RobustLR
1.0.0
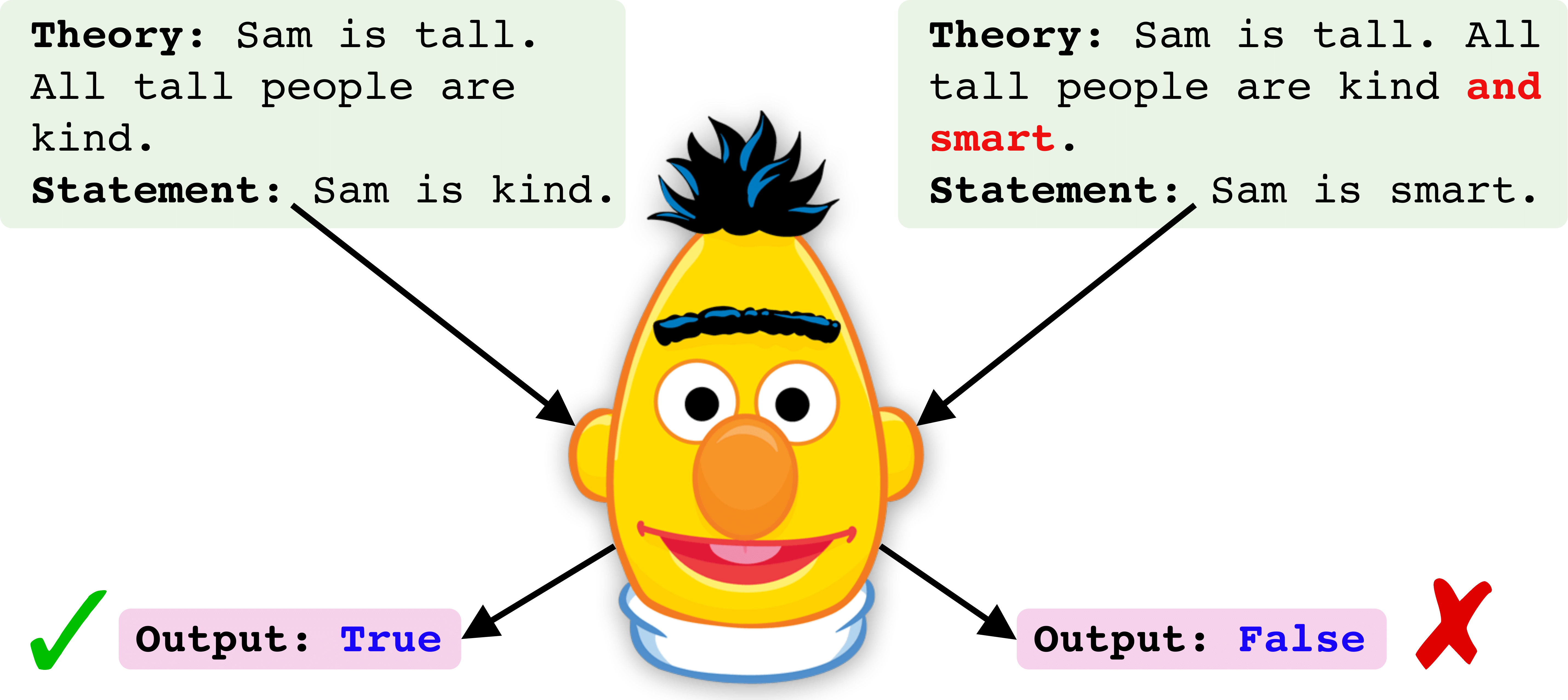
requirements.txt 사용하여 종속성을 설치할 수 있습니다.data 라는 폴더에서 다운로드하십시오.saved 의 폴더에 검사 점을 저장합니다.아래에는 Roberta 체크 포인트를 훈련시키고 평가하기위한 단계별 파이프 라인을 보여줍니다. 예제는 기차 시간에 모든 논리 연산자가 포함 된 'All'교육 데이터 세트에 대해 표시됩니다 [및 OR, OR, NOT.
python process_dataset.py --dataset train_data/all --arch roberta_large_race
우리는 레이스에서 미세한 Roberta Checkpoint를 사용합니다. 모델은 src/configs/config.yaml 에서 구성을 통해 변경할 수 있습니다
python main.py --dataset all --train_dataset all --dev_dataset all --test_dataset all
아래 명령에서 <model_ckpt> 위의 모델 결제에서 저장된 체크 포인트 경로로 바꾸십시오.
python process_dataset.py --dataset robustlr/logical_contrast/conj_contrast_with_distractors --eval
python main.py --override evaluate --dataset conj_contrast_with_distractors --train_dataset conj_contrast_with_distractors --dev_dataset conj_contrast_with_distractors --test_dataset conj_contrast_with_distractors --ckpt_path <model_ckpt>
python process_dataset.py --dataset robustlr/logical_contrast/disj_contrast_with_distractors --eval
python main.py --override evaluate --dataset disj_contrast_with_distractors --train_dataset disj_contrast_with_distractors --dev_dataset disj_contrast_with_distractors --test_dataset disj_contrast_with_distractors --ckpt_path <model_ckpt>
python process_dataset.py --dataset robustlr/logical_contrast/neg_contrast_with_distractors --eval
python main.py --override evaluate --dataset neg_contrast_with_distractors --train_dataset neg_contrast_with_distractors --dev_dataset neg_contrast_with_distractors --test_dataset neg_contrast_with_distractors --ckpt_path <model_ckpt>
python process_dataset.py --dataset robustlr/logical_equivalence/contrapositive_equiv --eval
python main.py --override evaluate --dataset contrapositive_equiv --train_dataset contrapositive_equiv --dev_dataset contrapositive_equiv --test_dataset contrapositive_equiv --ckpt_path <model_ckpt>
python process_dataset.py --dataset robustlr/logical_equivalence/distributive1_equiv --eval
python main.py --override evaluate --dataset distributive1_equiv --train_dataset distributive1_equiv --dev_dataset distributive1_equiv --test_dataset distributive1_equiv --ckpt_path <model_ckpt>
python process_dataset.py --dataset robustlr/logical_equivalence/distributive2_equiv --eval
python main.py --override evaluate --dataset distributive2_equiv --train_dataset distributive2_equiv --dev_dataset distributive2_equiv --test_dataset distributive2_equiv --ckpt_path <model_ckpt>
설명, 의견 또는 제안은 문제를 만들거나 Soumya에 문의하십시오.


