RobustLR
1.0.0
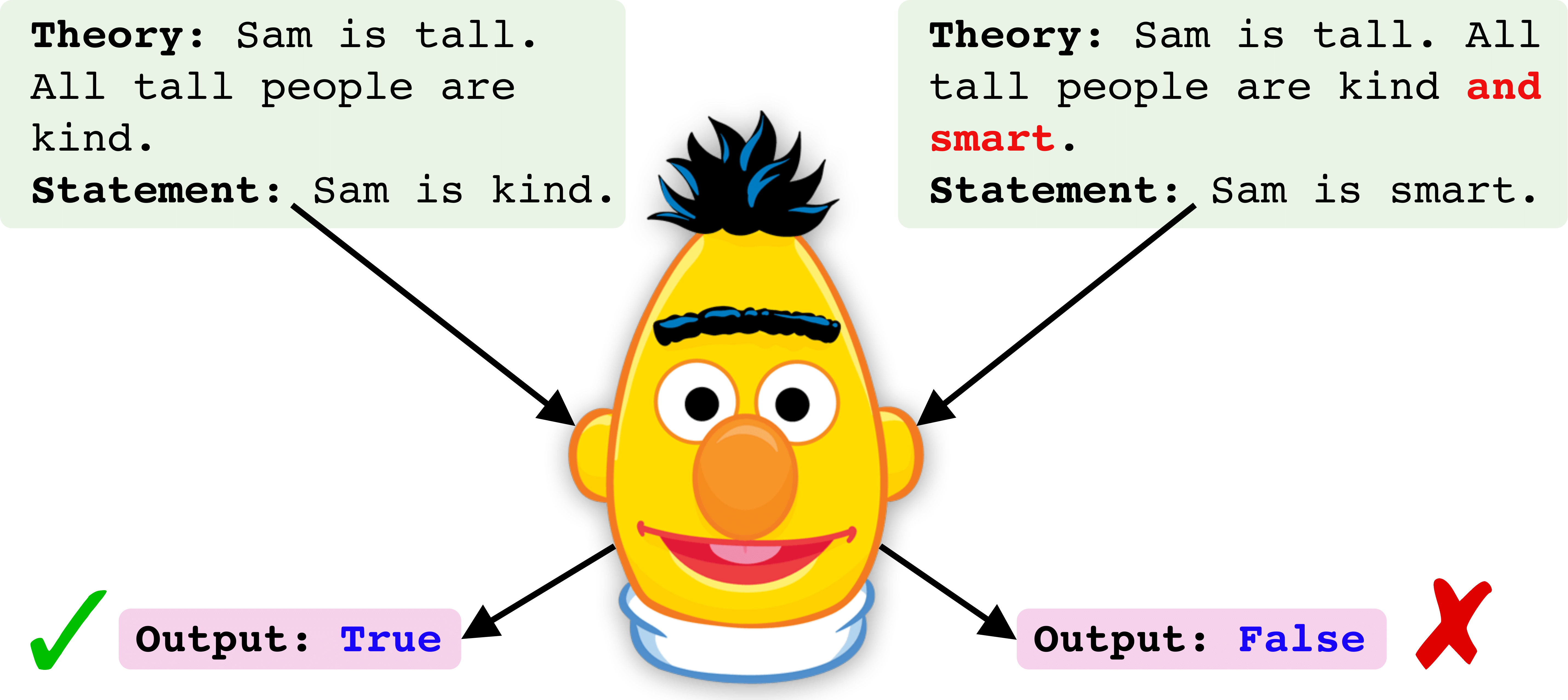
requirements.txt .data .savedCi-dessous, nous montrons un pipleline étape par étape pour entraîner et évaluer un point de contrôle Roberta. L'exemple est indiqué pour l'ensemble de données de formation `All 'qui contient tous les opérateurs logiques à l'heure du train [et, ou non].
python process_dataset.py --dataset train_data/all --arch roberta_large_race
Nous utilisons un point de contrôle Roberta Finetuned sur la course. Le modèle peut être modifié via la configuration à src/configs/config.yaml
python main.py --dataset all --train_dataset all --dev_dataset all --test_dataset all
Remplacez la commande <model_ckpt> dans le chemin de contrôle enregistré du modèle de point de contrôle enregistré du modèle Finetuning effectué ci-dessus.
python process_dataset.py --dataset robustlr/logical_contrast/conj_contrast_with_distractors --eval
python main.py --override evaluate --dataset conj_contrast_with_distractors --train_dataset conj_contrast_with_distractors --dev_dataset conj_contrast_with_distractors --test_dataset conj_contrast_with_distractors --ckpt_path <model_ckpt>
python process_dataset.py --dataset robustlr/logical_contrast/disj_contrast_with_distractors --eval
python main.py --override evaluate --dataset disj_contrast_with_distractors --train_dataset disj_contrast_with_distractors --dev_dataset disj_contrast_with_distractors --test_dataset disj_contrast_with_distractors --ckpt_path <model_ckpt>
python process_dataset.py --dataset robustlr/logical_contrast/neg_contrast_with_distractors --eval
python main.py --override evaluate --dataset neg_contrast_with_distractors --train_dataset neg_contrast_with_distractors --dev_dataset neg_contrast_with_distractors --test_dataset neg_contrast_with_distractors --ckpt_path <model_ckpt>
python process_dataset.py --dataset robustlr/logical_equivalence/contrapositive_equiv --eval
python main.py --override evaluate --dataset contrapositive_equiv --train_dataset contrapositive_equiv --dev_dataset contrapositive_equiv --test_dataset contrapositive_equiv --ckpt_path <model_ckpt>
python process_dataset.py --dataset robustlr/logical_equivalence/distributive1_equiv --eval
python main.py --override evaluate --dataset distributive1_equiv --train_dataset distributive1_equiv --dev_dataset distributive1_equiv --test_dataset distributive1_equiv --ckpt_path <model_ckpt>
python process_dataset.py --dataset robustlr/logical_equivalence/distributive2_equiv --eval
python main.py --override evaluate --dataset distributive2_equiv --train_dataset distributive2_equiv --dev_dataset distributive2_equiv --test_dataset distributive2_equiv --ckpt_path <model_ckpt>
Pour toute clarification, commentaires ou suggestions, veuillez créer un problème ou contacter Soumya.


