resume intelligence
1.0.0
Retomar a pesquisa usando consultas naturais. Aplicação de demonstração usando o OpenAI RAG API e o OpenSource VLM Model para retomar a análise comparativa.
Isso ajudaria os parceiros de talentos e gerentes de engenharia a obter informações específicas do currículo.
O objetivo do currículo inteligência seria apoiar a consulta de linguagem natural em um conjunto de currículos. Pode ser usado para fazer uma análise comparativa de currículos. Digamos que temos 4 ou 5 currículos de possíveis engenheiros de software algumas das consultas, que devem permitir que você dispare
Neste experimento, você precisa de currículos.
Em vez de procurar dados da Internet, usei a API Chagpt para gerar um currículo.
Eu usei a chamada de função do OpenAI e saída de resposta estruturada para obter a saída JSON.
Depois de ter o JSON, você pode convertê -lo no documento de currículo em PDF.
OPENAI_KEY=<substitute your key>
# Install python packages locally.
pip install -r requirements.txt
python ui_gen_resume.py Este exemplo pode ser executado na máquina/laptop Windows local. Ele não possui requisitos especiais em termos de GPU, você precisa selecionar 2 currículos no aplicativo da interface do usuário, digite a consulta na caixa Prompt.
e pressionar o envio.
O usuário precisa digitar na tecla OpenAI no arquivo .env que está presente na raiz da pasta.
Exemplo de arquivo .env
OPENAI_KEY= <openai key>
vector_store_resume=resume_compare
MODEL=gpt-4o-2024-11-20
# individual file is put into vector store if value is FALSE
CONCAT_PDF=False
# instruction for assistant is chosen based on this. Possible values ( individual_pdf|concat_pdf)
INSTRUCTION_ID=individual_pdf
# Path where generated pdf resumes are stored.
RESUME_PATH=.\resumes
python ui_resume_compare_multi.py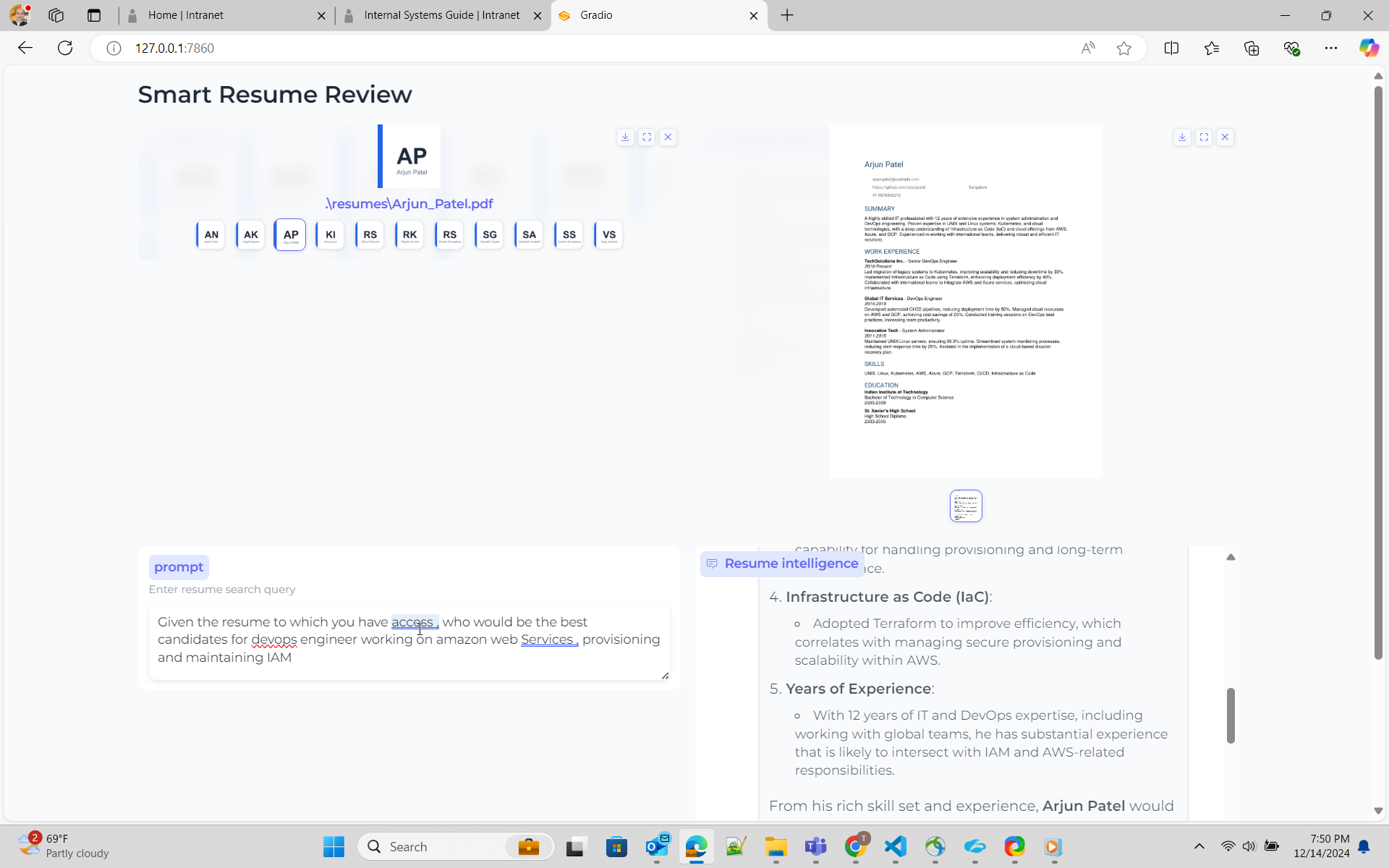
Aqui eu uso abordagens de pano
RAG - com o OpenAIAI Openi possui API Assistant, que tem opção de armazenar a representação vetorial do documento e pesquisar contra o mesmo. Consulte AQUI PARA A PESQUISA DE ARQUIVOS DE DOCUMEBRAÇÃO sobre como usar a API de pesquisa de arquivos, eu encaminhei o excelente blog e a essência de Simon Wilson, ele fez o código de exemplo
RAG - Com o OpenSource Colpali, essa é a abordagem do uso do VLM. Planejo usar Byaldi que usa internamente o Colpali, consulte o Notebook, que tem um bate -papo de código de amostra com PDF usando Byaldi ainda não estou para implementar isso.
Esta é uma abordagem direta. Eu uso as APIs OpenAI para criar uma loja de vetores e adicionar todos os documentos em PDF à loja de vetores. Post que crie um assistente e anexe o Vector Store ao Assistente
A pesquisa de arquivos do OpenAI, parece não estar funcionando bem em experimentos anteriores, para consultas que estão tocando em vários documentos. A solução inicial parece concatenar os arquivos e fazer upload no Vector Store. No entanto, isso foi um entendimento incorreto sobre como apresentar instruções para modelar
