Deep Generative Models for Natural Language Processing
1.0.0

DGMS 4 NLP. Modelos generativos profundos para el procesamiento del lenguaje natural. Una hoja de ruta.
Yao FU, Universidad de Edimburgo, [email protected]
** Actualización **: ¿Cómo obtiene GPT su capacidad? Trazar habilidades emergentes de modelos lingüísticos para sus fuentes
** Actualización **: Una mirada más cercana a las habilidades emergentes del modelo de idioma
** Actualización **: Modelos de Languge de gran
** Actualización **: dependencia de largo alcance; Por qué S4 es bueno en secuencia larga: recordando una secuencia con aproximación de función en línea
** TODO 1 **: Calibración; Incitación; Transformadores de largo alcance; Modelos de espacio de estado
** TODO 2 **: factorización de matriz e incrustación de palabras; Núcleos; Proceso gaussiano
** TODO 3 **: Relación entre inferencia y RL;
(Escrito a principios de 2019, originado por el seminario DGM en Columbia)
¿Por qué queremos modelos generativos profundos? Porque queremos aprender factores básicos que generen lenguaje. El lenguaje humano contiene factores latentes ricos, los continuos pueden ser emoción, intención y otros, los factores discretos/ estructurales pueden ser etiquetas POS/ NER o árboles de sintaxis. Muchos de ellos están latentes como en la mayoría de los casos, solo observamos la oración. También son generativos: el humano debe producir un lenguaje basado en la idea general, la emoción actual, la sintaxis y todas las demás cosas que podemos o no podemos nombrar.
¿Cómo modelar el proceso generativo del lenguaje de una manera estadísticamente de principios? ¿Podemos tener un marco flexible que nos permita incorporar señales de supervisión explícitas cuando tenemos etiquetas, o agregar supervisión distante o restricciones lógicas/ estadísticas cuando no tenemos etiquetas pero tenemos otro conocimiento previo, o simplemente inferen lo que tenga más sentido cuando no tenemos etiquetas o un priori? ¿Es posible que explotemos el poder de modelado de las arquitecturas neuronales avanzadas y al mismo tiempo seamos matemáticos y probabilísticos? Los DGM nos permiten lograr estos objetivos.
Comencemos el viaje.
Citación:
@article{yao2019DGM4NLP,
title = "Deep Generative Models for Natual Language Processing",
author = "Yao Fu",
year = "2019",
url = "https://github.com/FranxYao/Deep-Generative-Models-for-Natural-Language-Processing"
}
Cómo escribir inferencia variacional y modelos generativos para PNL: una receta. Esto se sugiere fuertemente para los principiantes que escriben documentos sobre VAE para PNL.
Un tutorial sobre modelos variables latentes profundos de lenguaje natural (enlace), EMNLP 18
Modelos de estructura latente para PNL. Enlace del tutorial de ACL 2019
Columbia Stat 8201 - Modelos generativos profundos, de John Cunningham
Stanford CS 236 - Modelos generativos profundos, de Stefano Ermon
U Toronto CS 2541 - Inferencia diferenciable y modelos generativos, CS 2547 Aprendizaje de estructuras latentes discretas, CSC 2547 Otoño de 2019: Aprender a buscar. Por David Duvenaud
U Toronto Sta 4273 Invierno 2021 - Minimizando las expectativas. Por Chris Maddison
Berkeley CS294-158 - Aprendizaje profundo sin supervisión. Por Pieter Abbeel
Columbia STCS 8101 - Aprendizaje de representación: una perspectiva probabilística. Por David Blei
Stanford CS324 - Modelos de idiomas grandes. Por Percy Liang, Tatsunori Hashimoto y Christopher Re
U Toronto CSC2541 - Dinámica de entrenamiento de redes neuronales. Por Roger Grosse.
