースで講義/素材固有のヘルプを提供することはできません。特定のコースの特定の素材でチャットボットを微調整するシステムを作成することを提案します。このおかげで、典型的な大学生のコースの研究仲間を作成し、疑問に答えたり、質問を生み出したりすることができます!
このリンクでチャットボットをテストすることができます。
プロジェクトの暗黙の範囲(およびコース全体)は、MLOPをホストできるスケーラブルなインフラストラクチャを構築することです。このため、従来のモノリシックMLパイプラインは、機能パイプライン、トレーニングパイプライン、推論パイプラインの3つの異なるプロセスに分割されています。
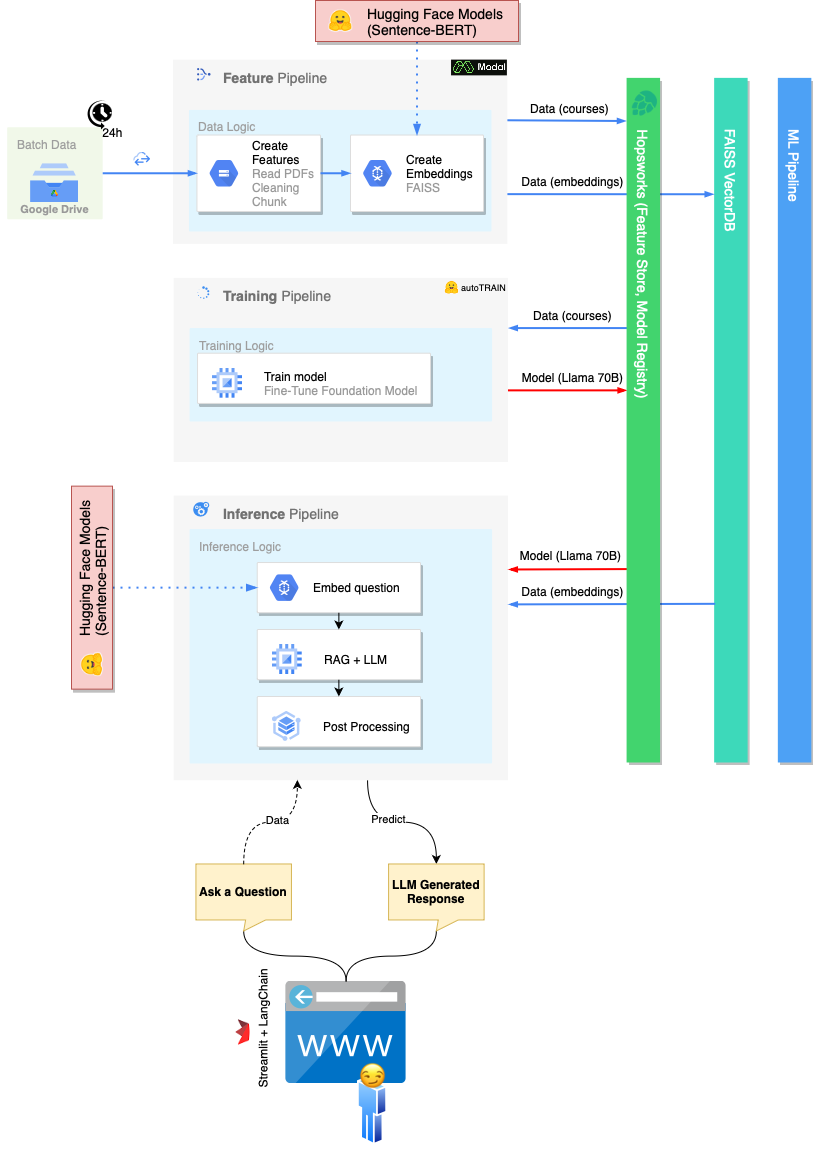
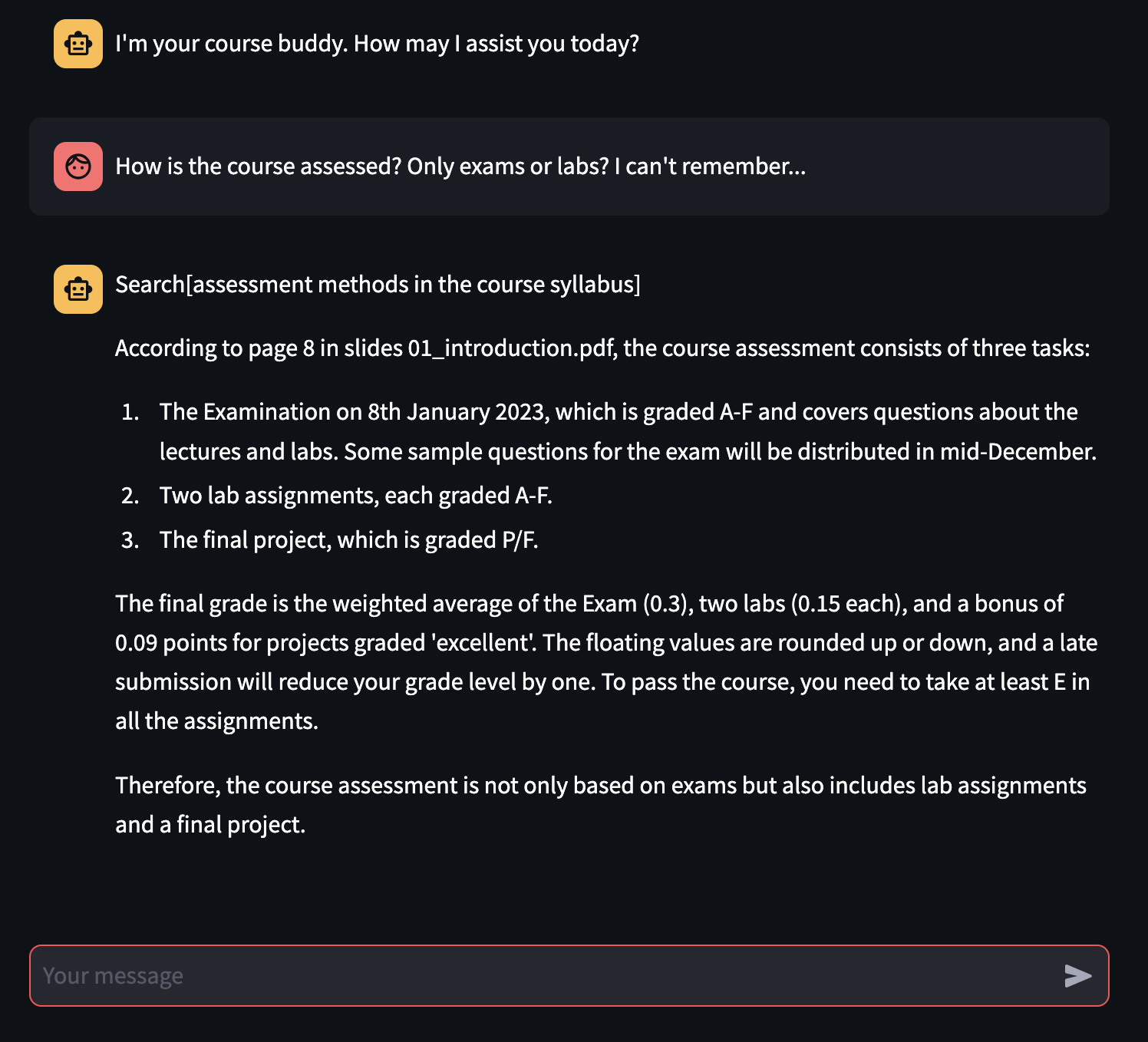
機能パイプラインが担当しています。
機能パイプラインを実行するには、いくつかのオプションがあります。
FeaturePipeline/Reading.ipynbノートブックを実行しますFeaturePipeline/FeaturePipeline.pyを使用してpython3 FeaturePipeline/FeaturePipeline.pyを実行します後者のコピーは、Modal [run | deploy] FeaturePipeline/FeaturePipeline_modal.pyを使用してモーダルホスティングサービスで実行可能にするためにmodal [run|deploy] FeaturePipeline/FeaturePipeline.pyファイルでわずかに変更されています。
トレーニングパイプラインは次の担当です。
トレーニングパイプラインを実行するには、ノートブックTrainingPipeline/FineTuning.ipynbを実行します
推論パイプラインは以下を担当しています
推論パイプラインを実行するには、 streamlit run chatbot_app.pyを実行します
実験的には、微調整プロセスは、ファインチューニングされていないモデルよりも一貫して基礎モデルを優れたものにするのに十分ではありませんが、Rag対応のチャットボットは、元の素材に従ってユーザーの質問に正しく答えることができるだけでなく、(ほとんど)回答がどこから取られているか、大学の試験を勉強するための本質的な機能を(ほとんど)正しい参照を与えることもできます。
微調整は、使用されている材料の不足と計算リソースのために意図されたものではありません。将来の仕事として、知識抽出プロセスを改善し、より多くの計算能力を使用して、レポートに示されている問題に対処したいと考えています。


