resume intelligence
1.0.0
Wiederaufnahme der Suche mit natürlichen Abfragen. Demo -Anwendung mit OpenAI -RAG -API und OpenSource -VLM -Modell, um die vergleichende Analyse wieder aufzunehmen.
Dies würde Talentpartnern und technischen Managern helfen, spezifische Informationen aus dem Lebenslauf zu erhalten.
Das Ziel der Intelligenz des Lebenslaufs wäre es, natürliche Sprachabfrage in einer Reihe von Lebensläufen zu unterstützen. Es kann verwendet werden, um eine vergleichende Analyse von Lebensläufen durchzuführen. Nehmen wir an, wir haben 4 oder 5 Lebensläufe von prospektiven Software -Ingenieuren in einigen Abfragen, die es Ihnen ermöglichen sollten, zu feuern
In diesem Experiment benötigen Sie Lebensläufe.
Anstatt nach Daten aus dem Internet zu suchen, habe ich Chagpt -API verwendet, um einen Lebenslauf zu generieren.
Ich habe den OpenAI -Funktionsaufruf und die strukturierte Antwortausgabe verwendet, um JSON -Ausgabe zu erhalten.
Sobald Sie JSON haben, können Sie es in das PDF -Lebenslauf -Dokument umwandeln.
OPENAI_KEY=<substitute your key>
# Install python packages locally.
pip install -r requirements.txt
python ui_gen_resume.py Dieses Beispiel kann auf lokalem Windows -Computer/Laptop ausgeführt werden. Es hat keine besondere Anforderungen an GPU. Sie müssen 2 Lebensläufe aus der UI -Anwendung auswählen und die Abfrage im Eingabeaufforderung eingeben.
und Treffer einreichen.
Der Benutzer muss in OpenAI -Schlüssel in .Env -Datei einschlüpfen, die im Stamm des Ordners vorhanden ist.
.Env -Datei Beispiel
OPENAI_KEY= <openai key>
vector_store_resume=resume_compare
MODEL=gpt-4o-2024-11-20
# individual file is put into vector store if value is FALSE
CONCAT_PDF=False
# instruction for assistant is chosen based on this. Possible values ( individual_pdf|concat_pdf)
INSTRUCTION_ID=individual_pdf
# Path where generated pdf resumes are stored.
RESUME_PATH=.\resumes
python ui_resume_compare_multi.py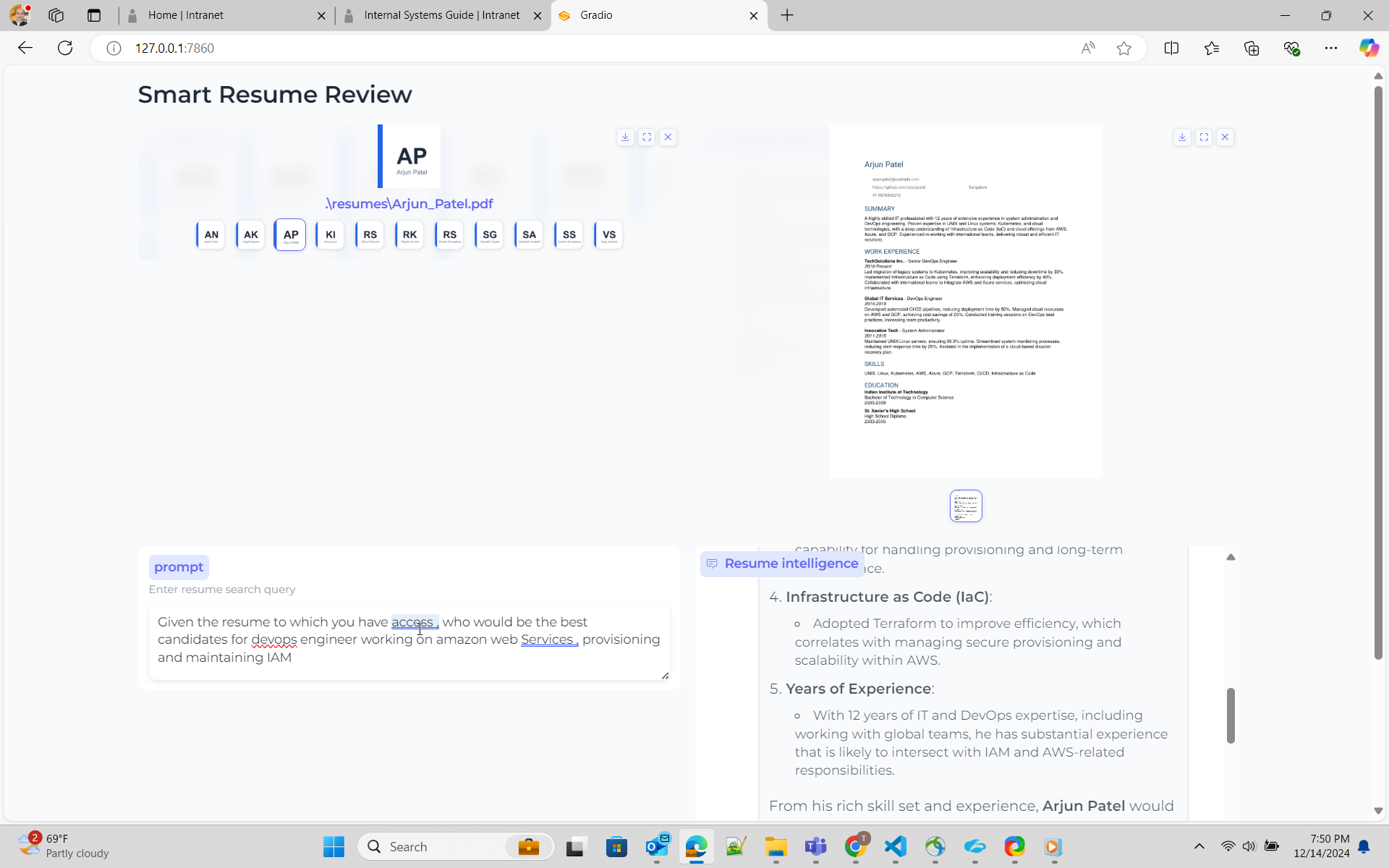
Hier benutze ich Lappenansätze
RAG - Mit OpenAI OpenAI hat Assistant API, die die Möglichkeit hat, die Vektordarstellung von Dokument zu speichern und gegen dasselbe zu suchen. Weitere Informationen zum Dokumentationsdatei -Such zur Verwendung von Dateiensuche -API finden
RAG - Mit OpenSource Colpali ist dies der Ansatz der Verwendung von VLM. Ich habe vor, BYALDI zu verwenden, das Colpali intern verwendet, wobei ein Beispielcode -Chat mit PDF mit Byaldi verwendet wird. Ich muss dies noch nicht implementieren.
Dies ist ein unkomplizierter Ansatz. Ich benutze OpenAI -APIs, um einen Vektorspeicher zu erstellen und alle PDF -Dokumente in den Vektorspeicher hinzuzufügen. Veröffentlichen Sie, die einen Assistenten erstellen und den Vektor Store an Assistant anhängen
