JORA
1.0.0
Update (4/8/2024) : Jora unterstützt jetzt die Gemma -Modelle von Google.
Update (4/11/2024) : Gemma 1.1 Support hinzugefügt
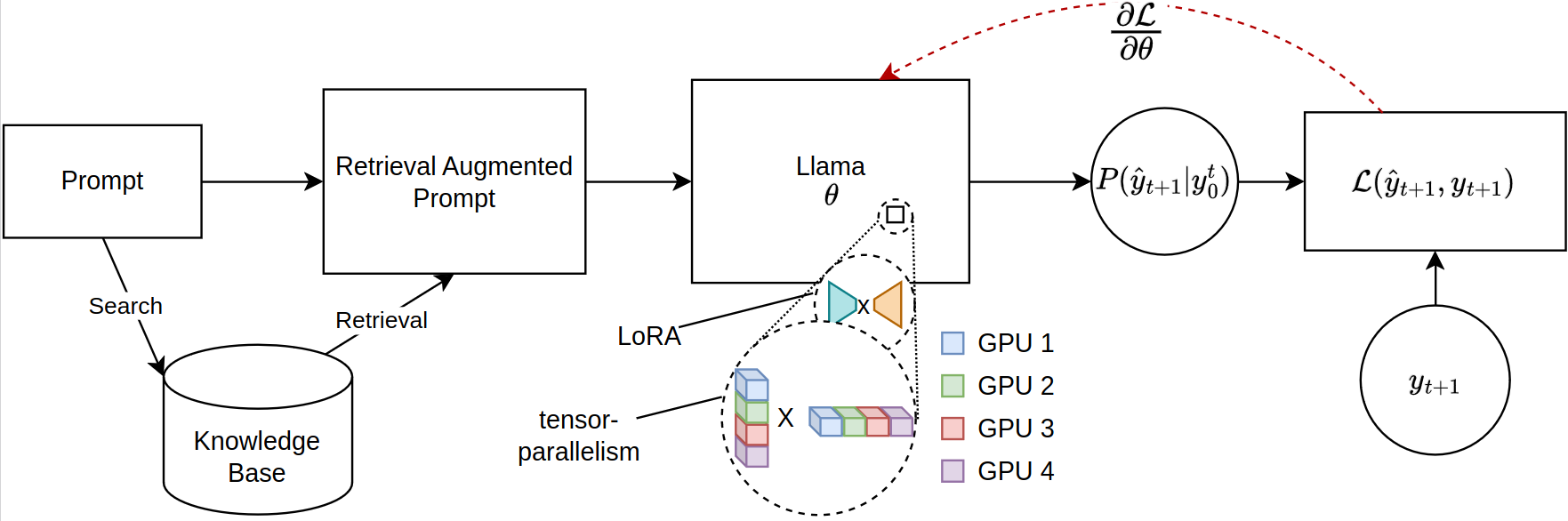
Die Skalierung von großsprachigen Modellen (LLMs) für retrievalbasierte Aufgaben, insbesondere in der Abruf Augmented Generation (RAG), sieht sich erhebliche Gedächtnisbeschränkungen aus, insbesondere wenn es sich um eine fein abfindende umfangreiche Schnellsequenzen handelt. Aktuelle Open-Source-Bibliotheken unterstützen die vollständige Inferenz und die Feinabstimmung über mehrere GPUs hinweg, sind jedoch nicht, um die für den abgerufene Kontext erforderliche effiziente Parameterverteilung aufzunehmen. In Bezug auf diese Lücke stellen wir einen neuartigen Rahmen für die PEFT-kompatible Feinabstimmung von LLAMA-2-Modellen ein und nutzen verteiltes Training. In unserem Rahmen werden JAX 'Just-in-Time (JIT) -Kompilation und Tensor-Sendung für ein effizientes Ressourcenmanagement verwendet, wodurch eine beschleunigte Feinabstimmung mit reduzierten Speicheranforderungen ermöglicht wird. Dieser Fortschritt verbessert die Skalierbarkeit und Machbarkeit von Feinabstimmungs-LLMs für komplexe Lappenanwendungen erheblich, selbst bei Systemen mit begrenzten GPU-Ressourcen. Unsere Experimente zeigen eine Verbesserung der Laufzeit um mehr als 12 -fache im Vergleich zur Implementierung von Face/Deepspeed mit vier GPUs und konsumieren weniger als die Hälfte des VRAM pro GPU.
Bitte stellen Sie sicher, dass Sie die neueste Version von JAX für GPU installiert haben. https://github.com/google/jax
Führen Sie zum Installieren des Pakets den folgenden Befehl im Stammverzeichnis des Repositorys aus:
git clone https://github.com/aniquetahir/JORA.git
cd JORA
pip install -e .Stellen Sie sicher, dass Jax auf den GPUs zugreifen kann:
import jax
print ( jax . devices ())Die Bibliothek kann über Python verwendet werden, oder alternativ wird eine GUI bereitgestellt.
