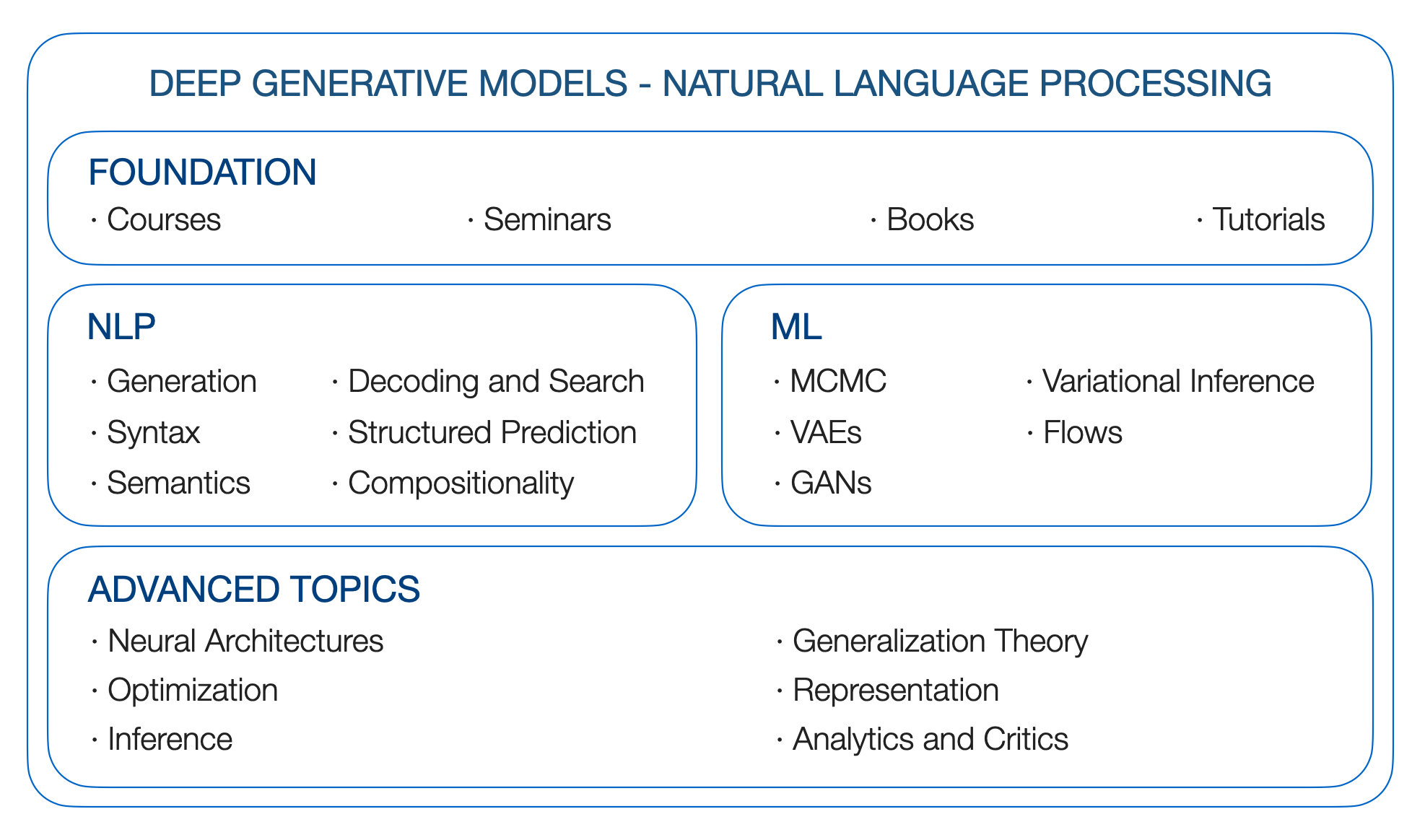
Deep Generative Models for Natural Language Processing
1.0.0

DGMS 4 NLP. Modèles génératifs profonds pour le traitement du langage naturel. Une feuille de route.
