RobustLR
1.0.0
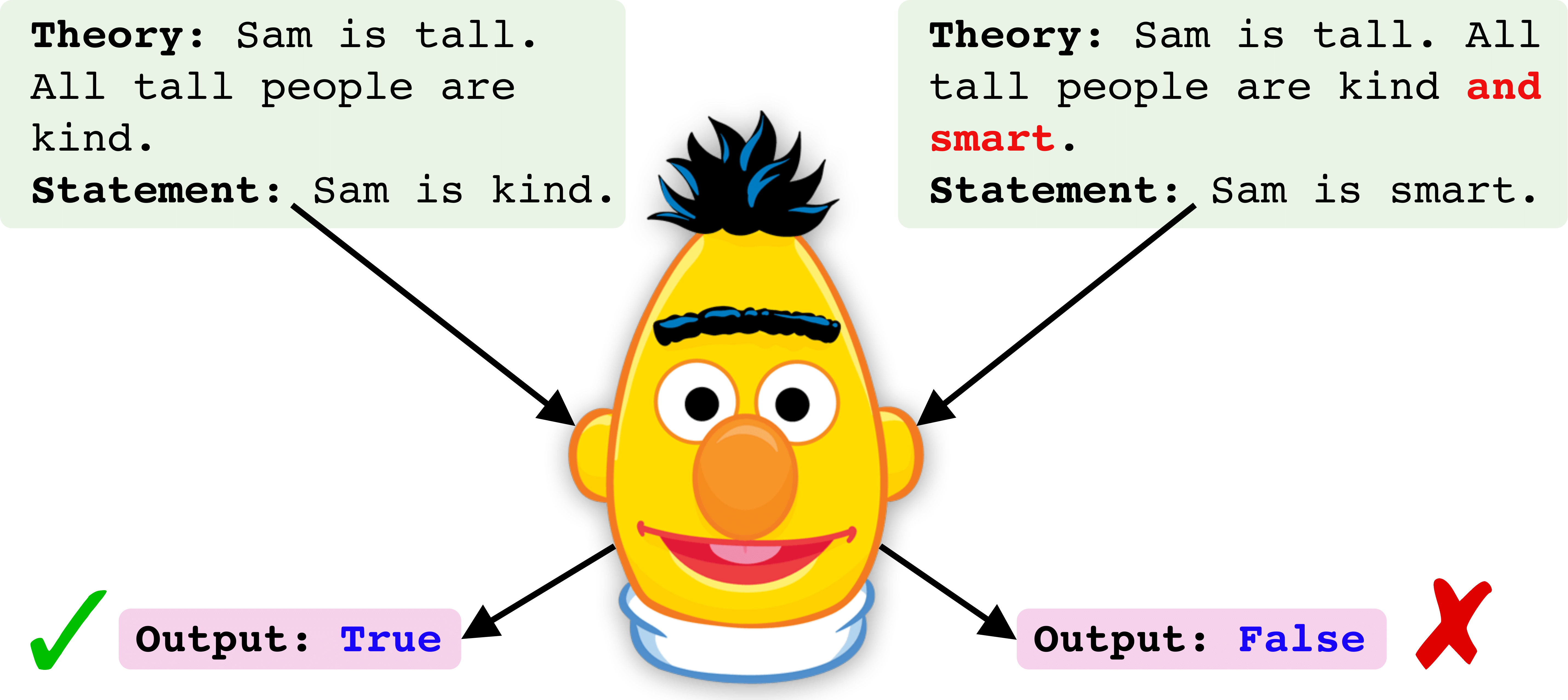
requirements.txtを使用してインストールできます。dataという名前のフォルダーにダウンロードします。savedフォルダーのチェックポイントが保存されます以下に、Robertaのチェックポイントを訓練および評価するための段階的なピプレラインを示します。この例は、列車時にすべての論理演算子を含む「ALL」トレーニングデータセットの[および、またはそうではない]に示されています。
python process_dataset.py --dataset train_data/all --arch roberta_large_race
レースでFinetunedのRobertaチェックポイントを使用しています。モデルはsrc/configs/config.yamlでconfigを介して変更できます
python main.py --dataset all --train_dataset all --dev_dataset all --test_dataset all
以下のコマンドの<model_ckpt>を、上記のモデルFinetuningから保存されたチェックポイントパスに置き換えます。
python process_dataset.py --dataset robustlr/logical_contrast/conj_contrast_with_distractors --eval
python main.py --override evaluate --dataset conj_contrast_with_distractors --train_dataset conj_contrast_with_distractors --dev_dataset conj_contrast_with_distractors --test_dataset conj_contrast_with_distractors --ckpt_path <model_ckpt>
python process_dataset.py --dataset robustlr/logical_contrast/disj_contrast_with_distractors --eval
python main.py --override evaluate --dataset disj_contrast_with_distractors --train_dataset disj_contrast_with_distractors --dev_dataset disj_contrast_with_distractors --test_dataset disj_contrast_with_distractors --ckpt_path <model_ckpt>
python process_dataset.py --dataset robustlr/logical_contrast/neg_contrast_with_distractors --eval
python main.py --override evaluate --dataset neg_contrast_with_distractors --train_dataset neg_contrast_with_distractors --dev_dataset neg_contrast_with_distractors --test_dataset neg_contrast_with_distractors --ckpt_path <model_ckpt>
python process_dataset.py --dataset robustlr/logical_equivalence/contrapositive_equiv --eval
python main.py --override evaluate --dataset contrapositive_equiv --train_dataset contrapositive_equiv --dev_dataset contrapositive_equiv --test_dataset contrapositive_equiv --ckpt_path <model_ckpt>
python process_dataset.py --dataset robustlr/logical_equivalence/distributive1_equiv --eval
python main.py --override evaluate --dataset distributive1_equiv --train_dataset distributive1_equiv --dev_dataset distributive1_equiv --test_dataset distributive1_equiv --ckpt_path <model_ckpt>
python process_dataset.py --dataset robustlr/logical_equivalence/distributive2_equiv --eval
python main.py --override evaluate --dataset distributive2_equiv --train_dataset distributive2_equiv --dev_dataset distributive2_equiv --test_dataset distributive2_equiv --ckpt_path <model_ckpt>
明確化、コメント、または提案については、問題を作成するか、Soumyaに連絡してください。


