JORA
1.0.0
更新(4/8/2024) :JORA現在支持Google的Gemma模型。
更新(4/11/2024) :Gemma 1.1添加了支持
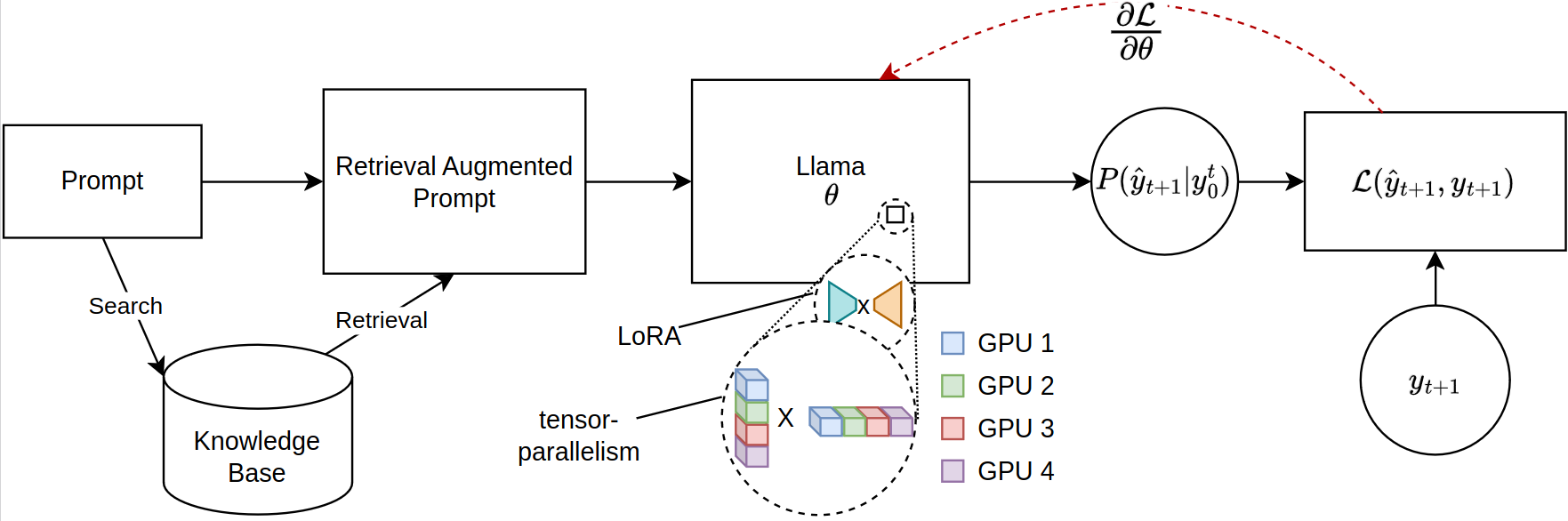
大型語言模型(LLMS)的基於檢索任務的縮放,尤其是在檢索增強發電(RAG)中,面臨著重大的內存限制,尤其是在微調廣泛的及時序列時。當前的開源庫支持多個GPU的全模型推理和微調,但缺乏適應檢索到上下文所需的有效參數分佈。在解決這一差距的情況下,我們引入了一個新穎的框架,用於利用分佈式培訓的Llama-2模型的PEFT兼容微調。我們的框架獨特地利用了JAX的Jax(JIT)彙編和張量縮減來進行有效的資源管理,從而促進了隨著內存要求減少的加速微調。這種進步顯著提高了微調LLMs對複雜的抹布應用的可擴展性和可行性,即使在GPU資源有限的系統上也是如此。我們的實驗表明,與擁抱面部/深速實施相比,運行時的提高超過12倍,而四個GPU則消耗了少於每GPU的VRAM一半。
請確保您安裝了最新版本的JAX。 https://github.com/google/jax
要安裝軟件包,請在存儲庫的根目錄中運行以下命令:
git clone https://github.com/aniquetahir/JORA.git
cd JORA
pip install -e .確保JAX可以訪問GPU:
import jax
print ( jax . devices ())可以通過python或提供GUI來使用該庫。
Calallama類可用於定義配置。明智的參數設置為默認值。
class ParallamaConfig ( NamedTuple ):
JAX_PARAMS_PATH : str
LLAMA2_META_PATH : str # e.g. '/tmp/llama2-13B'
MODEL_SIZE : str # '7B', '13B', '70B'
NUM_GPUS : int = None
LORA_R : int = 16
LORA_ALPHA : int = 16
LORA_DROPOUT : float = 0.05
LR : float = 0.0001
BATCH_SIZE : int = 1
N_ACCUMULATION_STEPS : int = 8
MAX_SEQ_LEN = 2000
N_EPOCHS : int = 7
SEED : int = 420 基於Llama-2的模型
from jora import train_lora , ParallamaConfig , generate_alpaca_dataset
config = ParallamaConfig ( MODEL_SIZE = model_size , JAX_PARAMS_PATH = jax_path ,
LLAMA2_META_PATH = hf_path )
dataset = generate_alpaca_dataset ( dataset_path , 'train' , config )
train_lora ( config , dataset , checkpoint_path )可以從Kaggle下載基於Gemma的模型Flax Gemma模型:
import kagglehub
VARIANT = '2b-it' # @param ['2b', '2b-it', '7b', '7b-it', '1.1-2b-it', '1.1-7b-it'] {type:"string"}
weights_dir = kagglehub . model_download ( f'google/gemma/Flax/ { VARIANT } ' )默認情況下,KaggleHub將模型存儲在~/.cache/kagglehub目錄中。
from jora import ParagemmaConfig , train_lora_gemma , generate_alpaca_dataset_gemma
# model version in '2b', '2b-it', '7b', '7b-it' (2b-it, 7b-it for Gemma 1.1)
config = ParagemmaConfig ( GEMMA_MODEL_PATH = model_path , MODEL_VERSION = model_version )
dataset = generate_alpaca_dataset_gemma ( dataset_path , 'train' , config )