Yao Fu, Université d'Édimbourg, [email protected]
** Mise à jour **: Comment GPT obtient-il sa capacité? Tracer les capacités émergentes des modèles de langue à leurs sources
** MISE À JOUR **: Un examen plus approfondi des capacités émergentes du modèle de langue
** Mise à jour **: modèles de grande langue
** Mise à jour **: dépendance à long terme; Pourquoi S4 est bon à une longue séquence: se souvenir d'une séquence avec une approximation de la fonction en ligne
** TODO 1 **: Calibration; Inciter; Transformateurs à longue portée; Modèles d'espace d'État
** TODO 2 **: Factorisation matricielle et intégration des mots; Graines; Processus gaussien
** TODO 3 **: relation entre l'inférence et RL;
(Écrit début 2019, provenant du séminaire DGM de Columbia)
Pourquoi voulons-nous des modèles génératifs profonds? Parce que nous voulons apprendre des facteurs de base qui génèrent un langage. Le langage humain contient de riches facteurs latents, les émotions, les émotions, l'intention et autres, les facteurs discrets / structurels peuvent être des étiquettes ou des arbres de syntaxe POS / NER. Beaucoup d'entre eux sont latents comme dans la plupart des cas, nous observons simplement la phrase. Ils sont également génératifs: l'homme devrait produire un langage en fonction de l'idée globale, de l'émotion actuelle, de la syntaxe et de toutes les autres choses que nous pouvons ou ne pouvons pas nommer.
Comment modéliser le processus génératif du langage de manière statistiquement fondée sur des principes? Pouvons-nous avoir un cadre flexible qui nous permet d'incorporer des signaux de supervision explicites lorsque nous avons des étiquettes, ou d'ajouter des contraintes de supervision ou de logique / statistique à distance lorsque nous n'avons pas d'étiquettes mais que nous avons d'autres connaissances antérieures, ou simplement déduire ce qui a le plus de sens lorsque nous n'avons pas d'étiquettes ou de priori? Est-il possible que nous exploitions le pouvoir de modélisation des architectures neuronales avancées tout en étant mathématiques et probabilistes? Les SGM nous permettent d'atteindre ces objectifs.
Commençons le voyage.
Citation:
@article{yao2019DGM4NLP,
title = "Deep Generative Models for Natual Language Processing",
author = "Yao Fu",
year = "2019",
url = "https://github.com/FranxYao/Deep-Generative-Models-for-Natural-Language-Processing"
}
Comment rédiger l'inférence variationnelle et les modèles génératifs pour la PNL: une recette. Ceci est fortement suggéré aux débutants d'écriture de documents sur les VAE pour la PNL.
Un tutoriel sur les modèles de variables latentes profondes du langage naturel (lien), EMNLP 18
Modèles de structure latente pour la PNL. Lien de tutoriel ACL 2019
Columbia STAT 8201 - Modèles génératifs profonds, par John Cunningham
Stanford CS 236 - Modèles génératifs profonds, par Stefano Ermon
U Toronto CS 2541 - Inférence différenciable et modèles génératifs, CS 2547 Apprentissage des structures latentes discrètes, CSC 2547 automne 2019: Apprentissage à la recherche. Par David Duvenaud
U Toronto STA 4273 Hiver 2021 - Minimiser les attentes. Par Chris Maddison
Berkeley CS294-158 - Apprentissage non supervisé profond. Par Pieter Abbeel
Columbia STCS 8101 - Représentation Apprentissage: une perspective probabiliste. Par David Blei
Stanford CS324 - Modèles de grande langue. Par Percy Liang, Tatsunori Hashimoto et Christopher RE
U Toronto CSC2541 - Dynamique de formation neurale du neural. Par Roger Grosse.
La fondation des DGMS est construite sur des modèles graphiques probabilistes. Nous examinons donc les ressources suivantes
BLEI'S Foundation of Graphical Models Course, STAT 6701 à Columbia (Link)
Modèles graphiques probabilistes de Xing, 10-708 à CMU (lien)
Traitement du langage naturel de Collins, Coms 4995 à Columbia (lien)
Reconnaissance des modèles et apprentissage automatique. Christopher M. Bishop. 2006
Apprentissage automatique: une perspective probabiliste. Kevin P. Murphy. 2012
Modèles graphiques, familles exponentielles et inférence variationnelle. 2008
Prédiction de structure linguistique. 2011
Le processus syntaxique. 2000
Générer des phrases à partir d'un espace continu, conll 15
Inférence variationnelle neurale pour le traitement du texte, ICML 16
Apprendre des modèles neuronaux pour la génération de texte. EMNLP 2018
Modèles résiduels basés sur l'énergie pour la génération de texte. ICLR 20
Génération de paraphrase avec sac de mots latent. Neirips 2019.
