JORA
1.0.0
อัปเดต (4/8/2024) : ตอนนี้ Jora รองรับรุ่น Gemma ของ Google
อัปเดต (4/11/2024) : เพิ่มการสนับสนุน Gemma 1.1
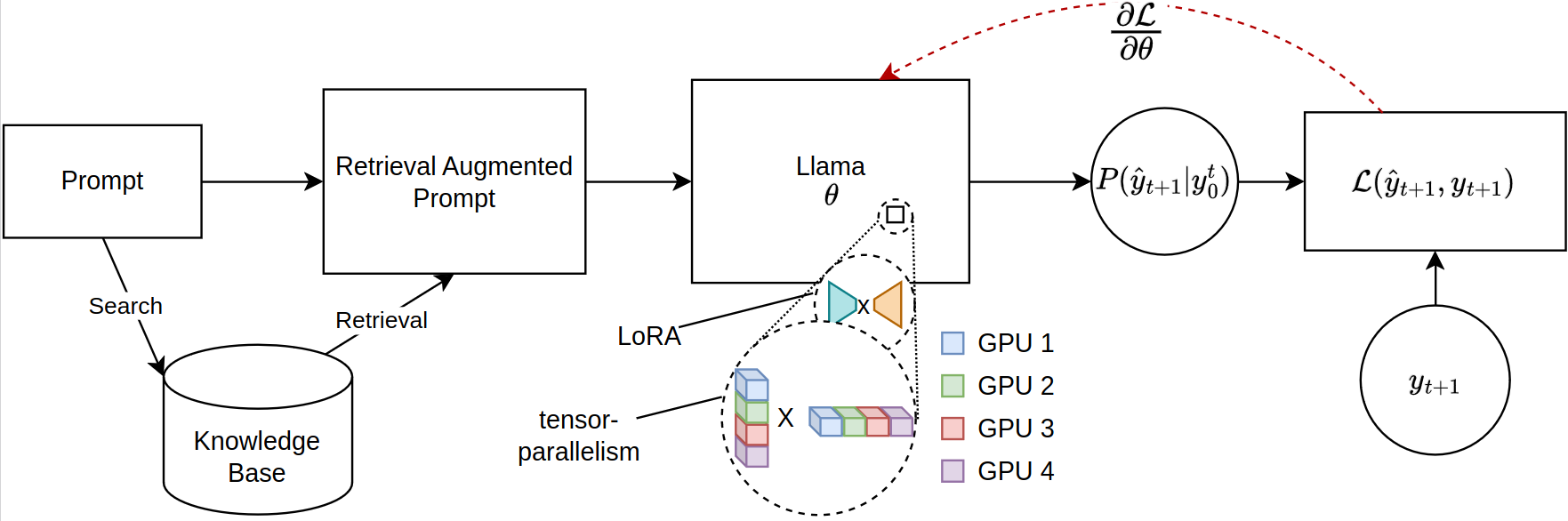
การปรับขนาดของโมเดลภาษาขนาดใหญ่ (LLMS) สำหรับงานที่ได้รับการดึงโดยเฉพาะอย่างยิ่งในการดึงการสร้าง Augmented Generation (RAG) จะต้องเผชิญกับข้อ จำกัด ด้านหน่วยความจำที่สำคัญโดยเฉพาะอย่างยิ่งเมื่อปรับลำดับการปรับลำดับที่กว้างขวาง ห้องสมุดโอเพนซอร์ซในปัจจุบันรองรับการอนุมานแบบจำลองเต็มรูปแบบและการปรับแต่งใน GPU หลายตัว แต่ขาดการรองรับการกระจายพารามิเตอร์ที่มีประสิทธิภาพที่จำเป็นสำหรับบริบทที่ดึงมา ที่กล่าวถึงช่องว่างนี้เราแนะนำกรอบการทำงานใหม่สำหรับการปรับแต่งแบบ PEFT ที่เข้ากันได้กับรุ่น Llama-2, ใช้ประโยชน์จากการฝึกอบรมแบบกระจาย เฟรมเวิร์กของเราใช้การรวบรวมแบบทันเวลา (JIT) ของ JAX โดยเฉพาะและการจัดทำแบบเทนเซอร์เพื่อการจัดการทรัพยากรที่มีประสิทธิภาพซึ่งจะช่วยให้การปรับจูนแบบเร่งด่วนพร้อมข้อกำหนดของหน่วยความจำที่ลดลง ความก้าวหน้านี้ช่วยปรับปรุงความสามารถในการปรับขนาดและความเป็นไปได้ของการปรับจูน LLMs สำหรับแอพพลิเคชั่น RAG ที่ซับซ้อนแม้ในระบบที่มีทรัพยากร GPU ที่ จำกัด การทดลองของเราแสดงการปรับปรุงมากกว่า 12 เท่าในรันไทม์เมื่อเทียบกับการกอดการใช้งานใบหน้า/ลึกลงไปด้วย GPU สี่ตัวในขณะที่ใช้ VRAM น้อยกว่าครึ่งหนึ่งต่อ GPU
โปรดตรวจสอบให้แน่ใจว่าคุณได้ติดตั้ง JAX เวอร์ชันล่าสุดสำหรับ GPU https://github.com/google/jax
ในการติดตั้งแพ็คเกจให้เรียกใช้คำสั่งต่อไปนี้ในไดเรกทอรีรูทของที่เก็บ:
git clone https://github.com/aniquetahir/JORA.git
cd JORA
pip install -e .ตรวจสอบให้แน่ใจว่า JAX สามารถเข้าถึง GPU:
import jax
print ( jax . devices ())ห้องสมุดสามารถใช้ผ่าน Python หรืออีกทางเลือกหนึ่งมี GUI
คลาส Parallama สามารถใช้เพื่อกำหนดค่าการกำหนดค่า พารามิเตอร์ที่เหมาะสมถูกตั้งค่าเป็นค่าเริ่มต้น
class ParallamaConfig ( NamedTuple ):
JAX_PARAMS_PATH : str
LLAMA2_META_PATH : str # e.g. '/tmp/llama2-13B'
MODEL_SIZE : str # '7B', '13B', '70B'
NUM_GPUS : int = None
LORA_R : int = 16