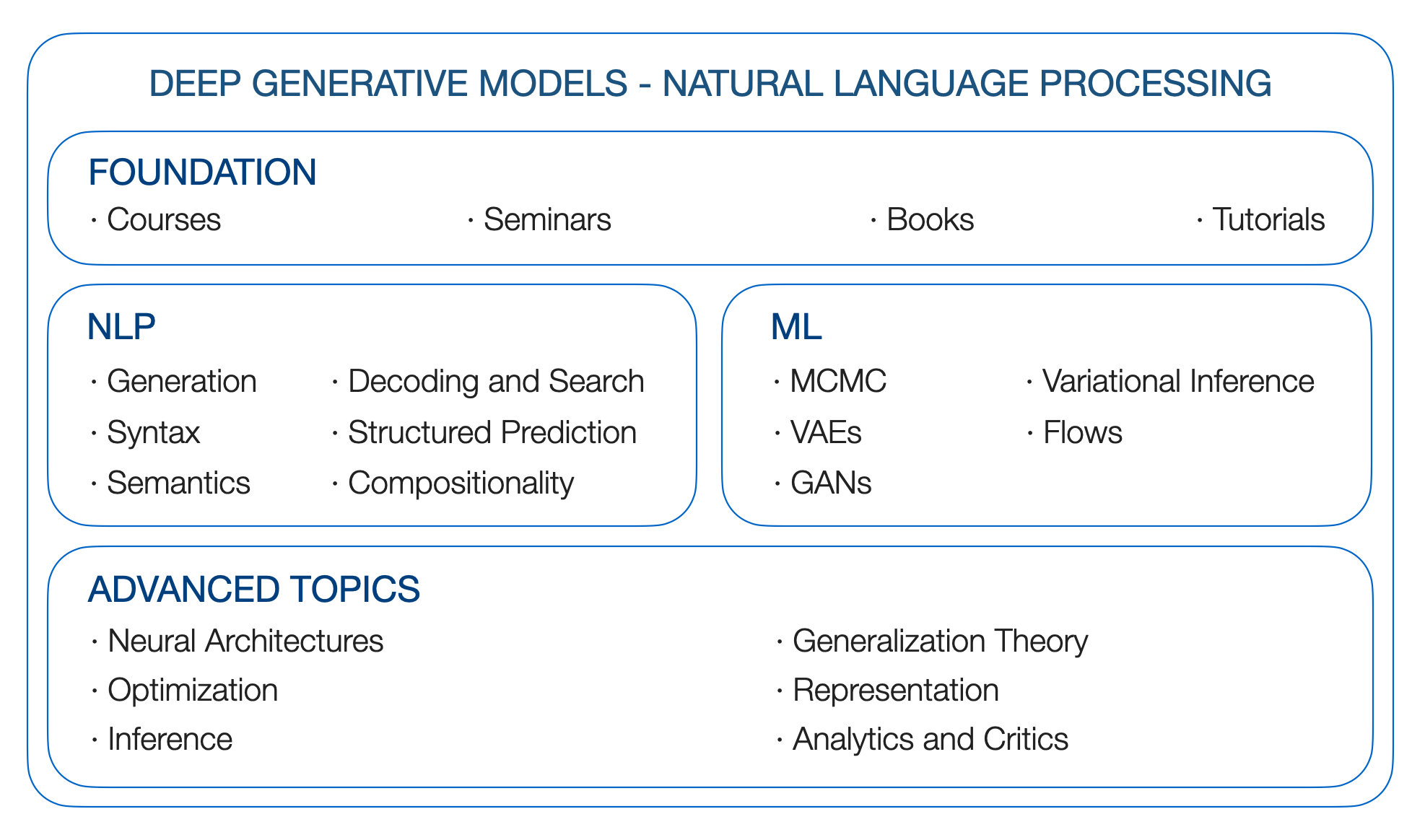
La financiación del DGMS se basa en modelos gráficos probabilísticos. Entonces echamos un vistazo a los siguientes recursos
Curso de la Fundación de Modelos Gráficos de Blei, STAT 6701 en Columbia (enlace)
Modelos gráficos probabilísticos de Xing, 10-708 en CMU (enlace)
Procesamiento del lenguaje natural de Collins, COMS 4995 en Columbia (enlace)
Reconocimiento de patrones y aprendizaje automático. Christopher M. Bishop. 2006
Aprendizaje automático: una perspectiva probabilística. Kevin P. Murphy. 2012
Modelos gráficos, familias exponenciales e inferencia variacional. 2008
Predicción de estructura lingüística. 2011
El proceso sintáctico. 2000
Generando oraciones desde un espacio continuo, Conll 15
Inferencia variacional neural para el procesamiento de texto, ICML 16
Aprender plantillas neuronales para la generación de texto. EMNLP 2018
Modelos residuales basados en energía para la generación de texto. ICLR 20
Generación de paráfrasis con bolsa latente de palabras. Neurips 2019.