Bibliothèque de décodage Fairseq. [github]
Génération de texte neuronal contrôlabel [lil'log]
Meilleure recherche de faisceau. Tacl 2020
Le cas curieux de la dégénérescence du texte neuronal. ICLR 2020
Comparaison de diverses méthodes de décodage à partir de modèles de langage conditionnel. ACL 2019
Poutres stochastiques et où les trouver: l'astuce Gumbel-top-k pour les séquences d'échantillonnage sans remplacement. ICML 19
Recherche de faisceau stochastique conditionnel de Poisson. EMNLP 2021
Décodage à échelle massive pour la génération de texte à l'aide de réseaux. 2021
Décodage limité lexicalement pour la génération de séquences en utilisant la recherche de faisceau de grille. ACL 2017
Décodage à contrainte lexicalement rapide avec allocation de faisceau dynamique pour la traduction de la machine neuronale. NAACL 2018
Amélioration du décodage limité lexicalement pour la traduction et la réécriture monolingue. NAACL 2019
Vers le décodage comme optimisation continue dans la traduction de la machine neuronale. EMNLP 2017
Génération de texte à contrainte liée à la lexicalement guidée par le gradient. EMNLP 2020
Génération de texte contrôlée comme optimisation continue avec plusieurs contraintes. 2021
Décodage neurologique: (UN) Génération de texte neuronal supervisé avec des contraintes logiques de prédicat. NAACL 2021
Décodage neurologique a * esque: génération de texte contrainte avec heuristique de lookahead. 2021
Décodage à froid: génération de texte contrainte à base d'énergie avec la dynamique de Langevin. 2022
Remarque: Je n'ai pas complètement parcouru ce chapitre, veuillez me donner des suggestions!
Traduction de machine neuronale non autorégressive. ICLR 2018
Traduction de machine neuronale entièrement non autorégressive: astuces du commerce.
Décodage rapide dans les modèles de séquence en utilisant des variables latentes discrètes. ICML 2021
Génération de texte en cascade avec Markov Transformers. Arxiv 20
Transformateur de regard pour la traduction de machine neuronale non autorégressive. ACL 2021
Todo: plus à ce sujet
Papiers rapides, thunlp (lien)
CTRL: un modèle de langue transformateur conditionnel pour la génération contrôlable. Arxiv 2019
Modèles de langage plug et jouent: une approche simple de la génération de texte contrôlée
Torche-structure: bibliothèque de prédiction structurée profonde. github, papier, documentation
Une introduction aux champs aléatoires conditionnels. 2012
Les algorithmes à l'intérieur et à l'avant-arrière ne sont que du rétroprop. 2016.
Apprendre avec des pertes Fenchel-Young. JMLR 2019
Réseaux d'attention structurés. ICLR 2017
Programmation dynamique différenciable pour la prédiction et l'attention structurées. ICML 2018
Grammaires de réseau neuronal récurrentes. Naacl 16
Grammaires de réseau neuronal récurrent non surveillé, NAACL 19
Différenciable Perturb-and-Parse: analyse semi-supervisée avec un autoencoder variationnel structuré, ICLR 19
Le processus syntaxique. 2020
Auto-agence d'auto-atténuation linguistique pour l'étiquetage des rôles sémantiques. EMNLP 2018 Best Paper Award
Analyse sémantique avec des autoencobeurs séquentiels semi-supervisés. 2016
Généralisation de la composition dans la PNL. Liste de papier
Généralisation sans systématicité: sur les compétences de composition des réseaux récurrents de séquence à séquence. ICML 2019
Amélioration de la méthodologie d'évaluation du texte à SQL. ACL 2018
Inférence probabiliste en utilisant les méthodes de la chaîne de Markov Monte Carlo. 1993
Éléments de Monte Carlo séquentiel (lien)
Une introduction conceptuelle à Hamiltonian Monte Carlo (Link)
Échantillonnage des candidats (lien)
Estimation contrastive du bruit: un nouveau principe d'estimation pour les modèles statistiques non normalisés. Aistata 2010
Un * échantillonnage. NIPS 2014 Meilleur papier
Cambridge Variational Inference Reading Group (Link)
Inférence variationnelle: revue pour les statisticiens.
Inférence variationnelle stochastique
Inférence bayésienne variationnelle avec la recherche stochastique. ICML 12
Bayes variationnel en codage automatique, ICLR 14
Beta-Vae: Apprentissage des concepts visuels de base avec un cadre variationnel contraint. ICLR 2017
Importance Autoencoders pondérés. ICLR 2015
Rétropropagation stochastique et inférence approximative dans les modèles génératifs profonds. ICML 14
Autoencoders variationnels semi-amortis, ICML 18
Autoencoders adversarialement régularisés, ICML 18
En savoir plus sur la réparamétrisation: pour réparminer le mélange gaussien, la matrice de permutation et les échantillonneurs de rejet (gamma et dirichlet).
Rétropropagation stochastique à travers les distributions de densité de mélange, arxiv 16
Gradient de réparamétrisation à travers des algorithmes d'échantillonnage d'acceptation-rejet. Aistats 2017
Gradients de réparamétrisation implicites. Neirips 2018.