Die Parallama -Klasse kann verwendet werden, um die Konfiguration zu definieren. Sensible Parameter werden als Standardeinstellungen festgelegt.
class ParallamaConfig ( NamedTuple ):
JAX_PARAMS_PATH : str
LLAMA2_META_PATH : str # e.g. '/tmp/llama2-13B'
MODEL_SIZE : str # '7B', '13B', '70B'
NUM_GPUS : int = None
LORA_R : int = 16
LORA_ALPHA : int = 16
LORA_DROPOUT : float = 0.05
LR : float = 0.0001
BATCH_SIZE : int = 1
N_ACCUMULATION_STEPS : int = 8
MAX_SEQ_LEN = 2000
N_EPOCHS : int = 7
SEED : int = 420 Modelle basierend auf LLAMA-2
from jora import train_lora , ParallamaConfig , generate_alpaca_dataset
config = ParallamaConfig ( MODEL_SIZE = model_size , JAX_PARAMS_PATH = jax_path ,
LLAMA2_META_PATH = hf_path )
dataset = generate_alpaca_dataset ( dataset_path , 'train' , config )
train_lora ( config , dataset , checkpoint_path )Gemma -basierte Modelle Flachs -Gemma -Modelle können von Kaggle heruntergeladen werden:
import kagglehub
VARIANT = '2b-it' # @param ['2b', '2b-it', '7b', '7b-it', '1.1-2b-it', '1.1-7b-it'] {type:"string"}
weights_dir = kagglehub . model_download ( f'google/gemma/Flax/ { VARIANT } ' ) Standardmäßig speichert das KaggleHub das Modell im Verzeichnis ~/.cache/kagglehub .
from jora import ParagemmaConfig , train_lora_gemma , generate_alpaca_dataset_gemma
# model version in '2b', '2b-it', '7b', '7b-it' (2b-it, 7b-it for Gemma 1.1)
config = ParagemmaConfig ( GEMMA_MODEL_PATH = model_path , MODEL_VERSION = model_version )
dataset = generate_alpaca_dataset_gemma ( dataset_path , 'train' , config )
train_lora_gemma ( config , dataset , checkpoint_path )== Gemma 1.1 ==
Für Gemma 1.1 -Modelle speichert KaggleHub das Modell in der folgenden Verzeichnisstruktur:
1.1-7b-it
├── 1
│ ├── 7b-it
│ └── tokenizer.model
└── 1.complete
Somit sollte config.MODEL_VERSION für 1.1-7b-it it auf 7b-it eingestellt werden.
Die Funktion generate_alpaca_dataset wird verwendet, um den Datensatz aus einer JSON -Datei mit Alpaca -Format zu generieren. Dies hilft bei der Anweisung des Formattrainings, da die Datensatzverarbeitung, Tokenisierung und Charge von der Bibliothek behandelt werden. Alternativ können Dataset und DataLoader für benutzerdefinierte Datensätze verwendet werden.
Suggingface hat ein riesiges Ökosystem. Da unsere Bibliothek JAX für das Training verwendet, ist das resultierende Modell unvereinbar. Um dieses Problem zu lösen, bieten wir ein Submodul für die Umwandlung eines von JAX trainierten Modells in das Umarmungsfaktorformat an.
Ausgebildete Lora -Gewichte können zunächst mit den ursprünglichen Parametern zusammengeführt werden:
SYNOPSIS
python -m jora.lora.merge PARAMS_PATH LORA_PATH OUTPUT_PATH <flags>
POSITIONAL ARGUMENTS
PARAMS_PATH
Type: str
LORA_PATH
Type: str
OUTPUT_PATH
Type: str
FLAGS
-l, --llama2=LLAMA2
Default: False
-g, --gemma=GEMMA
Default: False
NOTES
You can also use flags syntax for POSITIONAL ARGUMENTS
SYNOPSIS
python -m jora.hf HUGGINGFACE_PATH JAX_PATH SAVE_PATH
DESCRIPTION
This function takes a huggingface llama model and replaces the q_proj and v_proj weights with the lora merged weights
POSITIONAL ARGUMENTS
HUGGINGFACE_PATH
Type: str
path to the huggingface llama model
JAX_PATH
Type: str
path to the lora merged params
SAVE_PATH
Type: str
path to save the updated huggingface llama model
NOTES
You can also use flags syntax for POSITIONAL ARGUMENTS
Die GUI kann verwendet werden, um ein Modell zu trainieren. Die GUI wird mit dem folgenden Befehl ausgeführt:
python -m jora.gui| GPUS | 1 | 2 | 4 | |
|---|---|---|---|---|
| Umarme Face Peft mit Microsoft Deepspeed Zero-3 | MEM (MB) | 20645.2 (39,81) | 23056 /23024 (14.63 / 29.29) | 23978 /23921 /23463 /23397 (47.87 / 50.39 / 31.96 / 17.46) |
| Leistung (SECS) | 4,56 (0,04) | 2,81 (0,02) | 5,45 (0,09) | |
| Jora (unsere) | MEM (MB) | 23102 (0,00) | 16068 /16008 (0,00 / 0,00) | 11460 /11448 /11448 /11400 (0,0 / 0,00 / 0,00 / 0,00) |
| Leistung (SECS) | 0,19 (0,00) | 0,79 (0,00) | 0,44 (0,00) |
Es gibt mehrere Orte, an denen Beiträge geschätzt würden.
@misc { tahir2024jora ,
title = { JORA: JAX Tensor-Parallel LoRA Library for Retrieval Augmented Fine-Tuning } ,
author = { Anique Tahir and Lu Cheng and Huan Liu } ,
year = { 2024 } ,
eprint = { 2403.11366 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
}JAX LLAMA-2-Modellimplementierung durch Ayaka14732
Implementierung von Flax Gemma -Modell von Google DeepMind


