JORA
1.0.0
UPDATE (4/8/2024) : JORA sekarang mendukung model Gemma Google.
UPDATE (4/11/2024) : Dukungan Gemma 1.1 Ditambahkan
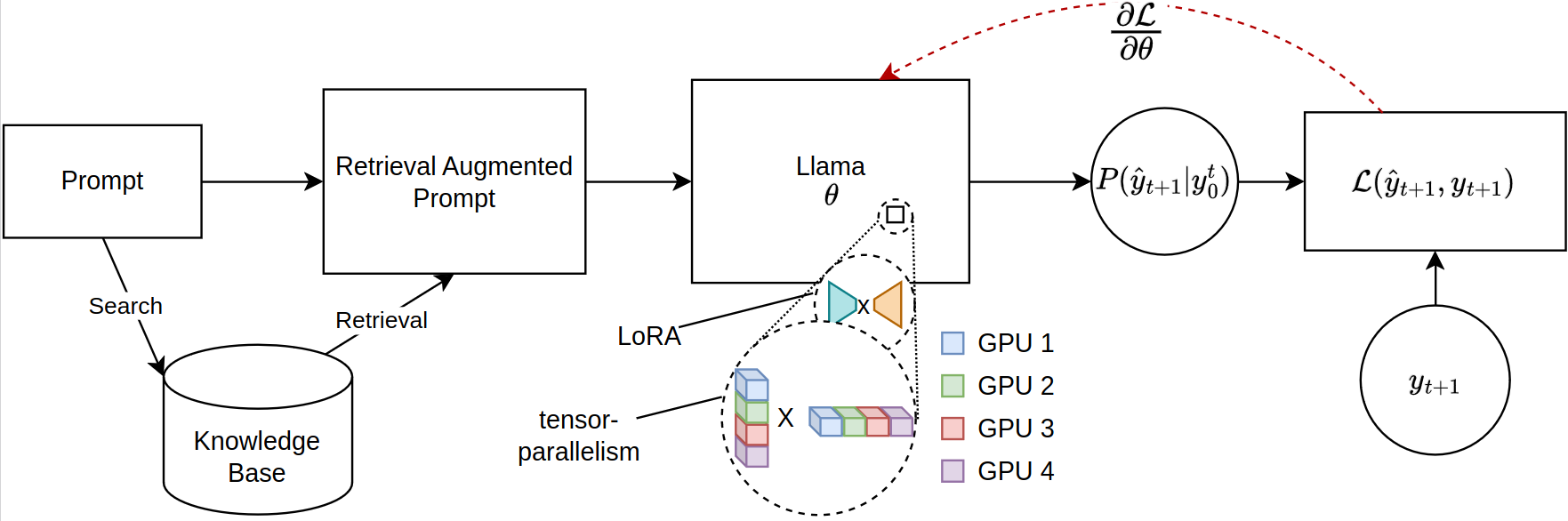
Penskalaan model bahasa besar (LLM) untuk tugas-tugas berbasis pengambilan, terutama dalam pengambilan augmented generasi (RAG), menghadapi kendala memori yang signifikan, terutama ketika menyempurnakan urutan cepat yang luas. Perpustakaan open-source saat ini mendukung inferensi model penuh dan penyempurnaan di beberapa GPU tetapi gagal mengakomodasi distribusi parameter yang efisien yang diperlukan untuk konteks yang diambil. Mengatasi kesenjangan ini, kami memperkenalkan kerangka kerja baru untuk penyempurnaan model LLAMA-2 yang kompatibel dengan PEFT, memanfaatkan pelatihan terdistribusi. Kerangka kerja kami secara unik menggunakan kompilasi JAX Just-in-time (JIT) dan sharding tensor untuk manajemen sumber daya yang efisien, sehingga memungkinkan penyesuaian yang dipercepat dengan berkurangnya persyaratan memori. Kemajuan ini secara signifikan meningkatkan skalabilitas dan kelayakan LLM yang menyempurnakan untuk aplikasi Rag yang kompleks, bahkan pada sistem dengan sumber daya GPU terbatas. Eksperimen kami menunjukkan lebih dari 12x peningkatan dalam runtime dibandingkan dengan pelukan memeluk wajah/implementasi kecepatan dalam dengan empat GPU sambil mengkonsumsi kurang dari setengah VRAM per GPU.
Harap pastikan Anda memiliki versi terbaru JAX untuk GPU yang diinstal. https://github.com/google/jax
Untuk menginstal paket, jalankan perintah berikut di direktori root repositori:
git clone https://github.com/aniquetahir/JORA.git
cd JORA
pip install -e .Pastikan Jax dapat mengakses GPU:
import jax
print ( jax . devices ())Perpustakaan dapat digunakan melalui Python, atau sebagai alternatif, GUI disediakan.
