torchsde
v0.2.6
このライブラリは、GPUサポートと効率的なバックプロパゲーションを備えた確率微分方程式(SDE)ソルバーを提供します。
pip install torchsde要件: python> = 3.8およびpytorch> = 1.6.0。
こちらから入手できます。
import torch
import torchsde
batch_size , state_size , brownian_size = 32 , 3 , 2
t_size = 20
class SDE ( torch . nn . Module ):
noise_type = 'general'
sde_type = 'ito'
def __init__ ( self ):
super (). __init__ ()
self . mu = torch . nn . Linear ( state_size ,
state_size )
self . sigma = torch . nn . Linear ( state_size ,
state_size * brownian_size )
# Drift
def f ( self , t , y ):
return self . mu ( y ) # shape (batch_size, state_size)
# Diffusion
def g ( self , t , y ):
return self . sigma ( y ). view ( batch_size ,
state_size ,
brownian_size )
sde = SDE ()
y0 = torch . full (( batch_size , state_size ), 0.1 )
ts = torch . linspace ( 0 , 1 , t_size )
# Initial state y0, the SDE is solved over the interval [ts[0], ts[-1]].
# ys will have shape (t_size, batch_size, state_size)
ys = torchsde . sdeint ( sde , y0 , ts )examples/demo.ipynbソルバーのランダム性の修正やノイズタイプの選択などの微妙なポイントを含む、SDEの解決方法に関する短いガイドを提供します。
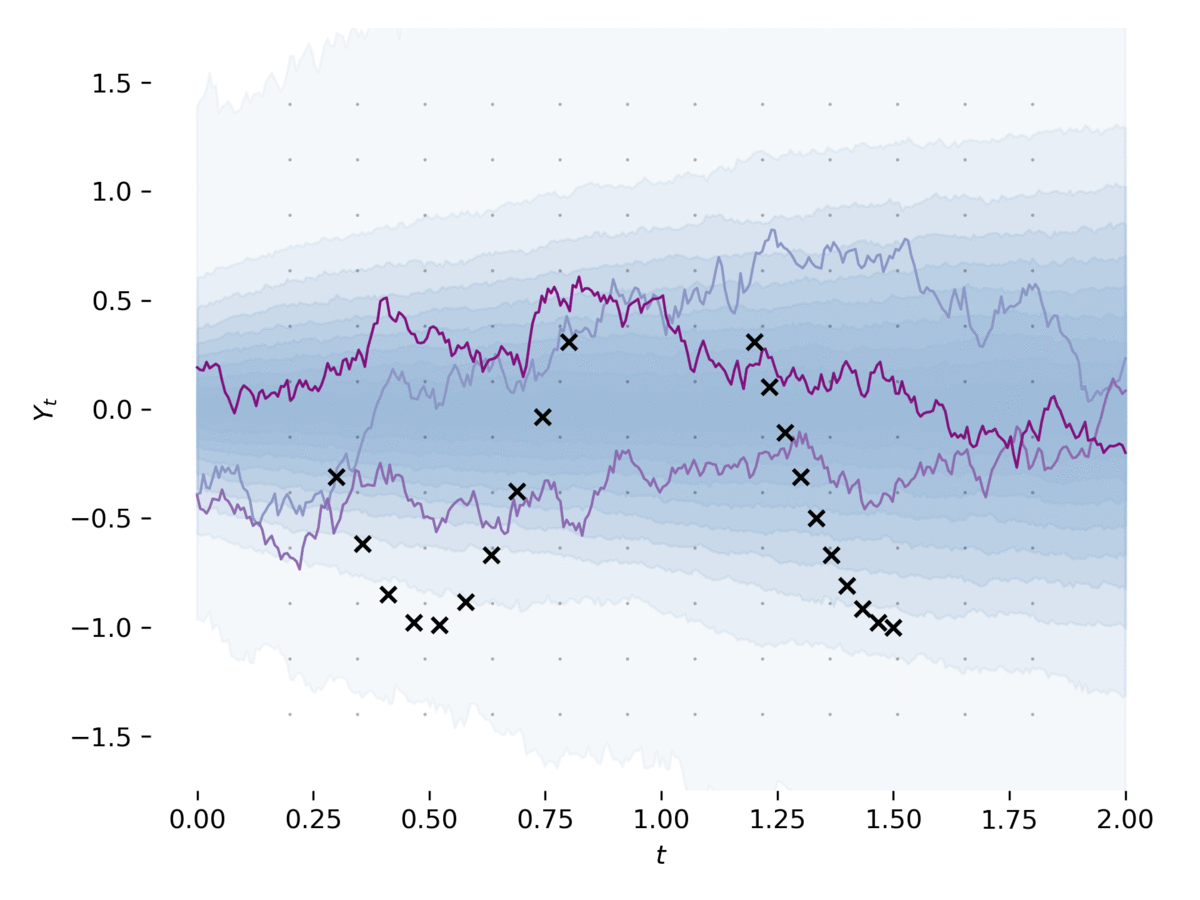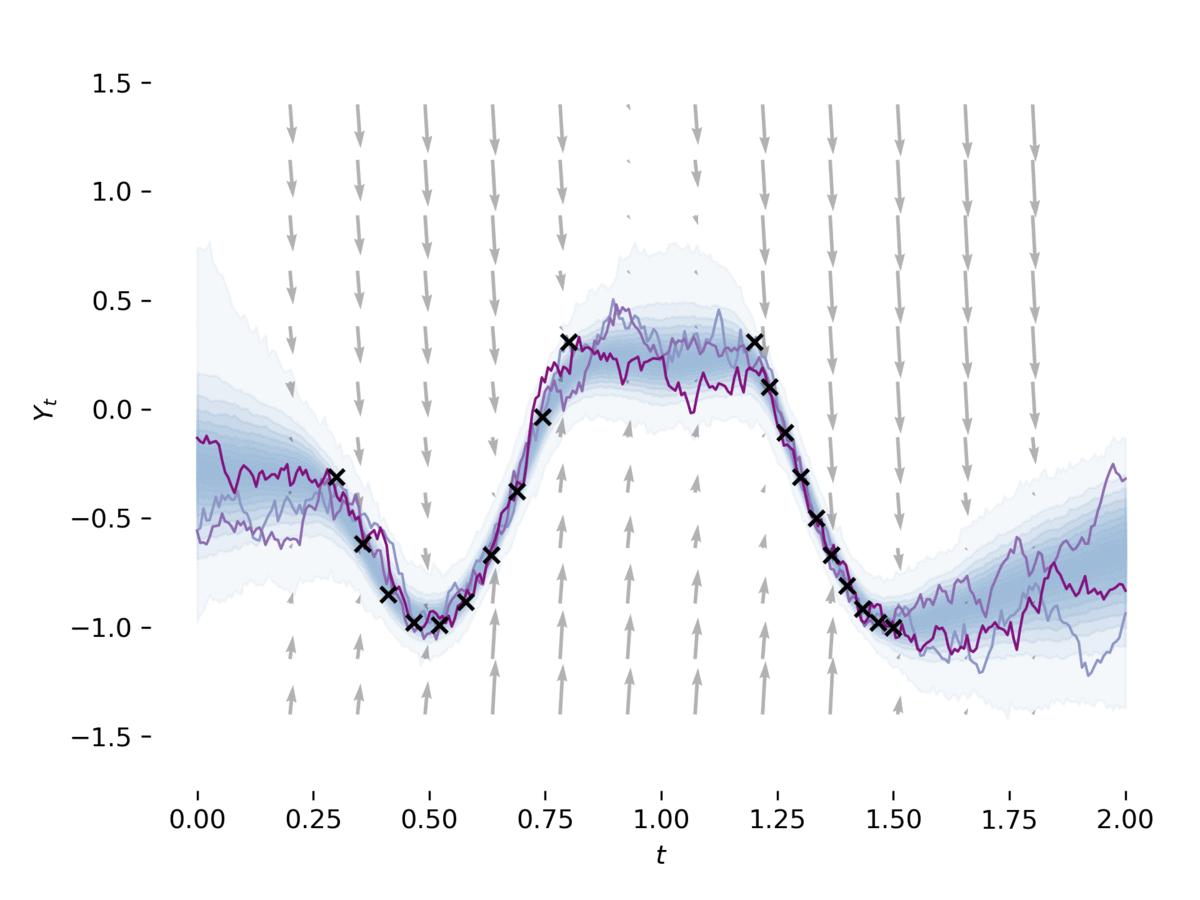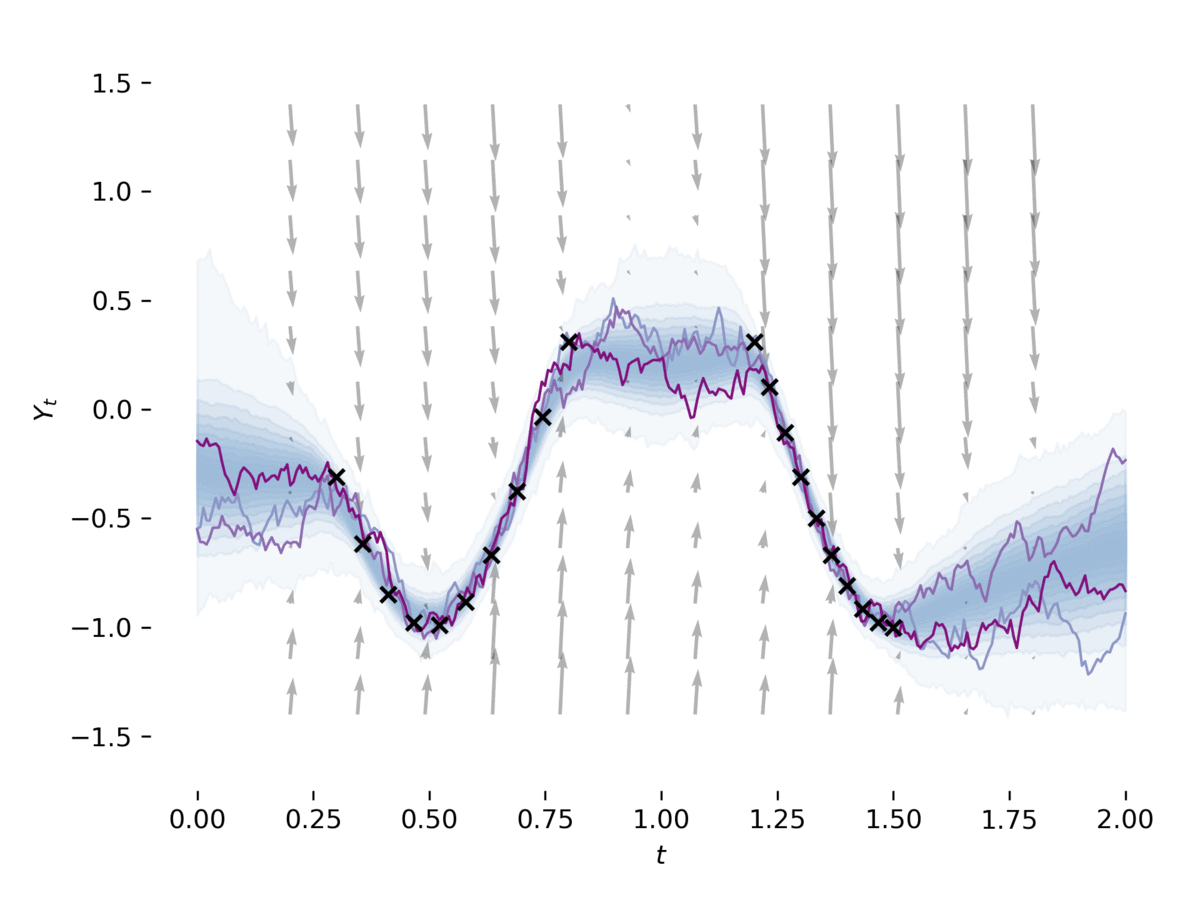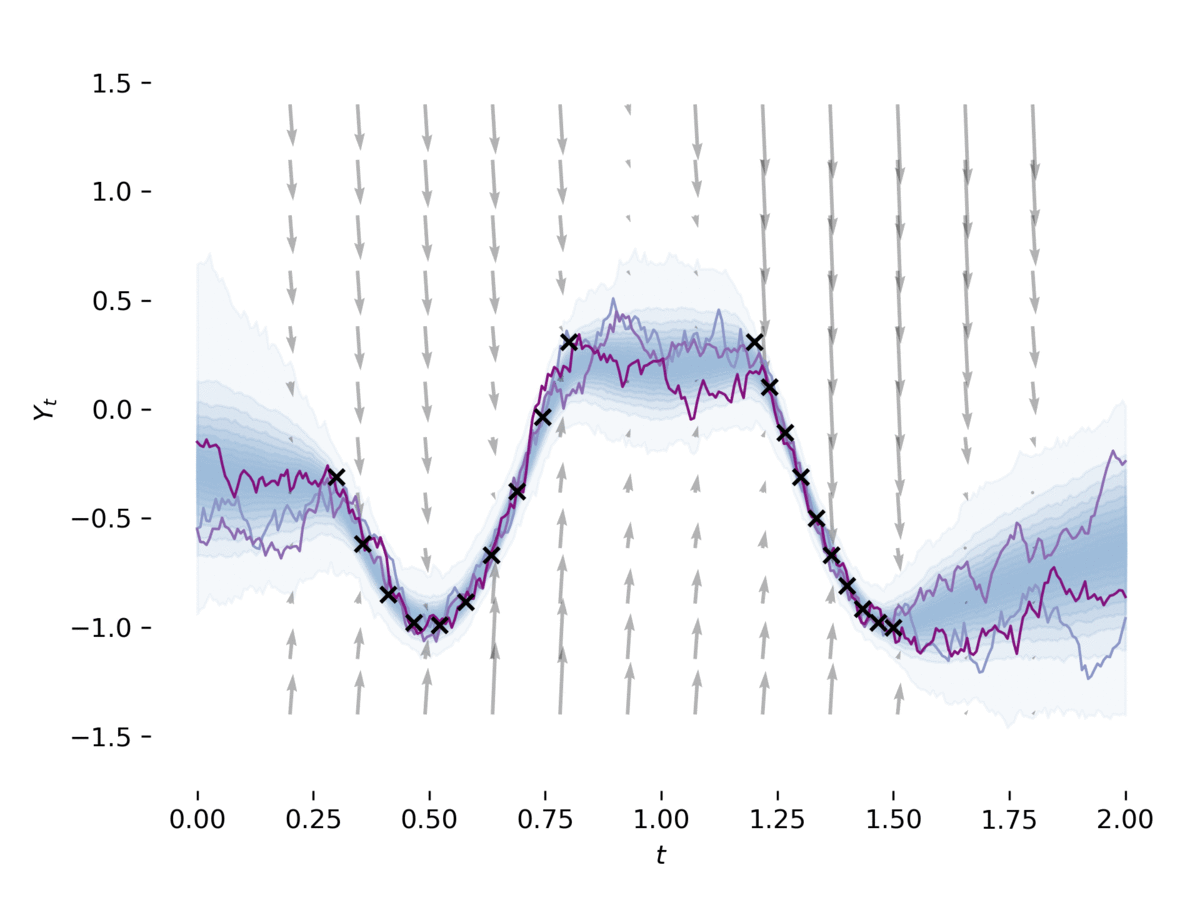
[1]のセクション5のように、 examples/latent_sde.py潜在的な確率微分方程式を学びます。この例は、SDEをデータに適合させ、それを正規化し、Ornstein-Uhlenbeckの事前プロセスのようにしています。このモデルは、以前およびおおよその後部がSDESである変分自動エンコーダーとしてゆるく見えることができます。この例は介して実行できます