Biblioteca de decodificación de Fairseq. [Github]
Generación de texto neuronal de controlabel [lil'log]
La mejor búsqueda de haz primero. TACL 2020
El curioso caso de la degeneración del texto neural. ICLR 2020
Comparación de diversos métodos de decodificación de modelos de lenguaje condicional. ACL 2019
Vigas estocásticas y dónde encontrarlas: el truco Gumbel-Top-K para secuencias de muestreo sin reemplazo. ICML 19
Búsqueda condicional de haz estocástico de Poisson. EMNLP 2021
Decodificación a gran escala para la generación de texto usando redes. 2021
Decodificación léxicamente restringida para la generación de secuencias utilizando la búsqueda del haz de cuadrícula. ACL 2017
Decodificación rápida y limitada con asignación de haz dinámico para la traducción del automóvil neuronal. NAACL 2018
Decodificación mejorada léxicamente restringida para la traducción y reescritura monolingüe. NAACL 2019
Hacia la decodificación como optimización continua en la traducción del automóvil neuronal. EMNLP 2017
Generado de texto léxicamente restringido léxicamente degradado guiado por gradiente. EMNLP 2020
Generación de texto controlada como optimización continua con múltiples restricciones. 2021
Decodificación neurológica: (UN) Generación de texto neural supervisada con restricciones lógicas de predicado. NAACL 2021
Decodificación neurológica de A*Esque: generación de texto restringida con heurística de lookhead. 2021
Decodificación en frío: generación de texto limitada basada en energía con Dynamics de Langevin. 2022
Nota: No he pasado por este capítulo, ¡por favor dame sugerencias!
Traducción de máquina neuronal no autorgresiva. ICLR 2018
Traducción de máquina neuronal completamente no autorgresiva: trucos del comercio.
Decodificación rápida en modelos de secuencia utilizando variables latentes discretas. ICML 2021
Generación de texto en cascada con transformadores de Markov. Arxiv 20
Transformador de mirada para la traducción del automóvil neuronal no autorgresivo. ACL 2021
TODO: Más sobre eso
Documentos de inmediato, thunlp (enlace)
CTRL: un modelo de lenguaje de transformador condicional para la generación controlable. Arxiv 2019
Modelos de lenguaje de enchufe y reproducción: un enfoque simple para la generación de texto controlado
Estructura de antorcha: biblioteca de predicción estructurada profunda. Github, documento, documentación
Una introducción a los campos aleatorios condicionales. 2012
Los algoritmos dentro y hacia adelante y hacia adelante son solo backprop. 2016.
Aprendiendo con pérdidas de fenchel-young. JMLR 2019
Redes de atención estructuradas. ICLR 2017
Programación dinámica diferenciable para predicción y atención estructuradas. ICML 2018
Gramáticas recurrentes de la red neuronal. NAACL 16
Gramáticas de redes neuronales recurrentes no supervisadas, NAACL 19
PERTURB-Y PARTE DIFERIBLE: análisis semi-supervisado con un autoencoder variacional estructurado, ICLR 19
El proceso sintáctico. 2020
Autoatención informada lingüísticamente para el etiquetado de roles semánticos. Premio al Mejor Paper de EMNLP 2018
Análisis semántico con autoencoders secuenciales semi-supervisados. 2016
Generalización compositiva en PNL. Lista de papeles
Generalización sin sistematicidad: sobre las habilidades de composición de las redes recurrentes de secuencia a secuencia. ICML 2019
Mejora de la metodología de evaluación de texto a SQL. ACL 2018
Inferencia probabilística utilizando los métodos de la cadena de Markov Monte Carlo. 1993
Elementos de secuencial Monte Carlo (enlace)
Una introducción conceptual a Hamiltonian Monte Carlo (enlace)
Muestreo de candidatos (enlace)
Estimación de la construcción de ruido: un nuevo principio de estimación para modelos estadísticos no normalizados. Aistata 2010
A* muestreo. Premio NIPS 2014 Mejor Paper
Cambridge Group de lectura de inferencia variacional (enlace)
Inferencia variacional: una revisión para los estadísticos.
Inferencia variacional estocástica
Inferencia bayesiana variacional con búsqueda estocástica. ICML 12
Bayes variacionales de codificación automática, ICLR 14
Beta-Vae: aprendizaje de conceptos visuales básicos con un marco variacional restringido. ICLR 2017
Importancia de autoencoders ponderados. ICLR 2015
Propropagación estocástica e inferencia aproximada en modelos generativos profundos. ICML 14
Autoencoders de variacionales semi-amortizados, ICML 18
Autoencoders de adversidad, ICML 18
Más sobre la reparameterización: para rearameterizar la mezcla gaussiana, la matriz de permutación y los muestreadores de rechazo (Gamma y Dirichlet).