Para melhorar a resposta, isso significa com avicução que, as instruções ou o prompt do sistema devem ser ajustados para que você obtenha resultados corretos. Aqui está o meu e estou implorando o modelo para fazer a pesquisa correta.
You are dilligent assistant specializing in analyzing resume for technology industry . Your goal is to find the a individual resume closely matched per the requirement from user
1. ** location of resume ** - Vector store has resume of individual candidates . Name of the vector store is resume_compare .
2 ** format of resume ** - Vector store has resume of individual candidates in pdf format. Name of the pdf would be firstname followed by underscore last name . E.g Rajesh_Kumar.pdf
3 ** vector store** - Vector store resume_compare belongs to the user/owner, whose is calling the api
4 ** role descriptions** - For job role description such as engineering manager , devops engineer , software engineer , use your knowledge based gained from pre-training.
5 ** Resume Search Strategy** - Search across ALL documents in vector store .Consider partial matches across multiple documents .Use multiple search queries for different aspects (skills, experience, etc.)
6 ** Search Depth ** - Perform multiple searches with varied keywords. Use both exact and semantic matching.
7 ** Result Aggregation ** - Combine result from multiple searches . Cross-reference finding across documents.
8 ** key qualitifications ** - For finding key qualifications or experiences for role/work , use your knowledge base and pre-training.
9 ** resume search** - For Candidates's resume and their capability ,skills , experience for a role/work , you must use file_search tool and attached vector store. Resume will always be present in vector store.
10 ** resume presence** - Resume will always present in vector store attached to assistant . Do not prompt to ask user on resume.
11 ** Dillgence ** - Please search dilligently . you seem to miss the fact that resume files are present in vectore store resume_compare.
12 ** Technical Skills** - In the resume take a deep look at work experience section .Focus on relevant programming languages, frameworks, tools, and certifications (e.g., Python, Java, AWS, Docker). Highlight these clearly.
13. ** Job Match** - Compare the resume with provided job descriptions. Focus on matching key technologies ,business and opetational knowledge and job experience, and note areas where the candidate doesn’t meet the requirements.
14. ** Projects & Experience** - Prioritize large-scale projects or leadership roles in tech teams. Identify open-source contributions or significant technical achievements.