Réparamétrisation catégorique avec Gumbel-SoftMax. ICLR 2017
La distribution du béton: une relaxation continue de variables aléatoires discrètes. ICLR 2017
Réparamétrisation gaussienne inversible: revisiter le Gumbel-SoftMax. 2020
Échantillonnage de sous-ensemble réparamétrable via des relaxations continues. IJCAI 2019
Réseaux adversaires génératifs, NIPS 14
Vers des méthodes de principe de formation des réseaux adversaires génératifs, ICLR 2017
Wasserstein Gan
Infogan: Représentation interprétable Apprentissage par des informations maximisant les réseaux adversaires génératifs. NIPS 2016
A appris adversarialement l'inférence. ICLR 2017
Modèles génératifs profonds basés sur le flux, du journal de Lil
Inférence variationnelle avec les flux de normalisation, ICML 15
Apprendre la langue avec des flux de normalisation
Amélioration de l'inférence variationnelle avec le flux autorégressif inverse
Estimation de la densité utilisant un NVP réel. ICLR 17
Apprentissage non supervisé de la structure syntaxique avec projections neuronales inversibles. EMNLP 2018
Déplats de normalisation latente pour les séquences discrètes. ICML 2019.
Écoulements discrets: modèles génératifs inversibles de données discrètes. 2019
FlowSeq: génération de séquence conditionnelle non autorégressive avec flux génératif. EMNLP 2019
Traduction de machine neurale variationnelle avec des flux de normalisation. ACL 2020
Sur les incorporations de phrases à partir de modèles de langue pré-formés. EMNLP 2020
FY: Besoin de voir comment les modèles génératifs basés sur les scores et les modèles de diffusion peuvent être utilisés pour des séquences discrètes
Modélisation générative en estimant les gradients de la distribution des données. Blog 2021
Documents de modélisation générative basés sur le score
Modélisation générative en estimant les gradients de la distribution des données. Neirips 2019
Que sont les modèles de diffusion? 2021
Modèle de diffusion génial
Apprentissage non supervisé profond à l'aide d'une thermodynamique sans équilibre. 2015
Modèles probabilistes de diffusion de débrassement. Neirips 2020
Flux Argmax et diffusion multinomiale: distribution catégorique d'apprentissage. Neirips 2021
Modèles de diffusion structurés dans le débrotage dans les espaces d'états discrets. Neirips 2021
Modèles de diffusion autorégressifs. ICLR 2022
La diffusion-LM améliore la génération de texte contrôlable. 2022
Modèles de diffusion de texte à image photoréaliste avec une compréhension profonde du langage. 2022
Neurones ordonnés: intégrer l'arbre structuré dans des réseaux de neurones récurrents
Les RNN peuvent générer des langues hiérarchiques bordées avec une mémoire optimale
Analyse de l'auto-atténuer de la tête: les têtes spécialisées font le levage de lourds, le reste peut être taillé. ACL 2019
Limites théoriques de l'auto-attention dans les modèles de séquence neuronale. TACL 2019
Repenser l'attention avec les artistes. 2020
Thunlp: Liste de papier du modèle de langage pré-formé (lien)
Documents liés à Bert de Tomohide Shibata
Hippo: mémoire récurrente avec projections polynomiales optimales. Neirips 2020
Combinant des modèles récurrents, convolutionnels et à temps continu avec la couche d'espace d'état linéaire. Neirips 2021
Modélisation efficace de longues séquences avec des espaces d'état structurés. ICLR 2022
Pourquoi S4 est bon en longue séquence: se souvenir d'une séquence avec une approximation de la fonction en ligne. 2022
GPT3 (175b). Les modèles de langue sont des apprenants à quelques tirs. Mai 2020
NLG Megatron-Suring (530b). Utilisation de Deeppeed et Megatron pour entraîner le mégatron NLG 530b, un modèle de langage génératif à grande échelle. Janvier 2022
Lamda (137b). LAMDA: Modèles de langue pour les applications de dialogue. Janvier 2022
Gopher (280b). Modèles de langage d'échelle: méthodes, analyse et perspectives de la formation Gopher. Déc. 2021
Chinchilla (70b). Formation des modèles de grand langage calculiers. Mars 2022
Palme (540b). PAMPE: Échelle de la modélisation du langage avec des voies. Avril 2022
Opt (175b). OPT: Ouvrez les modèles de langage transformateur pré-formé. Mai 2022
Bloom (176b): BigScience Large-Science Open-Access Multantial Langual Model. Mai 2022
Blenderbot 3 (175b): un agent conversationnel déployé qui apprend continuellement à s'engager de manière responsable. Août 2022
Échec des lois pour les modèles de langage neuronal. 2020
Capacités émergentes des modèles de grande langue. 2022
Minimiser les attentes. Chris Maddison
Estimation du gradient de Monte Carlo dans l'apprentissage automatique
Inférence variationnelle pour les objectifs de Monte Carlo. ICML 16
Rearn: Estimations de gradient à faible variation et non biaisée pour les modèles variables latentes discrets. Nips 17
Rétro-propagation à travers le vide: l'optimisation du contrôle variait pour l'estimation du gradient de la boîte noire. ICLR 18
En rétablissement à travers Argmax structuré à l'aide d'un robinet. ACL 2018 Meilleure mention honorable du papier.
