RobustLR
1.0.0
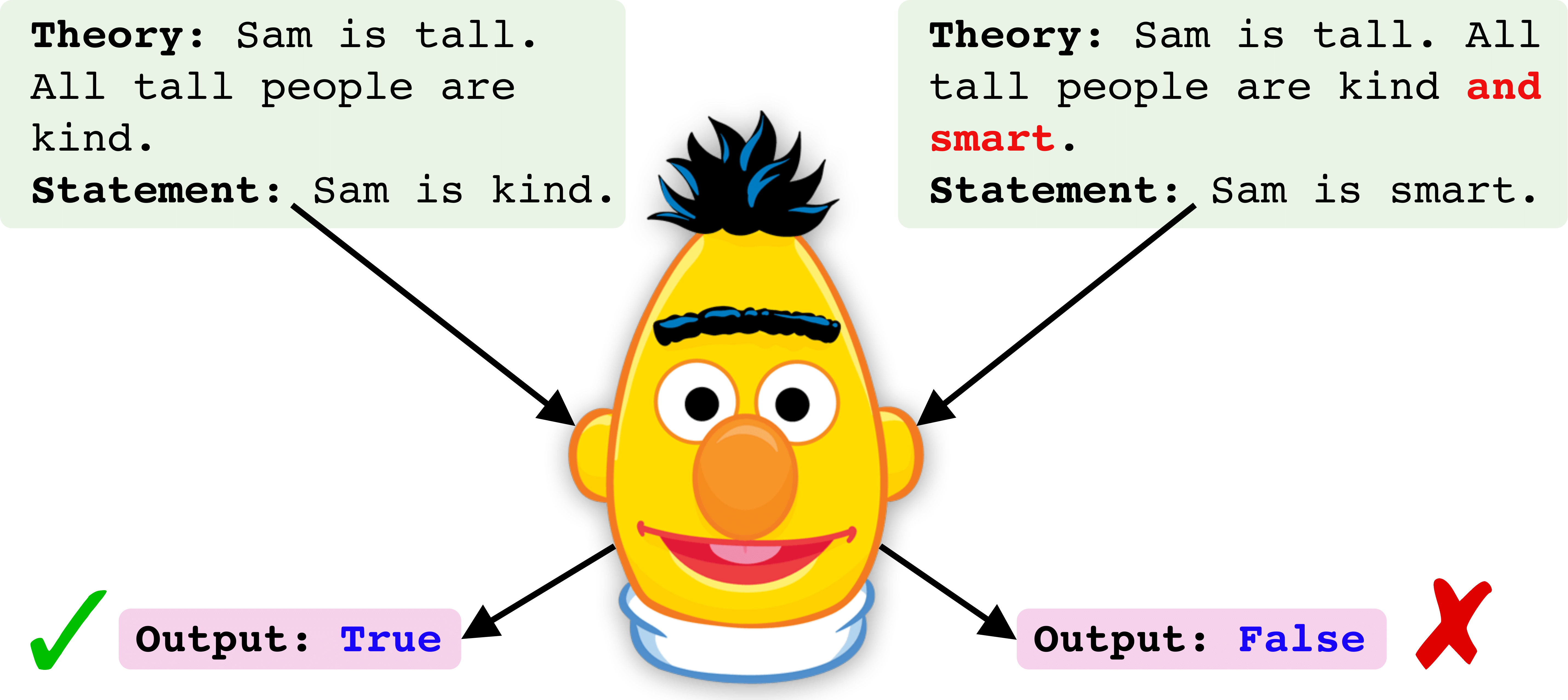
requirements.txt .data .savedA continuación, mostramos un Pipline paso a paso para entrenar y evaluar un punto de control de Roberta. El ejemplo se muestra para el conjunto de datos de entrenamiento `All` que contiene todos los operadores lógicos en el tiempo de tren [y, o no].
python process_dataset.py --dataset train_data/all --arch roberta_large_race
Usamos un punto de control de Roberta Finetened en la carrera. El modelo se puede cambiar a través de la configuración en src/configs/config.yaml
python main.py --dataset all --train_dataset all --dev_dataset all --test_dataset all
Reemplace el comando <model_ckpt> en el siguiente comando a la ruta de punto de control guardada desde el modelo de fineco realizado anteriormente.
python process_dataset.py --dataset robustlr/logical_contrast/conj_contrast_with_distractors --eval
python main.py --override evaluate --dataset conj_contrast_with_distractors --train_dataset conj_contrast_with_distractors --dev_dataset conj_contrast_with_distractors --test_dataset conj_contrast_with_distractors --ckpt_path <model_ckpt>
python process_dataset.py --dataset robustlr/logical_contrast/disj_contrast_with_distractors --eval
python main.py --override evaluate --dataset disj_contrast_with_distractors --train_dataset disj_contrast_with_distractors --dev_dataset disj_contrast_with_distractors --test_dataset disj_contrast_with_distractors --ckpt_path <model_ckpt>
python process_dataset.py --dataset robustlr/logical_contrast/neg_contrast_with_distractors --eval
python main.py --override evaluate --dataset neg_contrast_with_distractors --train_dataset neg_contrast_with_distractors --dev_dataset neg_contrast_with_distractors --test_dataset neg_contrast_with_distractors --ckpt_path <model_ckpt>
python process_dataset.py --dataset robustlr/logical_equivalence/contrapositive_equiv --eval
python main.py --override evaluate --dataset contrapositive_equiv --train_dataset contrapositive_equiv --dev_dataset contrapositive_equiv --test_dataset contrapositive_equiv --ckpt_path <model_ckpt>
python process_dataset.py --dataset robustlr/logical_equivalence/distributive1_equiv --eval
python main.py --override evaluate --dataset distributive1_equiv --train_dataset distributive1_equiv --dev_dataset distributive1_equiv --test_dataset distributive1_equiv --ckpt_path <model_ckpt>
python process_dataset.py --dataset robustlr/logical_equivalence/distributive2_equiv --eval
python main.py --override evaluate --dataset distributive2_equiv --train_dataset distributive2_equiv --dev_dataset distributive2_equiv --test_dataset distributive2_equiv --ckpt_path <model_ckpt>
Para cualquier aclaración, comentario o sugerencia, cree un problema o comuníquese con Soumya.