train_lora_gemma ( config , dataset , checkpoint_path )== Gemma 1.1 ==
對於Gemma 1.1模型,KaggleHub將模型存儲在以下目錄結構中:
1.1-7b-it
├── 1
│ ├── 7b-it
│ └── tokenizer.model
└── 1.complete
因此,應將1.1-7b-it模型的config.MODEL_VERSION設置為7b-it 。
generate_alpaca_dataset函數用於從羊駝格式JSON文件中生成數據集。這有助於進行指導格式培訓,因為數據集處理,令牌化和批處理由圖書館處理。另外,火炬Dataset和DataLoader可用於自定義數據集。
Huggingface具有廣泛的生態系統。由於我們的圖書館使用JAX進行培訓,因此由此產生的模型不兼容。為了解決此問題,我們提供了一個子模塊,以將經過JAX訓練的模型轉換回HuggingFace格式。
訓練有素的洛拉權重可以首先與原始參數合併:
SYNOPSIS
python -m jora.lora.merge PARAMS_PATH LORA_PATH OUTPUT_PATH <flags>
POSITIONAL ARGUMENTS
PARAMS_PATH
Type: str
LORA_PATH
Type: str
OUTPUT_PATH
Type: str
FLAGS
-l, --llama2=LLAMA2
Default: False
-g, --gemma=GEMMA
Default: False
NOTES
You can also use flags syntax for POSITIONAL ARGUMENTS
SYNOPSIS
python -m jora.hf HUGGINGFACE_PATH JAX_PATH SAVE_PATH
DESCRIPTION
This function takes a huggingface llama model and replaces the q_proj and v_proj weights with the lora merged weights
POSITIONAL ARGUMENTS
HUGGINGFACE_PATH
Type: str
path to the huggingface llama model
JAX_PATH
Type: str
path to the lora merged params
SAVE_PATH
Type: str
path to save the updated huggingface llama model
NOTES
You can also use flags syntax for POSITIONAL ARGUMENTS
GUI可用於訓練模型。 GUI是通過運行以下命令開始的:
python -m jora.gui| GPU | 1 | 2 | 4 | |
|---|---|---|---|---|
| 帶有Microsoft DeepSpeed Zero-3的擁抱臉PEFT | mem(MB) | 20645.2(39.81) | 23056 /23024(14.63 / 29.29) | 23978 /23921 /23463 /23397(47.87 / 50.39 / 31.96 / 17.46) |
| 性能(SEC) | 4.56(0.04) | 2.81(0.02) | 5.45(0.09) | |
| 喬拉(我們的) | mem(MB) | 23102(0.00) | 16068 /16008(0.00 / 0.00) | 11460 /11448 /11448 /11400(0.0 / 0.00 / 0.00 / 0.00) |
| 性能(SEC) | 0.19(0.00) | 0.79(0.00) | 0.44(0.00) |
在幾個地方,捐款將受到讚賞。
@misc { tahir2024jora ,
title = { JORA: JAX Tensor-Parallel LoRA Library for Retrieval Augmented Fine-Tuning } ,
author = { Anique Tahir and Lu Cheng and Huan Liu } ,
year = { 2024 } ,
eprint = { 2403.11366 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
}JAX Llama-2模型實施AYAKA14732
Google DeepMind的亞麻Gemma模型實施