Propropagación estocástica a través de distribuciones de densidad de mezcla, ARXIV 16
Gradientes de reparameterización a través de algoritmos de muestreo de rechazo de aceptación. Aistats 2017
Gradientes de reparametrización implícitos. Neurips 2018.
Reparametrización categórica con Gumbel-Softmax. ICLR 2017
La distribución de concreto: una relajación continua de variables aleatorias discretas. ICLR 2017
Reparametrización gaussiana invertible: revisar el Gumbel-Softmax. 2020
Muestreo de subconjunto reparametrable a través de relajaciones continuas. IJCAI 2019
Redes adversas generativas, NIPS 14
Hacia métodos de principios para capacitar a las redes adversas generativas, ICLR 2017
Wasserstein gan
Infogan: aprendizaje de representación interpretable al maximizar las redes adversas generativas. NIPS 2016
Inferencia adversa adversa. ICLR 2017
Modelos generativos profundos basados en flujo, de Lil's Log
Inferencia variacional con flujos de normalización, ICML 15
Aprender sobre el lenguaje con flujos de normalización
Inferencia variacional mejorada con flujo autorregresivo inverso
Estimación de densidad utilizando NVP real. ICLR 17
Aprendizaje no supervisado de estructura sintáctica con proyecciones neuronales invertibles. EMNLP 2018
Flujos de normalización latente para secuencias discretas. ICML 2019.
Flujos discretos: modelos generativos invertibles de datos discretos. 2019
FlowSeq: generación de secuencia condicional no autorgresiva con flujo generativo. EMNLP 2019
Traducción variacional de la máquina neuronal con flujos de normalización. ACL 2020
En la oración, incrustaciones de modelos de idiomas previamente capacitados. EMNLP 2020
FY: Necesita ver cómo se pueden usar modelos generativos basados en puntaje y modelos de difusión para secuencias discretas
Modelado generativo al estimar los gradientes de la distribución de datos. Blog 2021
Documentos de modelado generativo basados en puntaje
Modelado generativo al estimar los gradientes de la distribución de datos. Neurips 2019
¿Qué son los modelos de difusión? 2021
Modelos de difusión impresionante
Aprendizaje profundo sin supervisión utilizando termodinámica de no equilibrio. 2015
Modelos probabilísticos de difusión de difusión. Neurips 2020
Flujos Argmax y difusión multinomial: aprendizaje de distribuciones categóricas. Neurips 2021
Modelos de difusión de denominación estructurada en espacios de estado discretos. Neurips 2021
Modelos de difusión autorregresivos. ICLR 2022
La difusión-LM mejora la generación de texto controlable. 2022
Modelos de difusión fotorrealistas de texto a imagen con comprensión de lenguaje profundo. 2022
Neuronas ordenadas: integración de árbol estructurado en redes neuronales recurrentes
Los RNN pueden generar lenguajes jerárquicos limitados con memoria óptima
Análisis de autoatención múltiple: las cabezas especializadas hacen el trabajo pesado, el resto se puede podar. ACL 2019
Limitaciones teóricas de la autoatención en modelos de secuencia neuronal. TACL 2019
Repensar la atención con los artistas. 2020
THUNLP: Lista de documentos de modelos LangudGge previamente capacitados (enlace)
Papeles relacionados con Bert de Tomohide Shibata
Hippo: memoria recurrente con proyecciones polinomiales óptimas. Neurips 2020
Combinando modelos recurrentes, convolucionales y de tiempo continuo con la capa espacial de estado lineal. Neurips 2021
Modelando eficientemente secuencias largas con espacios de estado estructurados. ICLR 2022
Por qué S4 es bueno en secuencia larga: recordando una secuencia con aproximación de la función en línea. 2022
GPT3 (175b). Los modelos de idiomas son alumnos de pocos disparos. Mayo de 2020
Megatron-Turing NLG (530B). Usando Deepeed y Megatron para entrenar a NLG 530B de megatron, un modelo de lenguaje generativo a gran escala. Enero de 2022
Lamda (137b). LAMDA: modelos de idioma para aplicaciones de diálogo. Enero de 2022
Gopher (280b). Modelos de escala de lenguaje: métodos, análisis e ideas de la capacitación Gopher. Diciembre de 2021
Chinchilla (70b). Capacitación modelos de lenguaje grande de cómputo óptimo. Marzo de 2022
Palma (540b). Palma: modelado de lenguaje de escala con vías. Abr 2022
OPT (175B). OPT: Open Modelos de lenguaje de transformador previamente capacitado. Mayo de 2022
Bloom (176B): BigScience Gran modelo de lenguaje multilingüe de acceso abierto de ciencia abierta. Mayo de 2022
Blenderbot 3 (175b): un agente de conversación desplegado que continuamente aprende a participar responsablemente. Agosto de 2022
Leyes de escala para modelos de lenguaje neuronal. 2020
Habilidades emergentes de modelos de idiomas grandes. 2022
Minimizar las expectativas. Chris Maddison
Estimación de gradiente de Monte Carlo en aprendizaje automático
Inferencia variacional para los objetivos de Monte Carlo. ICML 16
Rebar: estimaciones de gradiente imparcial de baja varianza para modelos de variables latentes discretos. NIPS 17
Backpropagation a través del vacío: la optimización de control varía para la estimación de gradiente de caja negra. ICLR 18
Backpropaging a través de argmax estructurado usando una espiga. ACL 2018 Mejor mención de honor de documento.
