AdderNet
1.0.0
Este código es una demostración de Adddernet de papel CVPR 2020: ¿realmente necesitamos multiplicaciones en el aprendizaje profundo?
Presentamos las redes de Adder (Addernets) para intercambiar multiplicaciones masivas en redes neuronales profundas, especialmente redes neuronales convolucionales (CNN), para adiciones mucho más baratas para reducir los costos de cálculo. En Addernets, tomamos la distancia de la norma L1 entre los filtros y la función de entrada como respuesta de salida. Como resultado, los Addernets propuestos pueden alcanzar el 74.9% de precisión de Top-1 91.7% Top-5 Precisión utilizando Resnet-50 en el conjunto de datos ImageNet sin ninguna multiplicación en la capa de convolución.
Ejecute python main.py para entrenar en CIFAR-10.
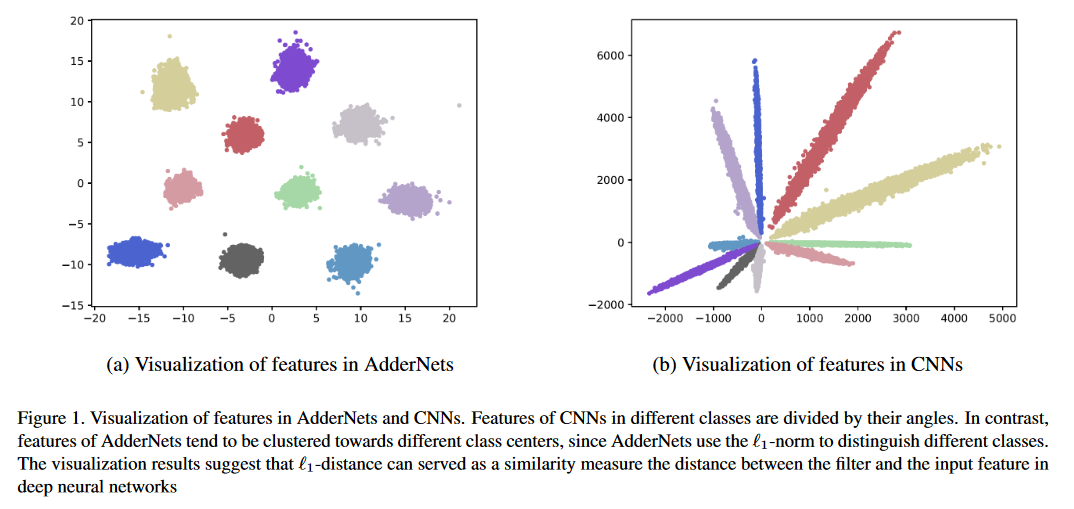
Resultados de clasificación en conjuntos de datos CIFAR-10 y CIFAR-100.
| Modelo | Método | Cifar-10 | Cifar-100 |
|---|---|---|---|
| Vgg-pequeño | ANA | 93.72% | 72.64% |
| PKKD Ann | 95.03% | 76.94% | |
| Slac Ann | 93.96% | 73.63% | |
| Resnet-20 | ANA | 92.02% | 67.60% |
| PKKD Ann | 92.96% | 69.93% | |
| Slac Ann | 92.29% | 68.31% | |
| Shiftdnet* | 89.32%(160 °) | - | |
| Resnet-32 | ANA | 93.01% | 69.17% |
| PKKD Ann | 93.62% | 72.41% | |
| Slac Ann | 93.24% | 69.83% |
Resultados de clasificación en el conjunto de datos de ImageNet.
| Modelo | Método | Top-1 ACC | Top-5 ACC |
|---|---|---|---|
| Resnet-18 | CNN | 69.8% | 89.1% |
| ANA | 67.0% | 87.6% | |
| PKKD Ann | 68.8% | 88.6% | |
| Slac Ann | 67.7% | 87.9% | |
| Resnet-50 | CNN | 76.2% | 92.9% |
| ANA | 74.9% | 91.7% | |
| PKKD Ann | 76.8% | 93.3% | |
| Slac Ann | 75.3% | 92.6% |
*ShiftDnet usó una configuración de entrenamiento diferente.
