JORA
1.0.0
Обновление (8/8/2024) : JORA теперь поддерживает модели Google Gemma.
Обновление (4/11/2024) : добавлена поддержка GEMMA 1.1
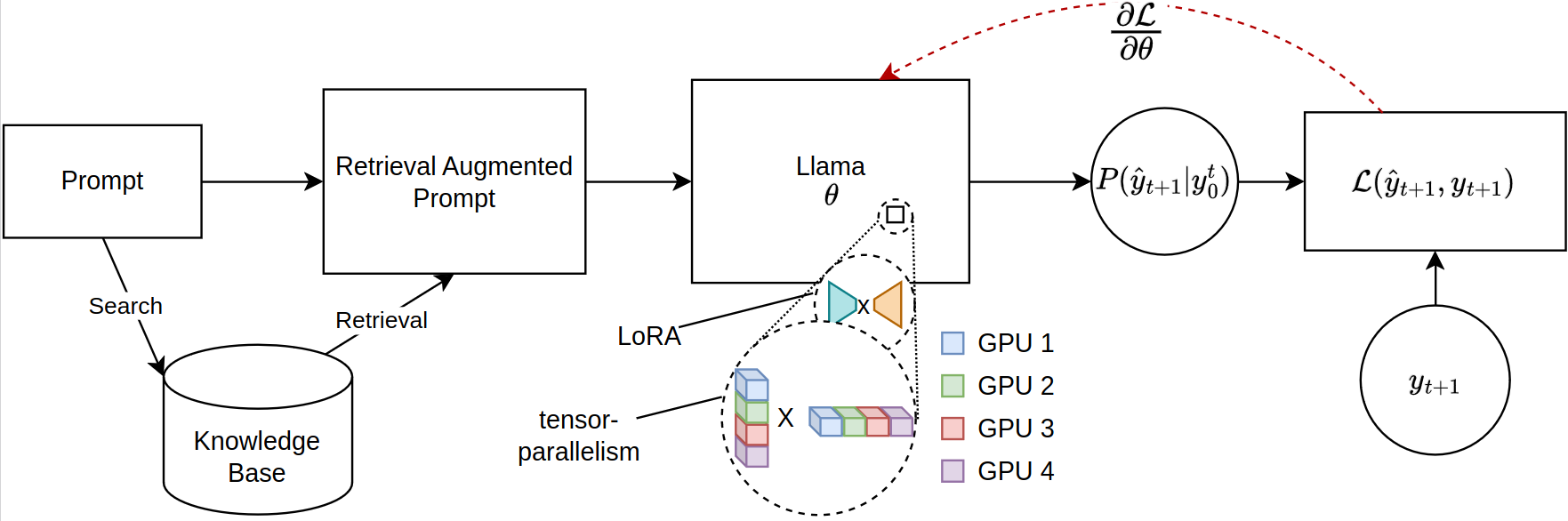
Масштабирование больших языковых моделей (LLMS) для поисковых задач, особенно в результате получения добывающей генерации (RAG), сталкивается с значительными ограничениями памяти, особенно при тонкой настройке обширных последовательностей. Текущие библиотеки с открытым исходным кодом поддерживают полномоделье вывод и тонкую настройку в нескольких графических процессорах, но не соответствуют эффективному распределению параметров, необходимым для извлеченного контекста. Обращаясь к этому разрыву, мы вводим новую структуру для точной настройки моделей LLAMA-2, используя распределенную тренировку. В нашей структуре однозначно используется подборка JAX (JIT) и тензоры для эффективного управления ресурсами, что позволяет ускорить точную настройку с уменьшенными требованиями к памяти. Это продвижение значительно улучшает масштабируемость и выполнимость тонкой настройки LLM для сложных тряпичных приложений, даже в системах с ограниченными ресурсами графического процессора. Наши эксперименты показывают более чем 12 -кратное улучшение во время выполнения по сравнению с обнимающими лицами/глубокими реализацией с четырьмя графическими процессорами, потребляя менее половины VRAM на GPU.
Пожалуйста, убедитесь, что у вас есть последняя версия JAX для GPU. https://github.com/google/jax
Чтобы установить пакет, запустите следующую команду в корневом каталоге репозитория:
git clone https://github.com/aniquetahir/JORA.git
cd JORA
pip install -e .Убедитесь, что JAX может получить доступ к графическим процессорам:
import jax
print ( jax . devices ())Библиотека может использоваться через Python, или, в качестве альтернативы, предоставляется графический интерфейс.
