Tacotron pytorch
1.0.0
タコトロンのPytorch実装:完全なエンドツーエンドのテキストからスピーチへの合成モデル。
pip install -r requirements.txt
テキストスクリプトとWAVファイルのペアで構成されるljspeechデータセットを使用しました。完全なデータセット(13,100ペア)はここからダウンロードできます。プリプロセシングコードについては、https://github.com/keithito/tacotronを紹介しました。
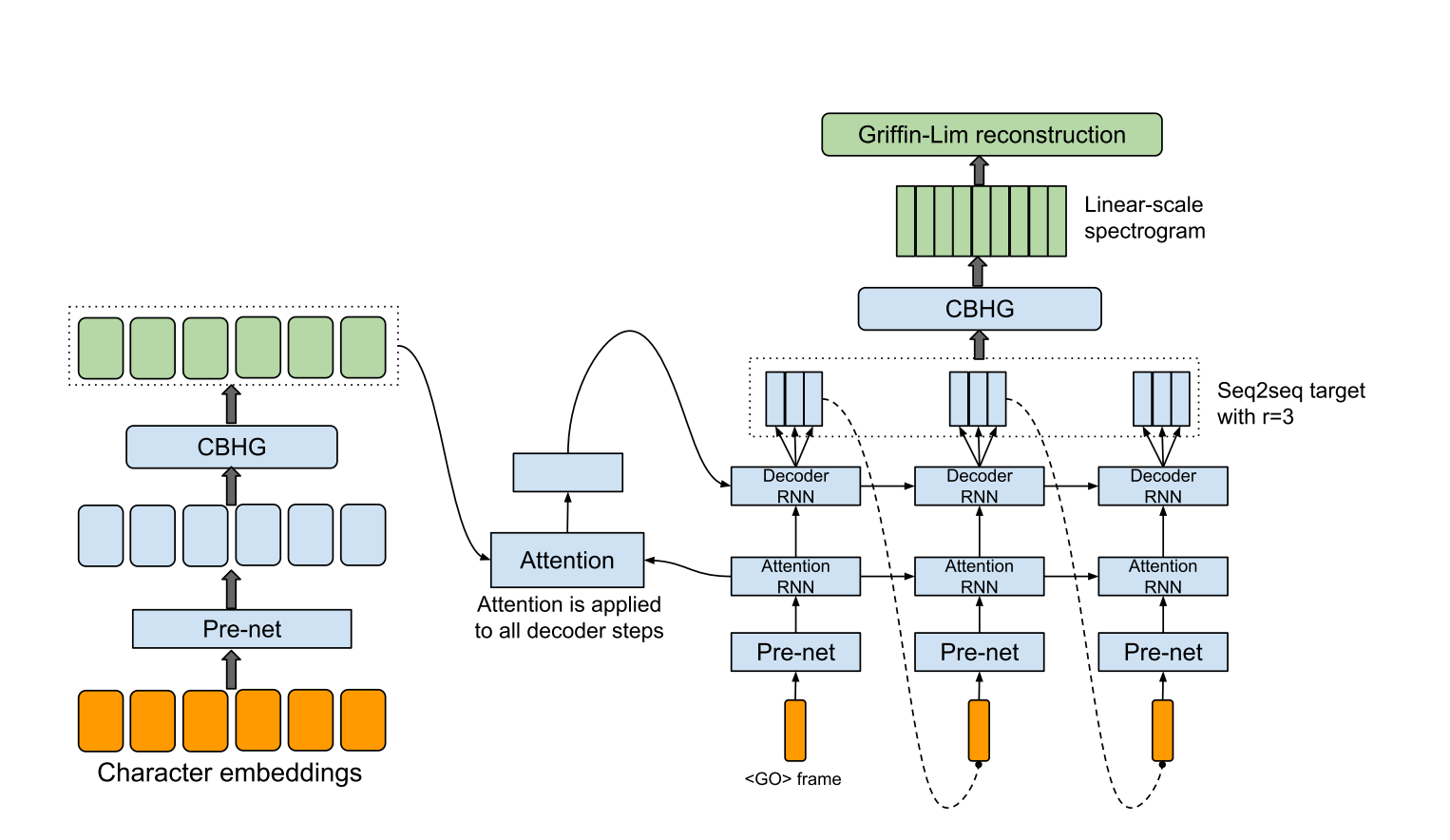
hyperparams.pyには、必要なすべてのハイパーパラメーターが含まれています。data.py 、トレーニングデータとプリプロセステキストをインデックスおよびWAVファイルにスペクトログラムにロードします。テキストの前処理コードはテキスト/ディレクトリにあります。module.pyは、CBHG、Highway、Prenetなどを含むすべての方法が含まれています。network.pyには、エンコーダー、デコーダー、ポストプロセッシングネットワークなどのネットワークが含まれています。train.pyはトレーニング用です。synthesis.pyは、TTSサンプルを生成するためのものです。 hyperparams.py 、特にファイルを抽出するディレクトリである「data_path」、および必要に応じてその他を調整します。train.py実行します。 synthesis.pyします。復元ステップを確認してください。 

