Tacotron pytorch
1.0.0
Une implémentation Pytorch de Tacotron: un modèle de synthèse de texte à dispection entièrement de bout en bout.
pip install -r requirements.txt
J'ai utilisé un ensemble de données LJSpeech qui se compose de paires de scripts texte et de fichiers WAV. L'ensemble de données complet (13 100 paires) peut être téléchargé ici. J'ai référé https://github.com/keithito/tacotron pour le code de prétraitement.
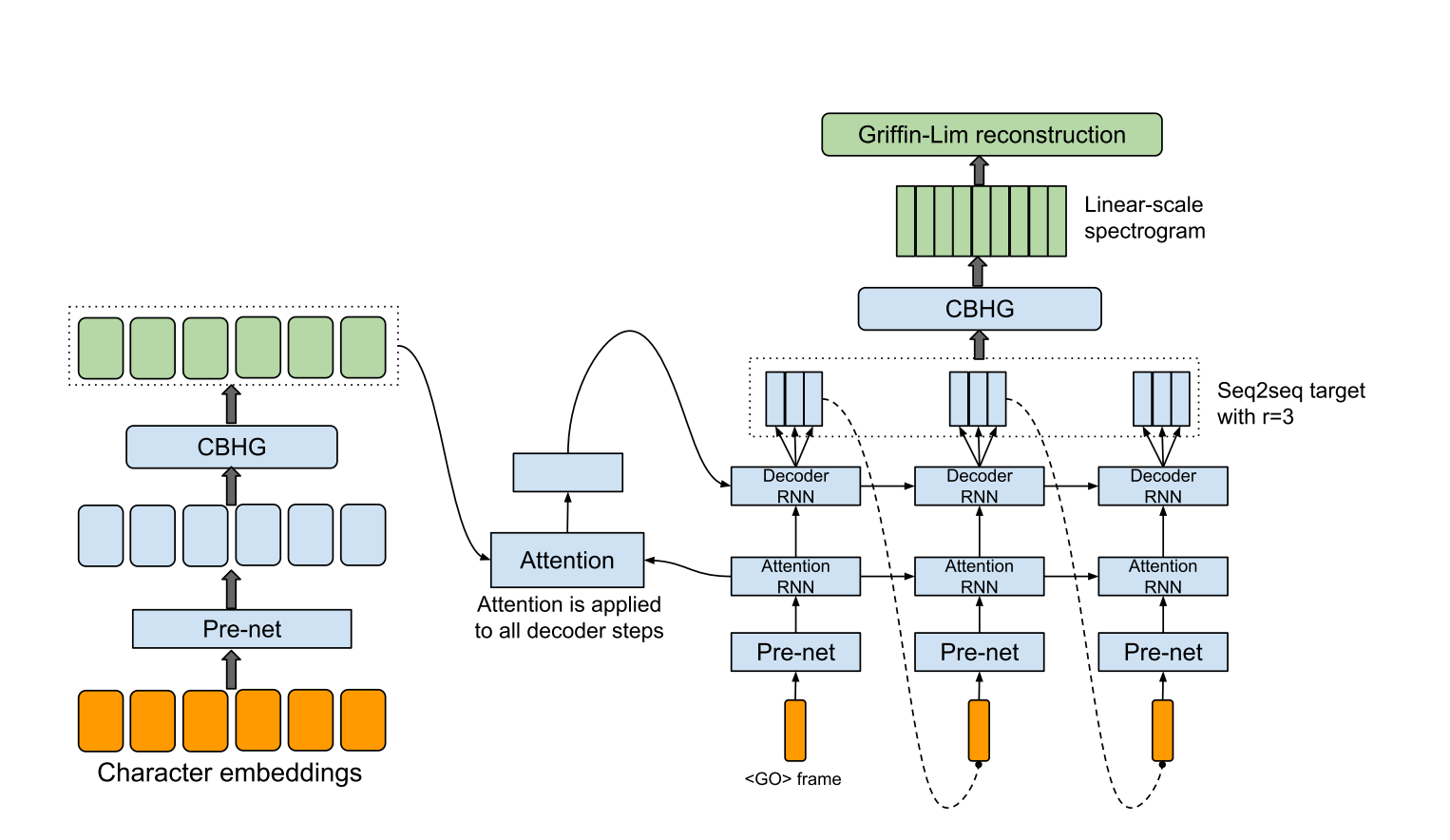
hyperparams.py comprend tous les paramètres hyper nécessaires.data.py charge les données de formation et le texte de prétraitement pour indexer et wav les fichiers vers le spectrogramme. Les codes de prétraitement pour le texte se trouvent dans le texte / répertoire.module.py contient toutes les méthodes, y compris CBHG, Highway, Prenet, etc.network.py contient des réseaux, y compris l'encodeur, le décodeur et le réseau de post-traitement.train.py est pour la formation.synthesis.py est pour générer un échantillon TTS. hyperparams.py , en particulier 'data_path' qui est un répertoire que vous extraire les fichiers, et les autres si nécessaire.train.py . synthesis.py . Assurez-vous que l'étape de restauration. 

