JORA
1.0.0
Mise à jour (4/8/2024) : Jora prend désormais en charge les modèles GEMMA de Google.
Mise à jour (4/11/2024) : GEMMA 1.1 Prise en charge ajoutée
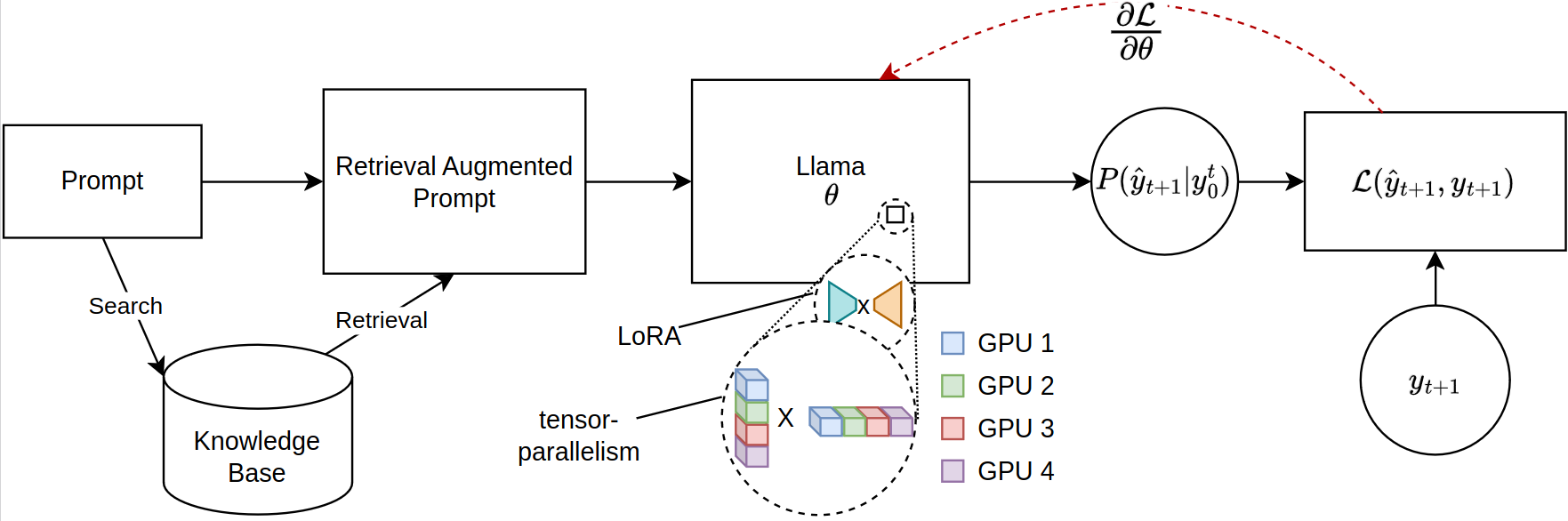
La mise à l'échelle des grands modèles de langage (LLMS) pour les tâches basées sur la récupération, en particulier dans la génération augmentée (RAG) de récupération, fait face à des contraintes de mémoire importantes, en particulier lorsqu'il a affiné les séquences rapides étendues. Les bibliothèques open source actuelles prennent en charge l'inférence du modèle complet et le réglage fin sur plusieurs GPU, mais ne sont pas à l'abri de la distribution de paramètres efficace requise pour le contexte récupéré. Assisant à cet écart, nous introduisons un nouveau cadre pour le réglage fin compatible PEFT des modèles lama-2, en tirant parti de la formation distribuée. Notre cadre utilise de manière unique la compilation juste en temps (JIT) de Jax et la tenue des tenseurs pour une gestion efficace des ressources, permettant ainsi un réglage de fin accéléré avec des exigences de mémoire réduites. Cette progression améliore considérablement l'évolutivité et la faisabilité des LLM de réglage fin pour les applications de chiffons complexes, même sur des systèmes avec des ressources GPU limitées. Nos expériences montrent plus de 12 fois l'amélioration de l'exécution par rapport à la mise en œuvre des étreintes de face / vitesse profonde avec quatre GPU tout en consommant moins de la moitié du VRAM par GPU.
Veuillez vous assurer que la dernière version de JAX pour GPU a installé. https://github.com/google/jax
Pour installer le package, exécutez la commande suivante dans le répertoire racine du référentiel:
git clone https://github.com/aniquetahir/JORA.git
cd JORA
pip install -e .Assurez-vous que Jax peut accéder aux GPU:
import jax
print ( jax . devices ())La bibliothèque peut être utilisée via Python, ou alternativement, une interface graphique est fournie.
