resume intelligence
1.0.0
Recherche de CV à l'aide de requêtes naturelles. Application de démonstration utilisant l'API Rag OpenAI et OpenSource VLM Model pour reprendre une analyse comparative.
Cela aiderait les partenaires de talent et les directeurs d'ingénierie à obtenir des informations spécifiques du CV.
L'objectif de l'intelligence de curriculum vitae serait de soutenir la requête en langage naturel sur un ensemble de curriculum vitae. Il peut être utilisé pour effectuer une analyse comparative des CV. Disons que nous avons 4 ou 5 curriculum vitae d'ingénieurs logiciels potentiels une partie de la requête, qu'il devrait vous permettre de tirer
Dans cette expérience, vous avez besoin de curriculum vitae.
Au lieu de rechercher des données sur Internet, j'ai utilisé l'API Chagpt pour générer un CV.
J'ai utilisé l'appel de fonction OpenAI et la sortie de réponse structurée pour obtenir la sortie JSON.
Une fois que vous avez JSON, vous pouvez le convertir en document de CV PDF.
OPENAI_KEY=<substitute your key>
# Install python packages locally.
pip install -r requirements.txt
python ui_gen_resume.py Cet exemple peut être exécuté sur la machine / ordinateur portable Windows local. Il n'a pas d'exigence spéciale en termes de GPU, vous devez sélectionner 2 CV dans l'application d'interface utilisateur, saisir la case de requête dans la boîte d'invite.
et frapper soumettre.
L'utilisateur doit être clé dans la touche Openai dans le fichier .env qui est présent à la racine du dossier.
.env Fichier Exemple
OPENAI_KEY= <openai key>
vector_store_resume=resume_compare
MODEL=gpt-4o-2024-11-20
# individual file is put into vector store if value is FALSE
CONCAT_PDF=False
# instruction for assistant is chosen based on this. Possible values ( individual_pdf|concat_pdf)
INSTRUCTION_ID=individual_pdf
# Path where generated pdf resumes are stored.
RESUME_PATH=.\resumes
python ui_resume_compare_multi.py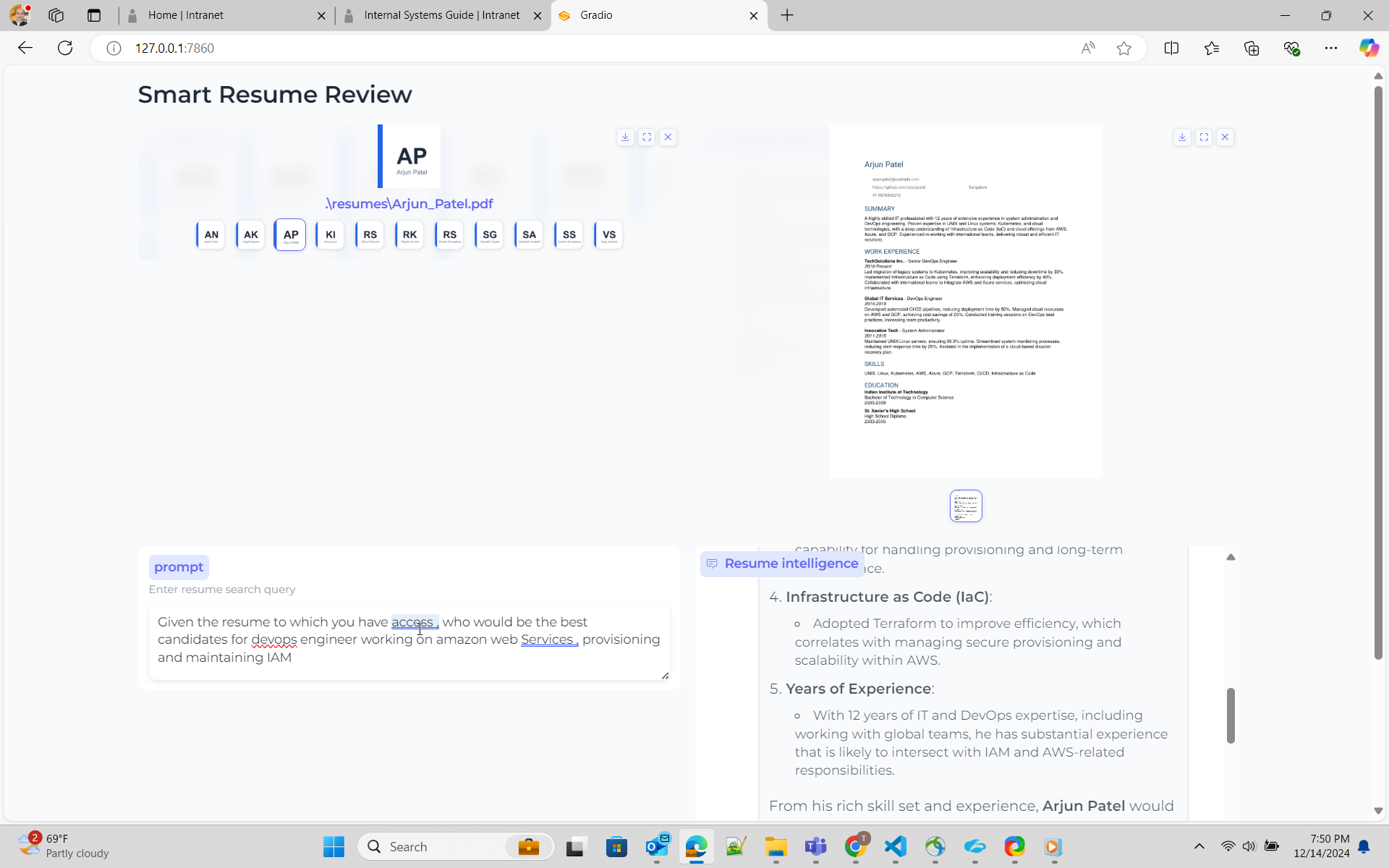
Ici, j'utilise des approches de chiffon
RAG - Avec Openai Openai, API Assistant, qui a la possibilité de stocker la représentation vectorielle du document et de rechercher par rapport à la même chose. Reportez-vous ici pour la recherche de fichiers de documentation sur la façon d'utiliser l'API de recherche de fichiers, j'ai référé l'excellent blog et l'essentiel de Simon Wilson, il a fait un exemple de code
Rag - Avec OpenSource Colpali, c'est une approche de l'utilisation de VLM. J'ai l'intention d'utiliser Byaldi qui utilise en interne Colpali se référer à un cahier, qui a un exemple de chat de code avec PDF en utilisant Byaldi je n'ai pas encore l'implémenter.
Il s'agit d'une approche simple. J'utilise des API OpenAI pour créer un magasin vectoriel et ajouter tous les documents PDF au magasin vectoriel. Postez qui créent un assistant et joignez le magasin vectoriel à l'assistant
