AdderNet
1.0.0
該代碼是CVPR 2020紙addernet的演示:在深度學習中我們真的需要乘法嗎?
我們向深度神經網絡(尤其是卷積神經網絡(CNN))中的大規模乘法提供了加法網絡(ADDERNETS),以降低計算成本,以更便宜。在Addernets中,我們將過濾器和輸入功能之間的L1-標記距離作為輸出響應。結果,提出的addernets可以在ImageNet數據集上使用Resnet-50實現74.9%的TOP-1精度91.7%TOP-5精度,而無需在卷積層中任何乘法。
運行python main.py進行CIFAR-10訓練。
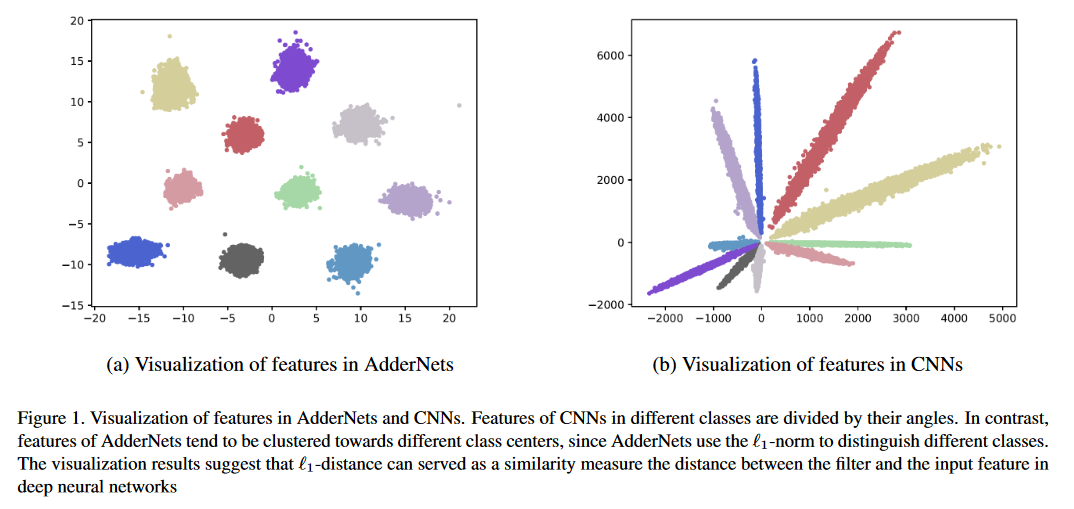
CIFAR-10和CIFAR-100數據集上的分類結果。
| 模型 | 方法 | CIFAR-10 | CIFAR-100 |
|---|---|---|---|
| vgg-small | 安 | 93.72% | 72.64% |
| PKKD Ann | 95.03% | 76.94% | |
| Slac Ann | 93.96% | 73.63% | |
| Resnet-20 | 安 | 92.02% | 67.60% |
| PKKD Ann | 92.96% | 69.93% | |
| Slac Ann | 92.29% | 68.31% | |
| ShiftAddnet* | 89.32%(160epoch) | - | |
| Resnet-32 | 安 | 93.01% | 69.17% |
| PKKD Ann | 93.62% | 72.41% | |
| Slac Ann | 93.24% | 69.83% |
Imagenet數據集上的分類結果。
| 模型 | 方法 | TOP-1 ACC | 前5個ACC |
|---|---|---|---|
| Resnet-18 | CNN | 69.8% | 89.1% |
| 安 | 67.0% | 87.6% | |
| PKKD Ann | 68.8% | 88.6% | |
| Slac Ann | 67.7% | 87.9% | |
| Resnet-50 | CNN | 76.2% | 92.9% |
| 安 | 74.9% | 91.7% | |
| PKKD Ann | 76.8% | 93.3% | |
| Slac Ann | 75.3% | 92.6% |
*ShiftAddnet使用了不同的訓練設置。
多個SR數據集的超分辨率結果。
| 規模 | 模型 | 方法 | set5(psnr/ssim) | set14(psnr/ssim) | B100(PSNR/SSIM) | Urban100(PSNR/SSIM) |
|---|---|---|---|---|---|---|
| ×2 | VDSR | CNN | 37.53/0.9587 | 33.03/0.9124 | 31.90/0.8960 | 30.76/0.9140 |
| 安 | 37.37/0.9575 | 32.91/0.9112 | 31.82/0.8947 | 30.48/0.9099 | ||
| EDSR | CNN | 38.11/0.9601 | 33.92/0.9195 | 32.32/0.9013 | 32.93/0.9351 | |
| 安 | 37.92/0.9589 | 33.82/0.9183 | 32.23/0.9000 | 32.63/0.9309 | ||
| ×3 | VDSR | CNN | 33.66/0.9213 | 29.77/0.8314 | 28.82/0.7976 | 27.14/0.8279 |
| 安 | 33.47/0.9151 | 29.62/0.8276 | 28.72/0.7953 | 26.95/0.8189 | ||
| EDSR | CNN | 34.65/0.9282 | 30.52/0.8462 | 29.25/0.8093 | 28.80/0.8653 | |
| 安 | 34.35/0.9212 | 30.33/0.8420 | 29.13/0.8068 | 28.54/0.8555 | ||
| ×4 | VDSR | CNN | 31.35/0.8838 | 28.01/0.7674 | 27.29/0.7251 | 25.18/0.7524 |
| 安 | 31.27/0.8762 | 27.93/0.7630 | 27.25/0.7229 | 25.09/0.7445 | ||
