Tacotron pytorch
1.0.0
Una implementación de Pytorch de Tacotron: un modelo de síntesis de texto a discurso de extremo a extremo.
pip install -r requirements.txt
Utilicé el conjunto de datos LJSPEECch que consiste en pares de script de texto y archivos WAV. El conjunto de datos completo (13,100 pares) se puede descargar aquí. Referí https://github.com/keithito/tacotron para el código de preprocesamiento.
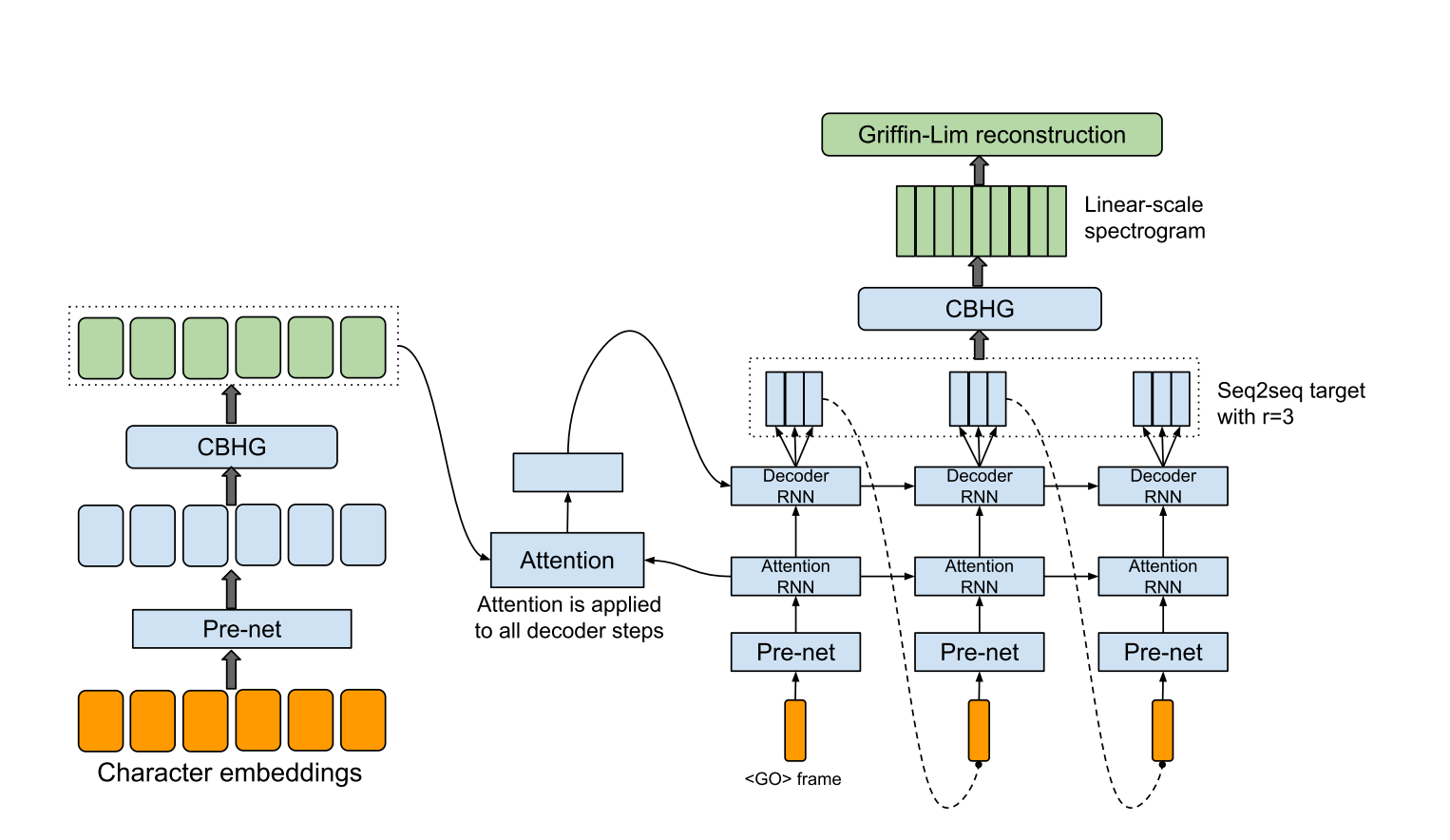
hyperparams.py incluye todos los parámetros Hyper que se necesitan.data.py Carga datos de entrenamiento y texto preprocesado para indexar y WAV archivos al espectrograma. Los códigos de preprocesamiento para el texto están en texto/ directorio.module.py contiene todos los métodos, incluidos CBHG, Highway, Prenet, etc.network.py contiene redes que incluyen el codificador, el decodificador y la red de postprocesamiento.train.py es para entrenamiento.synthesis.py es para generar una muestra TTS. hyperparams.py , especialmente 'data_path', que es un directorio que extrae archivos, y los demás si es necesario.train.py . synthesis.py . Asegúrese de que el paso de restauración. 