LORA_ALPHA : int = 16
LORA_DROPOUT : float = 0.05
LR : float = 0.0001
BATCH_SIZE : int = 1
N_ACCUMULATION_STEPS : int = 8
MAX_SEQ_LEN = 2000
N_EPOCHS : int = 7
SEED : int = 420 นางแบบตาม Llama-2
from jora import train_lora , ParallamaConfig , generate_alpaca_dataset
config = ParallamaConfig ( MODEL_SIZE = model_size , JAX_PARAMS_PATH = jax_path ,
LLAMA2_META_PATH = hf_path )
dataset = generate_alpaca_dataset ( dataset_path , 'train' , config )
train_lora ( config , dataset , checkpoint_path )รุ่นที่ใช้ Gemma Flax Gemma สามารถดาวน์โหลดได้จาก Kaggle:
import kagglehub
VARIANT = '2b-it' # @param ['2b', '2b-it', '7b', '7b-it', '1.1-2b-it', '1.1-7b-it'] {type:"string"}
weights_dir = kagglehub . model_download ( f'google/gemma/Flax/ { VARIANT } ' ) โดยค่าเริ่มต้น KaggleHub จะเก็บโมเดลไว้ในไดเรกทอรี ~/.cache/kagglehub
from jora import ParagemmaConfig , train_lora_gemma , generate_alpaca_dataset_gemma
# model version in '2b', '2b-it', '7b', '7b-it' (2b-it, 7b-it for Gemma 1.1)
config = ParagemmaConfig ( GEMMA_MODEL_PATH = model_path , MODEL_VERSION = model_version )
dataset = generate_alpaca_dataset_gemma ( dataset_path , 'train' , config )
train_lora_gemma ( config , dataset , checkpoint_path )== Gemma 1.1 ==
สำหรับรุ่น Gemma 1.1 Kagglehub จัดเก็บโมเดลในโครงสร้างไดเรกทอรีต่อไปนี้:
1.1-7b-it
├── 1
│ ├── 7b-it
│ └── tokenizer.model
└── 1.complete
ดังนั้น config.MODEL_VERSION ควรตั้งค่าเป็น 7b-it สำหรับรุ่น 1.1-7b-it
ฟังก์ชั่น generate_alpaca_dataset ใช้เพื่อสร้างชุดข้อมูลจากไฟล์รูปแบบ Alpaca JSON สิ่งนี้จะช่วยในการฝึกอบรมรูปแบบการสอนเนื่องจากการประมวลผลชุดข้อมูลการทำโทเค็นและการแบทช์ได้รับการจัดการโดยห้องสมุด อีกวิธีหนึ่งคือ Dataset คบเพลิงและ DataLoader สามารถใช้สำหรับชุดข้อมูลที่กำหนดเอง
HuggingFace มีระบบนิเวศที่กว้างใหญ่ เนื่องจากห้องสมุดของเราใช้ JAX สำหรับการฝึกอบรมรูปแบบผลลัพธ์จึงไม่เข้ากัน ในการแก้ปัญหานี้เราได้จัดทำ submodule สำหรับการแปลงรูปแบบที่ผ่านการฝึกอบรมของ JAX กลับไปเป็นรูปแบบ HuggingFace
