Tacotron pytorch
1.0.0
Implementasi Tacotron Pytorch: Model sintesis teks-ke-end-to-end sepenuhnya.
pip install -r requirements.txt
Saya menggunakan dataset ljspeech yang terdiri dari pasangan skrip teks dan file wav. Dataset lengkap (13.100 pasang) dapat diunduh di sini. Saya merujuk https://github.com/keithito/tacotron untuk kode preprocessing.
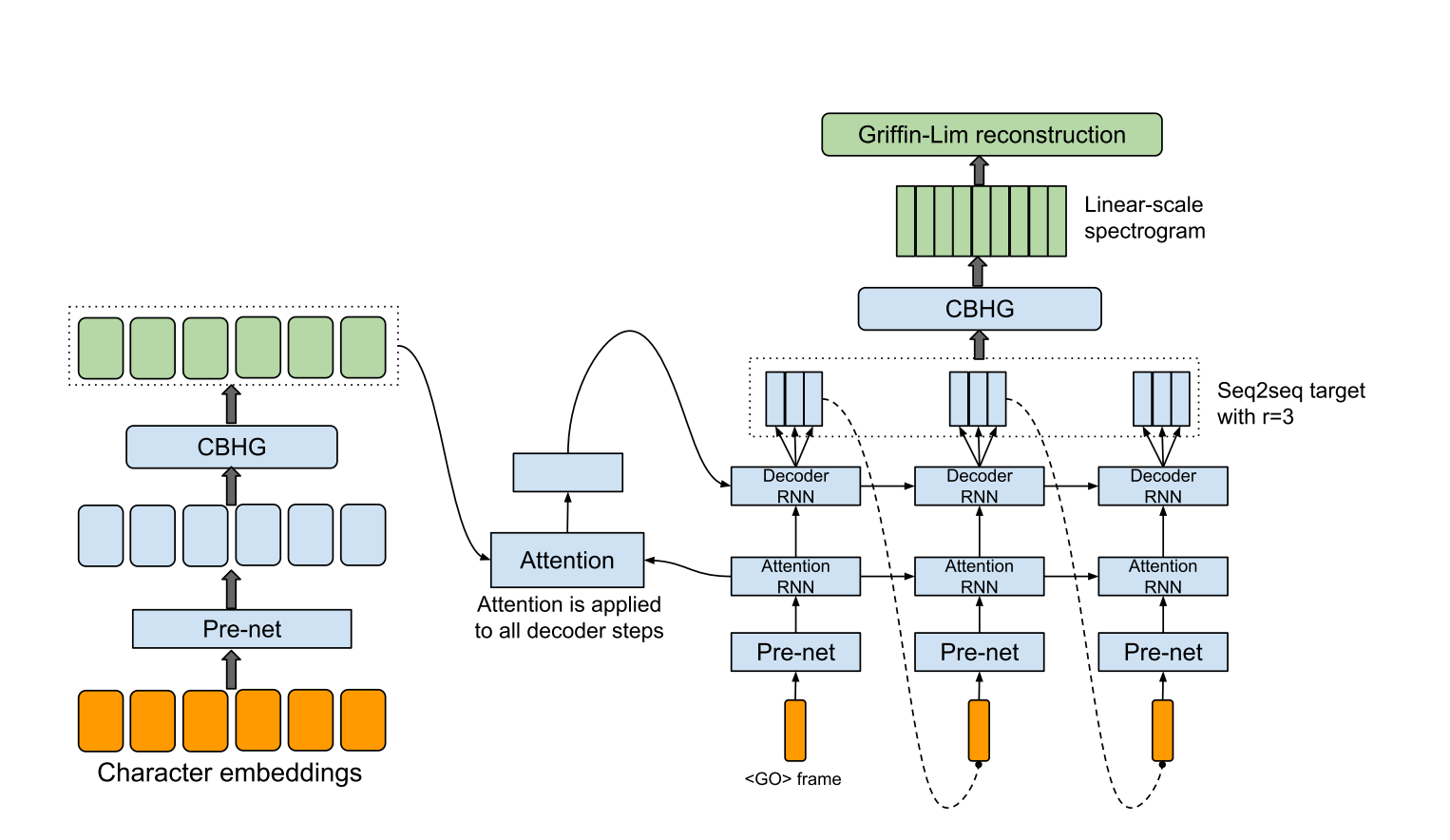
hyperparams.py mencakup semua parameter hiper yang diperlukan.data.py memuat data pelatihan dan teks preprocess ke indeks dan file wav ke spectrogram. Kode preprocessing untuk teks ada dalam teks/ direktori.module.py berisi semua metode, termasuk CBHG, Highway, Prenet, dan sebagainya.network.py berisi jaringan termasuk encoder, decoder dan jaringan pasca pemrosesan.train.py adalah untuk pelatihan.synthesis.py adalah untuk menghasilkan sampel TTS. hyperparams.py , terutama 'data_path' yang merupakan direktori yang Anda ekstrak file, dan yang lainnya jika perlu.train.py . synthesis.py . Pastikan langkah pemulihan. 