La classe Parallama peut être utilisée pour définir la configuration. Les paramètres sensibles sont définis par défaut.
class ParallamaConfig ( NamedTuple ):
JAX_PARAMS_PATH : str
LLAMA2_META_PATH : str # e.g. '/tmp/llama2-13B'
MODEL_SIZE : str # '7B', '13B', '70B'
NUM_GPUS : int = None
LORA_R : int = 16
LORA_ALPHA : int = 16
LORA_DROPOUT : float = 0.05
LR : float = 0.0001
BATCH_SIZE : int = 1
N_ACCUMULATION_STEPS : int = 8
MAX_SEQ_LEN = 2000
N_EPOCHS : int = 7
SEED : int = 420 Modèles basés sur Llama-2
from jora import train_lora , ParallamaConfig , generate_alpaca_dataset
config = ParallamaConfig ( MODEL_SIZE = model_size , JAX_PARAMS_PATH = jax_path ,
LLAMA2_META_PATH = hf_path )
dataset = generate_alpaca_dataset ( dataset_path , 'train' , config )
train_lora ( config , dataset , checkpoint_path )Modèles basés sur Gemma, les modèles Gemma peuvent être téléchargés à partir de Kaggle:
import kagglehub
VARIANT = '2b-it' # @param ['2b', '2b-it', '7b', '7b-it', '1.1-2b-it', '1.1-7b-it'] {type:"string"}
weights_dir = kagglehub . model_download ( f'google/gemma/Flax/ { VARIANT } ' ) Par défaut, le KaggleHub stocke le modèle dans le répertoire ~/.cache/kagglehub .
from jora import ParagemmaConfig , train_lora_gemma , generate_alpaca_dataset_gemma
# model version in '2b', '2b-it', '7b', '7b-it' (2b-it, 7b-it for Gemma 1.1)
config = ParagemmaConfig ( GEMMA_MODEL_PATH = model_path , MODEL_VERSION = model_version )
dataset = generate_alpaca_dataset_gemma ( dataset_path , 'train' , config )
train_lora_gemma ( config , dataset , checkpoint_path )== gemma 1.1 ==
Pour les modèles Gemma 1.1, KaggleHub stocke le modèle dans la structure du répertoire suivant:
1.1-7b-it
├── 1
│ ├── 7b-it
│ └── tokenizer.model
└── 1.complete
Ainsi, config.MODEL_VERSION doit être défini sur 7b-it pour le modèle 1.1-7b-it .
La fonction generate_alpaca_dataset est utilisée pour générer l'ensemble de données à partir d'un fichier json au format alpaca. Cela contribue à la formation au format instructeur, car le traitement de l'ensemble de données, la tokenisation et le lots sont gérés par la bibliothèque. Alternativement, Dataset de torch et DataLoader peuvent être utilisés pour les ensembles de données personnalisés.
Huggingface a un vaste écosystème. Étant donné que notre bibliothèque utilise JAX pour la formation, le modèle résultant est incompatible. Pour résoudre ce problème, nous fournissons un sous-module pour convertir un modèle formé JAX au format HuggingFace.
Les poids LORA formés peuvent d'abord être fusionnés avec les paramètres d'origine:
SYNOPSIS
python -m jora.lora.merge PARAMS_PATH LORA_PATH OUTPUT_PATH <flags>
POSITIONAL ARGUMENTS
PARAMS_PATH
Type: str
LORA_PATH
Type: str
OUTPUT_PATH
Type: str
FLAGS
-l, --llama2=LLAMA2
Default: False
-g, --gemma=GEMMA
Default: False
NOTES
You can also use flags syntax for POSITIONAL ARGUMENTS
SYNOPSIS
python -m jora.hf HUGGINGFACE_PATH JAX_PATH SAVE_PATH
DESCRIPTION
This function takes a huggingface llama model and replaces the q_proj and v_proj weights with the lora merged weights
POSITIONAL ARGUMENTS
HUGGINGFACE_PATH
Type: str
path to the huggingface llama model
JAX_PATH
Type: str
path to the lora merged params
SAVE_PATH
Type: str
path to save the updated huggingface llama model
NOTES
You can also use flags syntax for POSITIONAL ARGUMENTS
L'interface graphique peut être utilisée pour former un modèle. L'interface graphique est lancée par exécuter la commande suivante:
python -m jora.gui| GPUS | 1 | 2 | 4 | |
|---|---|---|---|---|
| Emballage Face PEFT avec Microsoft Deeppeed Zero-3 | MEM (MB) | 20645.2 (39,81) | 23056/23024 (14.63 / 29.29) | 23978/23921/23463/23397 (47.87 / 50.39 / 31.96 / 17.46) |
| Performance (SEC) | 4,56 (0,04) | 2,81 (0,02) | 5,45 (0,09) | |
| Jora (la nôtre) | MEM (MB) | 23102 (0,00) | 16068/16008 (0,00 / 0,00) | 11460/11448/11448/11400 (0,0 / 0,00 / 0,00 / 0,00) |
| Performance (SEC) | 0,19 (0,00) | 0,79 (0,00) | 0,44 (0,00) |
Il y a plusieurs endroits où les contributions seraient appréciées.
@misc { tahir2024jora ,
title = { JORA: JAX Tensor-Parallel LoRA Library for Retrieval Augmented Fine-Tuning } ,
author = { Anique Tahir and Lu Cheng and Huan Liu } ,
year = { 2024 } ,
eprint = { 2403.11366 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
}JAX LLAMA-2 Implémentation du modèle par Ayaka14732
Implémentation du modèle de lin gemma par Google Deepmind