python -m examples.latent_sde --train-dir < TRAIN_DIR >プログラムは、 <TRAIN_DIR>で指定されたパスに数値を出力します。トレーニングは、デフォルトのハイパーパラメーターで500回の反復後に安定する必要があります。
[2]、[3]のように、 examples/sde_gan.py sdeをganとして学習します。この例では、SDEをGANの発電機として訓練しますが、神経CDE [4]を識別因子として使用します。この例は介して実行できます
python -m examples.sde_ganこのコードベースが研究で役立つとわかった場合は、次のいずれかまたは両方を引用することを検討してください。
@article{li2020scalable,
title={Scalable gradients for stochastic differential equations},
author={Li, Xuechen and Wong, Ting-Kam Leonard and Chen, Ricky T. Q. and Duvenaud, David},
journal={International Conference on Artificial Intelligence and Statistics},
year={2020}
}
@article{kidger2021neuralsde,
title={Neural {SDE}s as {I}nfinite-{D}imensional {GAN}s},
author={Kidger, Patrick and Foster, James and Li, Xuechen and Oberhauser, Harald and Lyons, Terry},
journal={International Conference on Machine Learning},
year={2021}
}
[1] Xuechen Li、Ting-Kam Leonard Wong、Ricky TQ Chen、David Duvenaud。 「確率微分方程式のスケーラブルな勾配」。人工知能と統計に関する国際会議。 2020。[arxiv]
[2] Patrick Kidger、James Foster、Xuechen Li、Harald Oberhauser、Terry Lyons。 「無限次元のガンとしてのニューラルSDE」。機械学習に関する国際会議2021。[arxiv]
[3] Patrick Kidger、James Foster、Xuechen Li、Terry Lyons。 「神経SDEの効率的で正確な勾配」。 2021。[arxiv]
[4] Patrick Kidger、James Morrill、James Foster、Terry Lyons、「不規則な時系列の神経制御微分方程式」。神経情報処理システム2020。[arxiv]
これは、公式のGoogle製品ではなく、研究プロジェクトです。