Comprendre la mécanique du robinet: gradients de substitution pour l'apprentissage de la structure latente. EMNLP 2020
Apprendre avec des optimisateurs perturbés différenciables. Neirips 2020
Estimation du gradient avec astuces stochastiques softmax. Neirips 2020
Programmation dynamique différenciable pour la prédiction et l'attention structurées. ICML 18
Optimisation stochastique des réseaux de tri via des relaxations continues
Classement différenciable et tri en utilisant un transport optimal
Réparamètre le polytope Birkhoff pour l'inférence de permutation variationnelle. Aistates 2018
Un cadre régularisé pour une attention neuronale clairsemée et structurée. Neirips 2017
SPARSEMAP: inférence structurée clairsemée différenciable. ICML 2018
Reconnaissance de l'entité nommée imbriquée avec des TreECRFS partiellement observés. AAAI 2021
Gradients stochastiques Blackwellized Rao pour les distributions discrètes. ICML 2019.
Marginalisation efficace des variables latentes discrètes et structurées via la rareté. Neirips 2020
Régie postérieure pour les modèles de variables latentes structurées. JMLR 2010
Contrôle postérieur de la génération de la boîte noire. 2019
Induction de grammaire de dépendance avec un analyseur basé sur la transition variationnelle. AAAI 2019
(En chinois) 微分几何与拓扑学简明教程
Seuls Bayes devraient apprendre un collecteur (sur l'estimation de la structure géométrique différentielle à partir des données). Arxiv 2018
La géométrie Riemannien des modèles génératifs profonds. CVPRW 2018
La géométrie des modèles d'images génératifs profonds et ses applications. ICLR 2021
Métriques pour les modèles génératifs profonds. Aistats 2017
Algorithmes de premier ordre pour l'optimisation MIN-MAX dans les espaces métriques géodésiques. 2022
Caractéristiques aléatoires pour les machines de noyau à grande échelle. Neirips 2007
Trouver la structure avec aléatoire: algorithmes probabilistes pour construire des décompositions matricielles approximatives. Siam 2011
Optimisation efficace des boucles et des limites avec des sommes télescopiques randomisées. ICML 2019
Estimation de la densité télescopique. Neirips 2020
Processus gaussiens évolutifs sans biais via des troncations randomisées. ICML 2021
Différenciation automatique randomisée. ICLR 2021
Mise à l'échelle de l'inférence structurée avec la randomisation. 2021
Éléments de la théorie de l'information. Couverture et Thomas. 1991
Sur les limites variationnelles des informations mutuelles. ICML 2019
Apprentissage des représentations profondes par l'estimation et la maximisation des informations mutuelles. ICLR 2019
Mine: Information mutuelle Estimation neuronale
Goulot d'étranglement d'informations variationnelles en profondeur. ICLR 2017
Identification des modèles de mélange bayésien
Démassement démêlant dans les autoencodeurs variationnels. ICML 2019
Contester les hypothèses courantes dans l'apprentissage non surveillé des représentations démêlées. ICML 2019
Émergence de l'invariance et du démontage dans les représentations profondes
Minimisation des risques invariants
Fixation d'un Elbo cassé. ICML 2018.
Les limites variationnelles plus strictes ne sont pas nécessairement meilleures. ICML 2018
Le Bernoulli continu: fixer une erreur omniprésente dans les autoencodeurs variationnels. Neirips 2019
Les modèles génératifs profonds savent-ils ce qu'ils ne savent pas? ICLR 2019
Estimation efficace des modèles de langage génératif profond. ACL 2020
Quelle est la qualité de la postérieure de Bayes dans les réseaux de neurones profonds? ICML 2020
Une théorie statistique des postérieurs froids dans les réseaux de neurones profonds. ICLR 2021
Limites des modèles autorégressifs et de leurs alternatives. NAACL 2021


