RobustLR
1.0.0
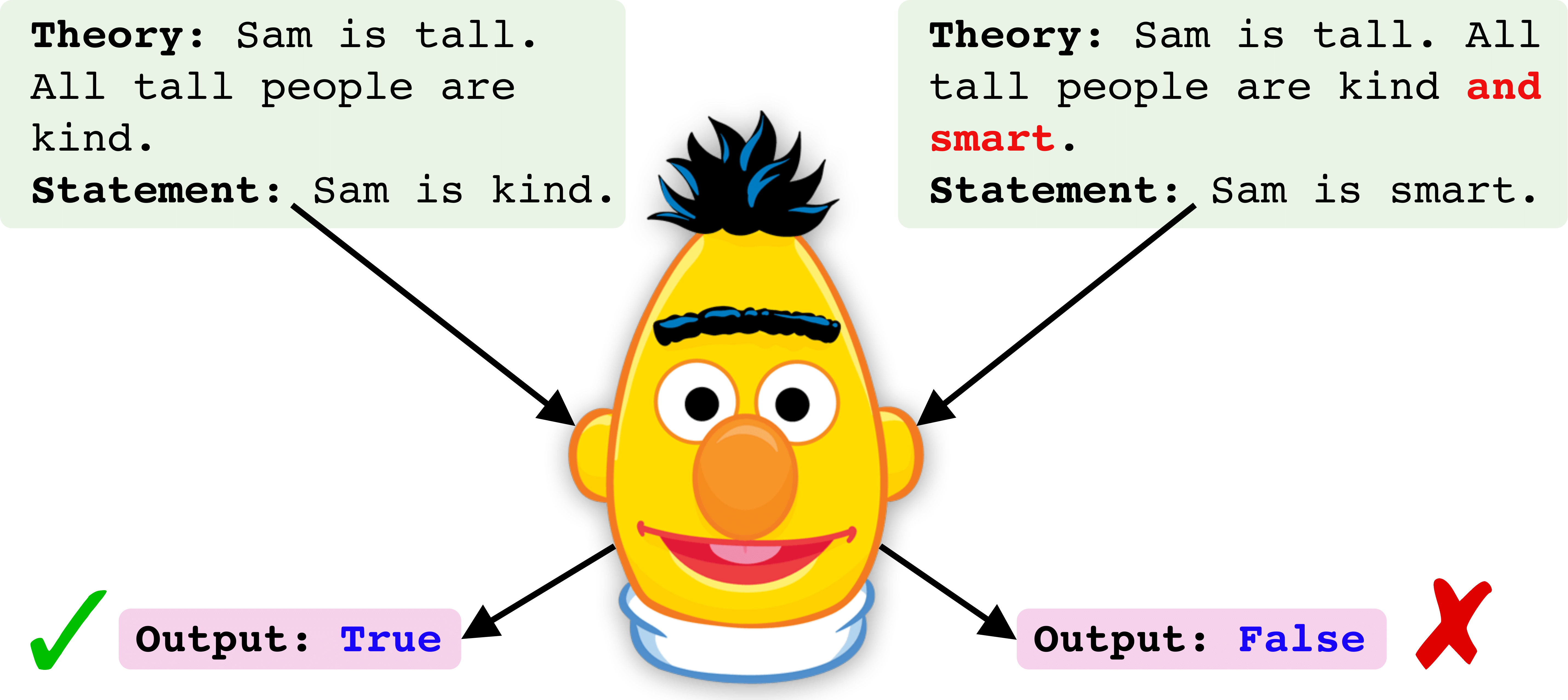
requirements.txt installiert werden.txt.data herunter.savedIm Folgenden zeigen wir eine Schritt-für-Schritt-Pipleline, um einen Roberta-Checkpoint zu trainieren und zu bewerten. Das Beispiel wird für den "All' -Trainingsdatensatz" angezeigt, der alle logischen Operatoren zur Zugzeit enthält [und oder, nicht].
python process_dataset.py --dataset train_data/all --arch roberta_large_race
Wir verwenden einen Roberta -Checkpoint, der beim Rennen beendet ist. Das Modell kann über config unter src/configs/config.yaml geändert werden
python main.py --dataset all --train_dataset all --dev_dataset all --test_dataset all
Ersetzen Sie den Befehl <model_ckpt> in dem folgenden Befehl in den oben ausgeführten Speicherspfad in den Sparen -Checkpoint -Pfad.
python process_dataset.py --dataset robustlr/logical_contrast/conj_contrast_with_distractors --eval
python main.py --override evaluate --dataset conj_contrast_with_distractors --train_dataset conj_contrast_with_distractors --dev_dataset conj_contrast_with_distractors --test_dataset conj_contrast_with_distractors --ckpt_path <model_ckpt>
python process_dataset.py --dataset robustlr/logical_contrast/disj_contrast_with_distractors --eval
python main.py --override evaluate --dataset disj_contrast_with_distractors --train_dataset disj_contrast_with_distractors --dev_dataset disj_contrast_with_distractors --test_dataset disj_contrast_with_distractors --ckpt_path <model_ckpt>
python process_dataset.py --dataset robustlr/logical_contrast/neg_contrast_with_distractors --eval
python main.py --override evaluate --dataset neg_contrast_with_distractors --train_dataset neg_contrast_with_distractors --dev_dataset neg_contrast_with_distractors --test_dataset neg_contrast_with_distractors --ckpt_path <model_ckpt>
python process_dataset.py --dataset robustlr/logical_equivalence/contrapositive_equiv --eval
python main.py --override evaluate --dataset contrapositive_equiv --train_dataset contrapositive_equiv --dev_dataset contrapositive_equiv --test_dataset contrapositive_equiv --ckpt_path <model_ckpt>
python process_dataset.py --dataset robustlr/logical_equivalence/distributive1_equiv --eval
python main.py --override evaluate --dataset distributive1_equiv --train_dataset distributive1_equiv --dev_dataset distributive1_equiv --test_dataset distributive1_equiv --ckpt_path <model_ckpt>
python process_dataset.py --dataset robustlr/logical_equivalence/distributive2_equiv --eval
python main.py --override evaluate --dataset distributive2_equiv --train_dataset distributive2_equiv --dev_dataset distributive2_equiv --test_dataset distributive2_equiv --ckpt_path <model_ckpt>
Für Klärung, Kommentare oder Vorschläge erstellen Sie bitte ein Problem oder wenden Sie sich an Soumya.