Resultados de súper resolución en varios conjuntos de datos SR.
| Escala | Modelo | Método | Set5 (PSNR/SSIM) | Set14 (PSNR/SSIM) | B100 (PSNR/SSIM) | Urban100 (PSNR/SSIM) |
|---|---|---|---|---|---|---|
| × 2 | VDSR | CNN | 37.53/0.9587 | 33.03/0.9124 | 31.90/0.8960 | 30.76/0.9140 |
| ANA | 37.37/0.9575 | 32.91/0.9112 | 31.82/0.8947 | 30.48/0.9099 | ||
| Edsr | CNN | 38.11/0.9601 | 33.92/0.9195 | 32.32/0.9013 | 32.93/0.9351 | |
| ANA | 37.92/0.9589 | 33.82/0.9183 | 32.23/0.9000 | 32.63/0.9309 | ||
| × 3 | VDSR | CNN | 33.66/0.9213 | 29.77/0.8314 | 28.82/0.7976 | 27.14/0.8279 |
| ANA | 33.47/0.9151 | 29.62/0.8276 | 28.72/0.7953 | 26.95/0.8189 | ||
| Edsr | CNN | 34.65/0.9282 | 30.52/0.8462 | 29.25/0.8093 | 28.80/0.8653 | |
| ANA | 34.35/0.9212 | 30.33/0.8420 | 29.13/0.8068 | 28.54/0.8555 | ||
| × 4 | VDSR | CNN | 31.35/0.8838 | 28.01/0.7674 | 27.29/0.7251 | 25.18/0.7524 |
| ANA | 31.27/0.8762 | 27.93/0.7630 | 27.25/0.7229 | 25.09/0.7445 | ||
| Edsr | CNN | 32.46/0.8968 | 28.80/0.7876 | 27.71/0.7420 | 26.64/0.8033 | |
| ANA | 32.13/0.8864 | 28.57/0.7800 | 27.58/0.7368 | 26.33/0.7874 |
Robustez adversa en CIFAR-10 bajo ataques de caja blanca sin entrenamiento adversario.
| Modelo | Método | Limpio | FGSM | Bim7 | PGD7 | Mim5 | RFGSM5 |
|---|---|---|---|---|---|---|---|
| Resnet-20 | CNN | 92.68 | 16.33 | 0.00 | 0.00 | 0.01 | 0.00 |
| ANA | 91.72 | 18.42 | 0.00 | 0.00 | 0.04 | 0.00 | |
| CNN-R | 90.62 | 17.23 | 3.46 | 3.67 | 4.23 | 0.06 | |
| Ann-R | 90.95 | 29.93 | 29.30 | 29.72 | 32.25 | 3.38 | |
| Ann-R-ADH | 90.55 | 45.93 | 42.62 | 43.39 | 46.52 | 18.36 | |
| Resnet-32 | CNN | 92.78 | 23.55 | 0.00 | 0.01 | 0.10 | 0.00 |
| ANA | 92.48 | 35.85 | 0.03 | 0.11 | 1.04 | 0.02 | |
| CNN-R | 91.32 | 20.41 | 5.15 | 5.27 | 6.09 | 0.07 | |
| Ann-R | 91.68 | 19.74 | 15.96 | 16.08 | 17.48 | 0.07 | |
| Ann-R-ADH | 91.25 | 61.30 | 59.41 | 59.74 | 61.54 | 39.79 |
Comparaciones del mapa en Pascal VOC.
| Modelo | Columna vertebral | Cuello | mapa |
|---|---|---|---|
| R-CNN más rápido | Conv r50 | Convencer | 79.5 |
| FCOS | Conv r50 | Convencer | 79.1 |
| Retinanet | Conv r50 | Convencer | 77.3 |
| Foveabox | Conv r50 | Convencer | 76.6 |
| Adder-fcos | Adder R50 | Sumador | 76.5 |
Puede seguir a Pytorch/ejemplos para preparar los datos de ImageNet.
Los modelos previos a la aparición están disponibles en Google Drive o Baidu Cloud (código de acceso: 126b)
Ejecute python main.py para entrenar en CIFAR-10.
Ejecute python test.py --data_dir 'path/to/imagenet_root/' para evaluar en el conjunto de imagenet val . Logrará un 74.9% de precisión superior y 91.7% de precisión top-5 en el conjunto de datos de ImageNet usando Resnet-50.
Ejecute python test.py --dataset cifar10 --model_dir models/ResNet20-AdderNet.pth --data_dir 'path/to/cifar10_root/' para evaluar en CIFAR-10. Logrará una precisión del 91.8% en el conjunto de datos CIFAR-10 utilizando Resnet-20.
La inferencia y la capacitación de Addernets es lento ya que los filtros de Adder se implementan sin aceleración CUDA. Puede escribir CUDA para lograr una mayor velocidad de inferencia.
@article{AdderNet,
title={AdderNet: Do We Really Need Multiplications in Deep Learning?},
author={Chen, Hanting and Wang, Yunhe and Xu, Chunjing and Shi, Boxin and Xu, Chao and Tian, Qi and Xu, Chang},
journal={CVPR},
year={2020}
}
Apreciamos todas las contribuciones. Si planea contribuir con las fiajas de errores, hágalo sin más discusión.
Si planea contribuir con nuevas funciones, funciones de utilidad o extensiones al núcleo, primero abra un problema y discuta la función con nosotros. Enviar un PR sin discusión podría terminar resultando en un PR rechazado, porque podríamos estar tomando el núcleo en una dirección diferente de lo que podría tener en cuenta.