Класс Parallama может использоваться для определения конфигурации. Разумные параметры устанавливаются как значения по умолчанию.
class ParallamaConfig ( NamedTuple ):
JAX_PARAMS_PATH : str
LLAMA2_META_PATH : str # e.g. '/tmp/llama2-13B'
MODEL_SIZE : str # '7B', '13B', '70B'
NUM_GPUS : int = None
LORA_R : int = 16
LORA_ALPHA : int = 16
LORA_DROPOUT : float = 0.05
LR : float = 0.0001
BATCH_SIZE : int = 1
N_ACCUMULATION_STEPS : int = 8
MAX_SEQ_LEN = 2000
N_EPOCHS : int = 7
SEED : int = 420 Модели на основе ламы-2
from jora import train_lora , ParallamaConfig , generate_alpaca_dataset
config = ParallamaConfig ( MODEL_SIZE = model_size , JAX_PARAMS_PATH = jax_path ,
LLAMA2_META_PATH = hf_path )
dataset = generate_alpaca_dataset ( dataset_path , 'train' , config )
train_lora ( config , dataset , checkpoint_path )Модели на основе Gemma Models Flax Gemma Модели могут быть загружены с Kaggle:
import kagglehub
VARIANT = '2b-it' # @param ['2b', '2b-it', '7b', '7b-it', '1.1-2b-it', '1.1-7b-it'] {type:"string"}
weights_dir = kagglehub . model_download ( f'google/gemma/Flax/ { VARIANT } ' ) По умолчанию KaggleHub сохраняет модель в каталоге ~/.cache/kagglehub .
from jora import ParagemmaConfig , train_lora_gemma , generate_alpaca_dataset_gemma
# model version in '2b', '2b-it', '7b', '7b-it' (2b-it, 7b-it for Gemma 1.1)
config = ParagemmaConfig ( GEMMA_MODEL_PATH = model_path , MODEL_VERSION = model_version )
dataset = generate_alpaca_dataset_gemma ( dataset_path , 'train' , config )
train_lora_gemma ( config , dataset , checkpoint_path )== Gemma 1.1 ==
Для моделей Gemma 1.1 Kagglehub сохраняет модель в следующей структуре каталога:
1.1-7b-it
├── 1
│ ├── 7b-it
│ └── tokenizer.model
└── 1.complete
Таким образом, config.MODEL_VERSION должен быть установлен на 7b-it для модели 1.1-7b-it .
Функция generate_alpaca_dataset используется для генерации набора данных из файла JSON FORMAT ALPACA. Это помогает в обучении формату инструктов, поскольку библиотека обрабатывает обработку, токенизацию и пакетирование набора данных. В качестве альтернативы, Dataset Torch и DataLoader можно использовать для пользовательских наборов данных.
У Hurgingface есть обширная экосистема. Поскольку наша библиотека использует JAX для обучения, полученная модель несовместима. Чтобы решить эту проблему, мы предоставляем подмодуль для преобразования обученной модели JAX обратно в формат HuggingFace.
Обученные веса Lora можно сначала объединить с исходными параметрами:
SYNOPSIS
python -m jora.lora.merge PARAMS_PATH LORA_PATH OUTPUT_PATH <flags>
POSITIONAL ARGUMENTS
PARAMS_PATH
Type: str
LORA_PATH
Type: str
OUTPUT_PATH
Type: str
FLAGS
-l, --llama2=LLAMA2
Default: False
-g, --gemma=GEMMA
Default: False
NOTES
You can also use flags syntax for POSITIONAL ARGUMENTS
SYNOPSIS
python -m jora.hf HUGGINGFACE_PATH JAX_PATH SAVE_PATH
DESCRIPTION
This function takes a huggingface llama model and replaces the q_proj and v_proj weights with the lora merged weights
POSITIONAL ARGUMENTS
HUGGINGFACE_PATH
Type: str
path to the huggingface llama model
JAX_PATH
Type: str
path to the lora merged params
SAVE_PATH
Type: str
path to save the updated huggingface llama model
NOTES
You can also use flags syntax for POSITIONAL ARGUMENTS
GUI можно использовать для обучения модели. Графический интерфейс запускается с запуска следующей команды:
python -m jora.gui| Графические процессоры | 1 | 2 | 4 | |
|---|---|---|---|---|
| Объятие лица Пефт с Microsoft Deepspeed Zero-3 | MEM (MB) | 20645,2 (39,81) | 23056 /23024 (14,63 / 29,29) | 23978 /23921 /23463 /23397 (47,87 / 50,39 / 31,96 / 17,46) |
| Производительность (Secs) | 4,56 (0,04) | 2,81 (0,02) | 5,45 (0,09) | |
| Джора (наша) | MEM (MB) | 23102 (0,00) | 16068 /16008 (0,00 / 0,00) | 11460 /11448 /11448 /11400 (0,0 / 0,00 / 0,00 / 0,00) |
| Производительность (Secs) | 0,19 (0,00) | 0,79 (0,00) | 0,44 (0,00) |
Есть несколько мест, где вклады будут оценены.
@misc { tahir2024jora ,
title = { JORA: JAX Tensor-Parallel LoRA Library for Retrieval Augmented Fine-Tuning } ,
author = { Anique Tahir and Lu Cheng and Huan Liu } ,
year = { 2024 } ,
eprint = { 2403.11366 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
}Реализация модели JAX Llama-2 с помощью Ayaka14732
Реализация модели Gemma Gemma Google DeepMind