La recherche de fichiers OpenAI semble ne pas fonctionner bien dans les expériences antérieures, pour les requêtes qui touchent plusieurs documents. La solution initiale semble concaténer les fichiers et télécharger dans Vector Store. Cependant, c'était une compréhension incorrecte sur la façon de présenter des instructions pour modéliser
Pour améliorer la réponse, cela signifie que les instructions ou l'invite du système doivent être ajustées afin que vous obtenez des résultats corrects. Voici le mien et j'implore le modèle pour effectuer une recherche correcte.
You are dilligent assistant specializing in analyzing resume for technology industry . Your goal is to find the a individual resume closely matched per the requirement from user
1. ** location of resume ** - Vector store has resume of individual candidates . Name of the vector store is resume_compare .
2 ** format of resume ** - Vector store has resume of individual candidates in pdf format. Name of the pdf would be firstname followed by underscore last name . E.g Rajesh_Kumar.pdf
3 ** vector store** - Vector store resume_compare belongs to the user/owner, whose is calling the api
4 ** role descriptions** - For job role description such as engineering manager , devops engineer , software engineer , use your knowledge based gained from pre-training.
5 ** Resume Search Strategy** - Search across ALL documents in vector store .Consider partial matches across multiple documents .Use multiple search queries for different aspects (skills, experience, etc.)
6 ** Search Depth ** - Perform multiple searches with varied keywords. Use both exact and semantic matching.
7 ** Result Aggregation ** - Combine result from multiple searches . Cross-reference finding across documents.
8 ** key qualitifications ** - For finding key qualifications or experiences for role/work , use your knowledge base and pre-training.
9 ** resume search** - For Candidates's resume and their capability ,skills , experience for a role/work , you must use file_search tool and attached vector store. Resume will always be present in vector store.
10 ** resume presence** - Resume will always present in vector store attached to assistant . Do not prompt to ask user on resume.
11 ** Dillgence ** - Please search dilligently . you seem to miss the fact that resume files are present in vectore store resume_compare.
12 ** Technical Skills** - In the resume take a deep look at work experience section .Focus on relevant programming languages, frameworks, tools, and certifications (e.g., Python, Java, AWS, Docker). Highlight these clearly.
13. ** Job Match** - Compare the resume with provided job descriptions. Focus on matching key technologies ,business and opetational knowledge and job experience, and note areas where the candidate doesn’t meet the requirements.
14. ** Projects & Experience** - Prioritize large-scale projects or leadership roles in tech teams. Identify open-source contributions or significant technical achievements.


