Tacotron pytorch
1.0.0
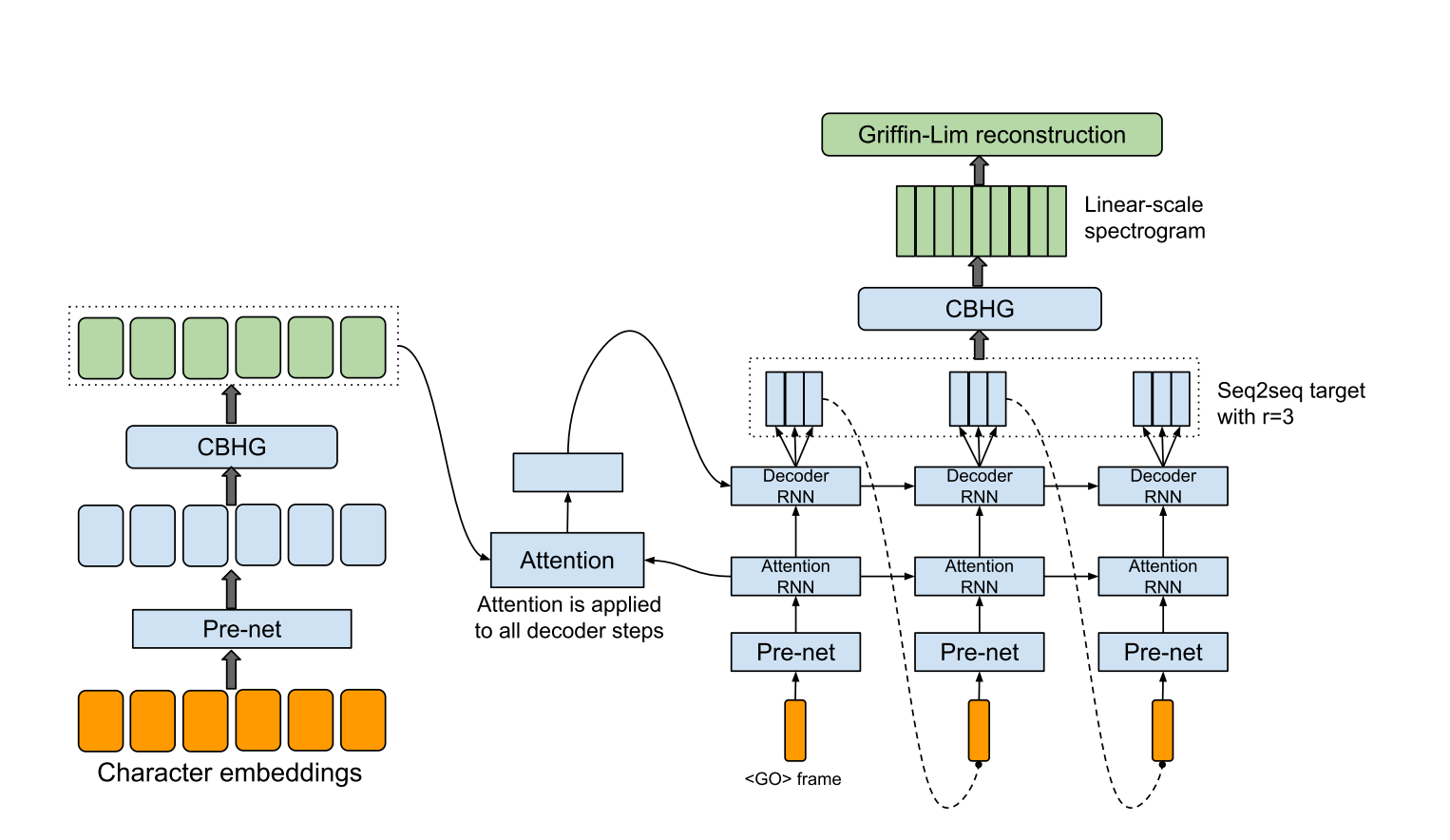
Tacotron的Pytorch實現:完全端到端的文本到語音合成模型。
pip install -r requirements.txt
我使用了由文本腳本和WAV文件對組成的LJSpeech數據集。可以在此處下載完整的數據集(13,100對)。我推薦了https://github.com/keithito/tacotron以進行預處理代碼。
hyperparams.py包含所有需要的超級參數。data.py將培訓數據和預處理文本加載到索引和WAV文件以進行頻譜圖。文本的預處理代碼在文本/目錄中。module.py包含所有方法,包括CBHG,Highway,Prenet等。network.py包含網絡,包括編碼器,解碼器和後處理網絡。train.py用於培訓。synthesis.py用於生成TTS樣品。 hyperparams.py中調整超參數,尤其是“ data_path”,這是您提取文件的目錄,以及如有必要的目錄。train.py 。 synthesis.py 。確保還原步驟。 