| EDSR | CNN | 32.46/0.8968 | 28.80/0.7876 | 27.71/0.7420 | 26.64/0.8033 | |
| 安 | 32.13/0.8864 | 28.57/0.7800 | 27.58/0.7368 | 26.33/0.7874 |
在沒有對抗訓練的情況下,在白色盒子攻擊下,CIFAR-10對CIFAR-10的對抗性魯棒性。
| 模型 | 方法 | 乾淨的 | FGSM | BIM7 | PGD7 | MIM5 | RFGSM5 |
|---|---|---|---|---|---|---|---|
| Resnet-20 | CNN | 92.68 | 16.33 | 0.00 | 0.00 | 0.01 | 0.00 |
| 安 | 91.72 | 18.42 | 0.00 | 0.00 | 0.04 | 0.00 | |
| CNN-R | 90.62 | 17.23 | 3.46 | 3.67 | 4.23 | 0.06 | |
| Ann-R | 90.95 | 29.93 | 29.30 | 29.72 | 32.25 | 3.38 | |
| Ann-r-awn | 90.55 | 45.93 | 42.62 | 43.39 | 46.52 | 18.36 | |
| Resnet-32 | CNN | 92.78 | 23.55 | 0.00 | 0.01 | 0.10 | 0.00 |
| 安 | 92.48 | 35.85 | 0.03 | 0.11 | 1.04 | 0.02 | |
| CNN-R | 91.32 | 20.41 | 5.15 | 5.27 | 6.09 | 0.07 | |
| Ann-R | 91.68 | 19.74 | 15.96 | 16.08 | 17.48 | 0.07 | |
| Ann-r-awn | 91.25 | 61.30 | 59.41 | 59.74 | 61.54 | 39.79 |
Pascal VOC的地圖比較。
| 模型 | 骨幹 | 脖子 | 地圖 |
|---|---|---|---|
| 更快的R-CNN | Conv R50 | cons | 79.5 |
| FCO | Conv R50 | cons | 79.1 |
| 視網膜 | Conv R50 | cons | 77.3 |
| Foveabox | Conv R50 | cons | 76.6 |
| adder-fcos | 加法器R50 | 加法器 | 76.5 |
您可以按照Pytorch/示例來準備ImageNet數據。
驗證的型號可在Google Drive或Baidu Cloud(訪問代碼:126B)中找到
運行python main.py進行CIFAR-10訓練。
運行python test.py --data_dir 'path/to/imagenet_root/'以對Imagenet val設置進行評估。使用Resnet-50,您將在Imagenet數據集上實現74.9%的最高準確性和91.7%的TOP-5精度。
運行python test.py --dataset cifar10 --model_dir models/ResNet20-AdderNet.pth --data_dir 'path/to/cifar10_root/'在CIFAR-10上進行評估。您將使用Resnet-20在CIFAR-10數據集上實現91.8%的精度。
由於在沒有CUDA加速的情況下實施了加法器過濾器,因此對Addernets的推斷和培訓很慢。您可以編寫CUDA以達到更高的推理速度。
@article{AdderNet,
title={AdderNet: Do We Really Need Multiplications in Deep Learning?},
author={Chen, Hanting and Wang, Yunhe and Xu, Chunjing and Shi, Boxin and Xu, Chao and Tian, Qi and Xu, Chang},
journal={CVPR},
year={2020}
}
我們感謝所有貢獻。如果您打算貢獻較小的錯誤,請這樣做,而無需進行任何進一步的討論。
如果您打算為核心貢獻新功能,實用功能或擴展,請首先與我們開放問題並討論該功能。發送無討論的公關可能最終導致拒絕的PR,因為我們可能會將核心朝著與您可能意識到的不同方向不同。


