Tacotron pytorch
1.0.0
Eine Pytorch-Implementierung von Tacotron: Ein vollständig End-to-End-Synthese-Modell von Text-to-Speech-Synthese.
pip install -r requirements.txt
Ich habe einen LJSpeech -Datensatz verwendet, der aus Textpaaren von Textskript- und WAV -Dateien besteht. Der vollständige Datensatz (13.100 Paare) kann hier heruntergeladen werden. Ich habe https://github.com/keithito/tacotron für den Vorverarbeitungscode verwiesen.
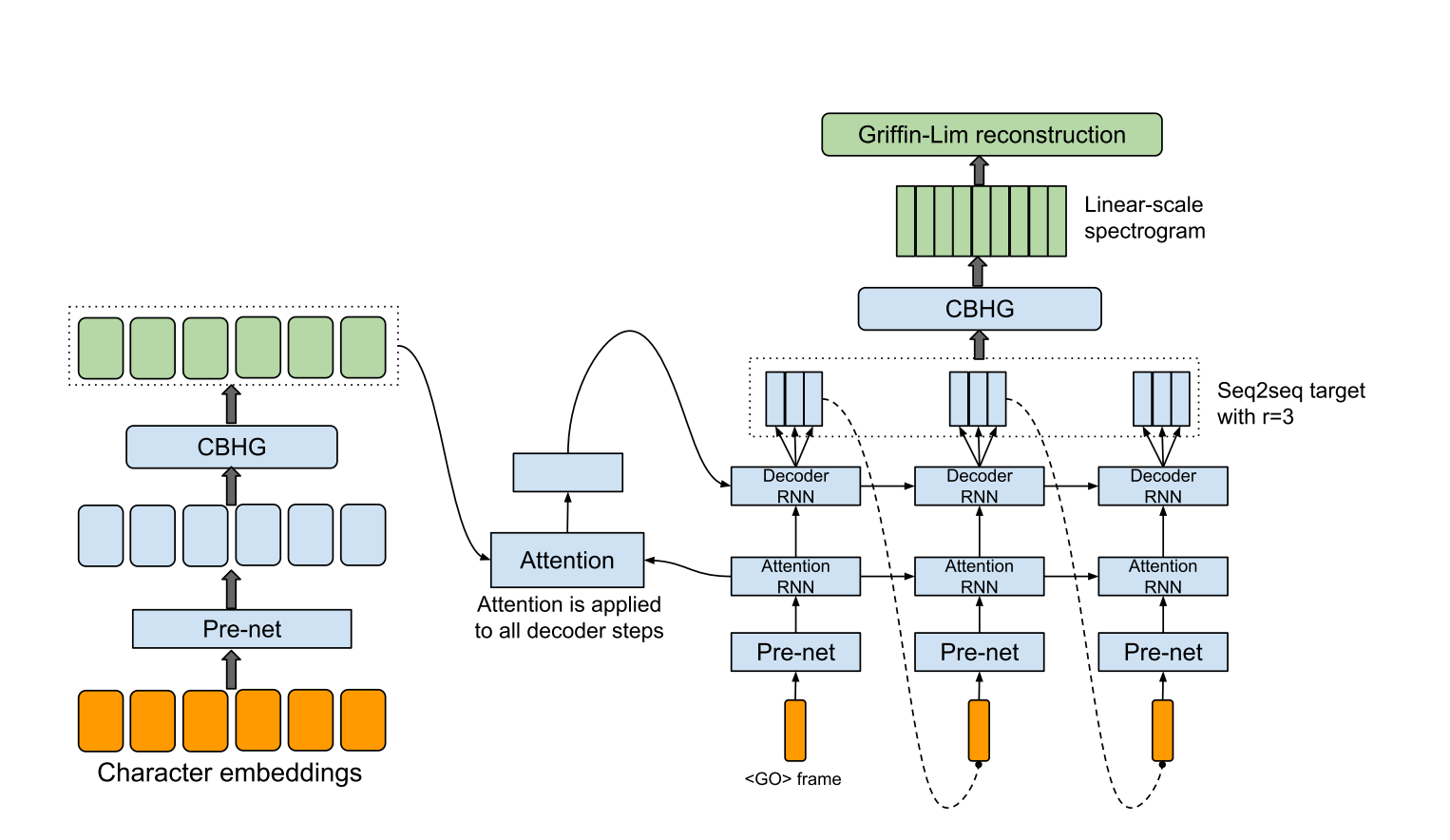
hyperparams.py enthält alle benötigten Hyperparameter.data.py lädt Trainingsdaten und Vorverarbeitungstext in die Index- und WAV -Dateien in das Spektrogramm. Die Vorverarbeitungscodes für Text befinden sich im Text/ Verzeichnis.module.py enthält alle Methoden, einschließlich CBHG, Autobahn, Prenet usw.network.py enthält Netzwerke wie Encoder, Decoder und Nachverarbeitungsnetzwerk.train.py ist für das Training.synthesis.py dient zur Erzeugung von TTS -Proben. hyperparams.py an, insbesondere in "Data_Path", ein Verzeichnis, das Sie bei Bedarf und die anderen extrahieren.train.py . synthesis.py . Stellen Sie sicher, dass der Wiederherstellungsschritt. 