Kelas Parallama dapat digunakan untuk menentukan konfigurasi. Parameter yang masuk akal ditetapkan sebagai default.
class ParallamaConfig ( NamedTuple ):
JAX_PARAMS_PATH : str
LLAMA2_META_PATH : str # e.g. '/tmp/llama2-13B'
MODEL_SIZE : str # '7B', '13B', '70B'
NUM_GPUS : int = None
LORA_R : int = 16
LORA_ALPHA : int = 16
LORA_DROPOUT : float = 0.05
LR : float = 0.0001
BATCH_SIZE : int = 1
N_ACCUMULATION_STEPS : int = 8
MAX_SEQ_LEN = 2000
N_EPOCHS : int = 7
SEED : int = 420 Model berbasis Llama-2
from jora import train_lora , ParallamaConfig , generate_alpaca_dataset
config = ParallamaConfig ( MODEL_SIZE = model_size , JAX_PARAMS_PATH = jax_path ,
LLAMA2_META_PATH = hf_path )
dataset = generate_alpaca_dataset ( dataset_path , 'train' , config )
train_lora ( config , dataset , checkpoint_path )Model berbasis Gemma Model Gemma Flax dapat diunduh dari Kaggle:
import kagglehub
VARIANT = '2b-it' # @param ['2b', '2b-it', '7b', '7b-it', '1.1-2b-it', '1.1-7b-it'] {type:"string"}
weights_dir = kagglehub . model_download ( f'google/gemma/Flax/ { VARIANT } ' ) Secara default, Kagglehub menyimpan model di direktori ~/.cache/kagglehub .
from jora import ParagemmaConfig , train_lora_gemma , generate_alpaca_dataset_gemma
# model version in '2b', '2b-it', '7b', '7b-it' (2b-it, 7b-it for Gemma 1.1)
config = ParagemmaConfig ( GEMMA_MODEL_PATH = model_path , MODEL_VERSION = model_version )
dataset = generate_alpaca_dataset_gemma ( dataset_path , 'train' , config )
train_lora_gemma ( config , dataset , checkpoint_path )== Gemma 1.1 ==
Untuk model Gemma 1.1, Kagglehub menyimpan model dalam struktur direktori berikut:
1.1-7b-it
├── 1
│ ├── 7b-it
│ └── tokenizer.model
└── 1.complete
Jadi config.MODEL_VERSION harus diatur ke 7b-it untuk model 1.1-7b-it .
Fungsi generate_alpaca_dataset digunakan untuk menghasilkan dataset dari file json format alpaca. Ini membantu dengan pelatihan format instruksi karena pemrosesan dataset, tokenisasi, dan batching ditangani oleh perpustakaan. Atau, Dataset Obor dan DataLoader dapat digunakan untuk kumpulan data khusus.
Huggingface memiliki ekosistem yang luas. Karena perpustakaan kami menggunakan JAX untuk pelatihan, model yang dihasilkan tidak kompatibel. Untuk menyelesaikan masalah ini, kami menyediakan submodule untuk mengonversi model yang dilatih JAX kembali ke format Huggingface.
Bobot lora terlatih pertama -tama dapat digabungkan dengan parameter asli:
SYNOPSIS
python -m jora.lora.merge PARAMS_PATH LORA_PATH OUTPUT_PATH <flags>
POSITIONAL ARGUMENTS
PARAMS_PATH
Type: str
LORA_PATH
Type: str
OUTPUT_PATH
Type: str
FLAGS
-l, --llama2=LLAMA2
Default: False
-g, --gemma=GEMMA
Default: False
NOTES
You can also use flags syntax for POSITIONAL ARGUMENTS
SYNOPSIS
python -m jora.hf HUGGINGFACE_PATH JAX_PATH SAVE_PATH
DESCRIPTION
This function takes a huggingface llama model and replaces the q_proj and v_proj weights with the lora merged weights
POSITIONAL ARGUMENTS
HUGGINGFACE_PATH
Type: str
path to the huggingface llama model
JAX_PATH
Type: str
path to the lora merged params
SAVE_PATH
Type: str
path to save the updated huggingface llama model
NOTES
You can also use flags syntax for POSITIONAL ARGUMENTS
GUI dapat digunakan untuk melatih model. GUI dimulai dengan menjalankan perintah berikut:
python -m jora.gui| GPU | 1 | 2 | 4 | |
|---|---|---|---|---|
| Face Hugging Peft w/ Microsoft Deeppeed Zero-3 | MEM (MB) | 20645.2 (39.81) | 23056 /23024 (14.63 / 29.29) | 23978 /23921 /23463 /23397 (47.87 / 50.39 / 31.96 / 17.46) |
| Kinerja (SECS) | 4,56 (0,04) | 2.81 (0,02) | 5.45 (0,09) | |
| Jora (milik kami) | MEM (MB) | 23102 (0,00) | 16068 /16008 (0,00 / 0,00) | 11460 /11448 /11448 /11400 (0,0 / 0,00 / 0,00 / 0,00) |
| Kinerja (SECS) | 0,19 (0,00) | 0,79 (0,00) | 0,44 (0,00) |
Ada beberapa tempat di mana kontribusi akan dihargai.
@misc { tahir2024jora ,
title = { JORA: JAX Tensor-Parallel LoRA Library for Retrieval Augmented Fine-Tuning } ,
author = { Anique Tahir and Lu Cheng and Huan Liu } ,
year = { 2024 } ,
eprint = { 2403.11366 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
}Implementasi Model Jax Llama-2 oleh Ayaka14732
Implementasi Model Gemma Flax oleh Google DeepMind