น้ำหนัก LORA ที่ผ่านการฝึกอบรมสามารถรวมเข้ากับพารามิเตอร์ดั้งเดิมได้ก่อน:
SYNOPSIS
python -m jora.lora.merge PARAMS_PATH LORA_PATH OUTPUT_PATH <flags>
POSITIONAL ARGUMENTS
PARAMS_PATH
Type: str
LORA_PATH
Type: str
OUTPUT_PATH
Type: str
FLAGS
-l, --llama2=LLAMA2
Default: False
-g, --gemma=GEMMA
Default: False
NOTES
You can also use flags syntax for POSITIONAL ARGUMENTS
SYNOPSIS
python -m jora.hf HUGGINGFACE_PATH JAX_PATH SAVE_PATH
DESCRIPTION
This function takes a huggingface llama model and replaces the q_proj and v_proj weights with the lora merged weights
POSITIONAL ARGUMENTS
HUGGINGFACE_PATH
Type: str
path to the huggingface llama model
JAX_PATH
Type: str
path to the lora merged params
SAVE_PATH
Type: str
path to save the updated huggingface llama model
NOTES
You can also use flags syntax for POSITIONAL ARGUMENTS
GUI สามารถใช้ในการฝึกอบรมแบบจำลอง GUI เริ่มต้นด้วยการเรียกใช้คำสั่งต่อไปนี้:
python -m jora.gui| GPUs | 1 | 2 | 4 | |
|---|---|---|---|---|
| กอดหน้า peft w/ microsoft deepspeed zero-3 | MEM (MB) | 20645.2 (39.81) | 23056 /23024 (14.63 / 29.29) | 23978 /23921 /23463 /23397 (47.87 / 50.39 / 31.96 / 17.46) |
| ประสิทธิภาพ (วินาที) | 4.56 (0.04) | 2.81 (0.02) | 5.45 (0.09) | |
| Jora (ของเรา) | MEM (MB) | 23102 (0.00) | 16068 /16008 (0.00 / 0.00) | 11460 /11448 / 11448/11400 (0.0 / 0.00 / 0.00 / 0.00) |
| ประสิทธิภาพ (วินาที) | 0.19 (0.00) | 0.79 (0.00) | 0.44 (0.00) |
มีหลายสถานที่ที่จะได้รับการชื่นชม
@misc { tahir2024jora ,
title = { JORA: JAX Tensor-Parallel LoRA Library for Retrieval Augmented Fine-Tuning } ,
author = { Anique Tahir and Lu Cheng and Huan Liu } ,
year = { 2024 } ,
eprint = { 2403.11366 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
}การใช้งานแบบจำลอง Jax Llama-2 โดย Ayaka14732
การใช้แบบจำลอง Flax Gemma โดย Google DeepMind