Comprensión de la mecánica de la espiga: gradientes sustitutos para el aprendizaje de la estructura latente. EMNLP 2020
Aprendizaje con optimizadores perturbados diferenciables. Neurips 2020
Estimación de gradiente con trucos estocásticos Softmax. Neurips 2020
Programación dinámica diferenciable para predicción y atención estructuradas. ICML 18
Optimización estocástica de las redes de clasificación a través de relajaciones continuas
Rangos diferenciables y clasificación utilizando transporte óptimo
Reparameterizar el Polyitope Birkhoff para la inferencia de permutación variacional. Aistats 2018
Un marco regularizado para la atención neuronal escasa y estructurada. Neurips 2017
Sparsemap: inferencia estructurada dispersa diferenciable. ICML 2018
Reconocimiento de entidad con nombre anidado con Treecrfs observados parcialmente. AAAI 2021
Gradientes estocásticos de Welled-Wellized Rao para distribuciones discretas. ICML 2019.
Marginación eficiente de variables latentes discretas y estructuradas a través de la escasez. Neurips 2020
Regularización posterior para modelos variables latentes estructurados. JMLR 2010
Control posterior de la generación de Blackbox. 2019
Inducción de gramática de dependencia con un analizador de transición variacional neural. AAAI 2019
(En chino) 微分几何与拓扑学简明教程
Solo Bayes debe aprender un colector (en la estimación de la estructura geométrica diferencial de los datos). Arxiv 2018
La geometría riemanniana de modelos generativos profundos. CVPRW 2018
La geometría de los modelos de imagen generativos profundos y sus aplicaciones. ICLR 2021
Métricas para modelos generativos profundos. Aistats 2017
Algoritmos de primer orden para la optimización Min-Max en espacios métricos geodésicos. 2022
Características aleatorias para máquinas de núcleo a gran escala. Neurips 2007
Encontrar estructura con aleatoriedad: algoritmos probabilísticos para construir descomposiciones de matriz aproximada. Siam 2011
Optimización eficiente de bucles y límites con sumas telescópicas aleatorias. ICML 2019
Estimación de la relación de densidad telescópica. Neurips 2020
Procesos gaussianos escalables sin sesgo a través de truncamientos aleatorios. ICML 2021
Diferenciación automática aleatoria. ICLR 2021
Escala de inferencia estructurada con aleatorización. 2021
Elementos de la teoría de la información. Cubierta y Thomas. 1991
Sobre límites variacionales de información mutua. ICML 2019
Aprender representaciones profundas por estimación y maximización de información mutua. ICLR 2019
Mía: Información mutua Estimación neuronal
Información variacional profunda cuello de botella. ICLR 2017
Identificación de modelos de mezcla bayesiana
Desengling Desenglement en autoencoders variacionales. ICML 2019
Desafiantes suposiciones comunes en el aprendizaje no supervisado de representaciones desenredadas. ICML 2019
Aparición de invariancia y desenredado en representaciones profundas
Minimización de riesgo invariante
Arreglando un elbo roto. ICML 2018.
Los límites variacionales más estrictos no son necesariamente mejores. ICML 2018
El Bernoulli continuo: arreglando un error generalizado en los autoencoders variacionales. Neurips 2019
¿Saben modelos generativos profundos lo que no saben? ICLR 2019
Estimación efectiva de modelos de lenguaje generativo profundo. ACL 2020
¿Qué tan bueno es el Bayes posterior en las redes neuronales profundas realmente? ICML 2020
Una teoría estadística de los posteriores al frío en redes neuronales profundas. ICLR 2021
Limitaciones de los modelos autorregresivos y sus alternativas. NAACL 2021