OpenAI -Dateisuche, scheint in früheren Experimenten nicht gut zu funktionieren, für Abfragen, die mehrere Dokumente berühren. Die erste Lösung scheint die Dateien zu verkettet und im Vektorspeicher hochzuladen. Dies war jedoch ein falsches Verständnis dafür, wie Anweisungen zum Modellieren vorgestellt werden können
Um die Antwort zu verbessern, bedeutet dies, dass Anweisungen oder Systemaufforderungen angepasst werden müssen, damit Sie korrekte Ergebnisse erzielen. Hier ist meins und ich flehte das Modell an, korrekte Suche durchzuführen.
You are dilligent assistant specializing in analyzing resume for technology industry . Your goal is to find the a individual resume closely matched per the requirement from user
1. ** location of resume ** - Vector store has resume of individual candidates . Name of the vector store is resume_compare .
2 ** format of resume ** - Vector store has resume of individual candidates in pdf format. Name of the pdf would be firstname followed by underscore last name . E.g Rajesh_Kumar.pdf
3 ** vector store** - Vector store resume_compare belongs to the user/owner, whose is calling the api
4 ** role descriptions** - For job role description such as engineering manager , devops engineer , software engineer , use your knowledge based gained from pre-training.
5 ** Resume Search Strategy** - Search across ALL documents in vector store .Consider partial matches across multiple documents .Use multiple search queries for different aspects (skills, experience, etc.)
6 ** Search Depth ** - Perform multiple searches with varied keywords. Use both exact and semantic matching.
7 ** Result Aggregation ** - Combine result from multiple searches . Cross-reference finding across documents.
8 ** key qualitifications ** - For finding key qualifications or experiences for role/work , use your knowledge base and pre-training.
9 ** resume search** - For Candidates's resume and their capability ,skills , experience for a role/work , you must use file_search tool and attached vector store. Resume will always be present in vector store.
10 ** resume presence** - Resume will always present in vector store attached to assistant . Do not prompt to ask user on resume.
11 ** Dillgence ** - Please search dilligently . you seem to miss the fact that resume files are present in vectore store resume_compare.
12 ** Technical Skills** - In the resume take a deep look at work experience section .Focus on relevant programming languages, frameworks, tools, and certifications (e.g., Python, Java, AWS, Docker). Highlight these clearly.
13. ** Job Match** - Compare the resume with provided job descriptions. Focus on matching key technologies ,business and opetational knowledge and job experience, and note areas where the candidate doesn’t meet the requirements.
14. ** Projects & Experience** - Prioritize large-scale projects or leadership roles in tech teams. Identify open-source contributions or significant technical achievements.


