AdderNet
1.0.0
Kode ini adalah demo dari CVPR 2020 Paper Addernet: Apakah kita benar -benar membutuhkan multiplikasi dalam pembelajaran yang mendalam?
Kami menyajikan jaringan adder (AdderNets) untuk memperdagangkan multiplikasi besar -besaran dalam jaringan saraf yang dalam, terutama jaringan saraf konvolusional (CNN), untuk penambahan yang jauh lebih murah untuk mengurangi biaya perhitungan. Di Addernets, kami mengambil jarak L1-norm antara filter dan fitur input sebagai respons output. Akibatnya, Addernets yang diusulkan dapat mencapai akurasi top-1 74,9% 91,7% akurasi top-5 menggunakan ResNet-50 pada dataset Imagenet tanpa perkalian apa pun di lapisan konvolusi.
Jalankan python main.py untuk berlatih di CIFAR-10.
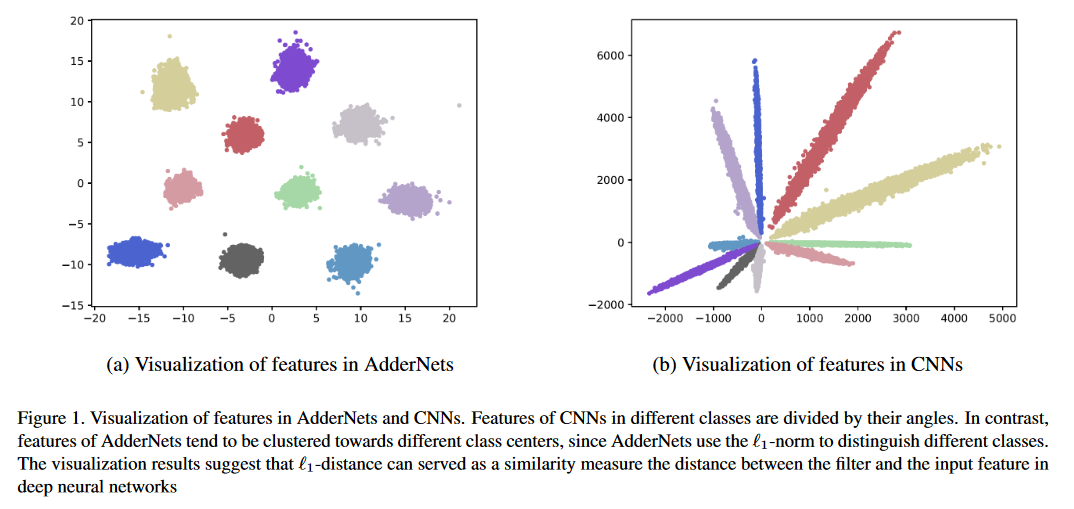
Hasil klasifikasi pada dataset CIFAR-10 dan CIFAR-100.
| Model | Metode | CIFAR-10 | CIFAR-100 |
|---|---|---|---|
| Vgg-small | Ann | 93,72% | 72,64% |
| PKKD Ann | 95,03% | 76,94% | |
| Slac Ann | 93,96% | 73,63% | |
| Resnet-20 | Ann | 92,02% | 67,60% |
| PKKD Ann | 92,96% | 69,93% | |
| Slac Ann | 92,29% | 68,31% | |
| Shiftaddnet* | 89,32%(160epoch) | - | |
| ResNet-32 | Ann | 93,01% | 69,17% |
| PKKD Ann | 93,62% | 72,41% | |
| Slac Ann | 93,24% | 69,83% |
Hasil klasifikasi pada dataset Imagenet.
| Model | Metode | Top-1 Acc | Top-5 Acc |
|---|---|---|---|
| Resnet-18 | CNN | 69,8% | 89,1% |
| Ann | 67,0% | 87,6% | |
| PKKD Ann | 68,8% | 88,6% | |
| Slac Ann | 67,7% | 87,9% | |
| ResNet-50 | CNN | 76,2% | 92,9% |
| Ann | 74,9% | 91,7% | |
| PKKD Ann | 76,8% | 93,3% | |
| Slac Ann | 75,3% | 92,6% |
*ShiftAddnet menggunakan pengaturan pelatihan yang berbeda.
Hasil resolusi super pada beberapa dataset SR.
| Skala | Model | Metode | Set5 (psnr/ssim) | Set14 (psnr/ssim) | B100 (PSNR/SSIM) | Urban100 (PSNR/SSIM) |
|---|---|---|---|---|---|---|
| × 2 | VDSR | CNN | 37.53/0.9587 | 33.03/0.9124 | 31.90/0.8960 | 30.76/0.9140 |
| Ann | 37.37/0.9575 | 32.91/0.9112 | 31.82/0.8947 | 30.48/0.9099 | ||
| Edsr | CNN | 38.11/0.9601 | 33.92/0.9195 | 32.32/0.9013 | 32.93/0.9351 | |
| Ann | 37.92/0.9589 | 33.82/0.9183 | 32.23/0.9000 | 32.63/0.9309 | ||
| × 3 | VDSR | CNN | 33.66/0.9213 | 29.77/0.8314 | 28.82/0.7976 | 27.14/0.8279 |
| Ann | 33.47/0.9151 | 29.62/0.8276 | 28.72/0.7953 | 26.95/0.8189 | ||
| Edsr | CNN | 34.65/0.9282 | 30.52/0.8462 | 29.25/0.8093 | 28.80/0.8653 | |
| Ann | 34.35/0.9212 | 30.33/0.8420 | 29.13/0.8068 | 28.54/0.8555 | ||
| × 4 | VDSR | CNN | 31.35/0.8838 | 28.01/0.7674 | 27.29/0.7251 | 25.18/0.7524 |
| Ann | 31.27/0.8762 | 27.93/0.7630 | 27.25/0.7229 | 25.09/0.7445 | ||
| Edsr | CNN | 32.46/0.8968 | 28.80/0.7876 | 27.71/0.7420 | 26.64/0.8033 | |
| Ann | 32.13/0.8864 | 28.57/0.7800 | 27.58/0.7368 | 26.33/0.7874 |
Ketahanan yang bermusuhan pada CIFAR-10 di bawah serangan kotak putih tanpa pelatihan permusuhan.
| Model | Metode | Membersihkan | FGSM | Bim7 | PGD7 | Mim5 | RFGSM5 |
|---|---|---|---|---|---|---|---|
| Resnet-20 | CNN | 92.68 | 16.33 | 0,00 | 0,00 | 0,01 | 0,00 |
| Ann | 91.72 | 18.42 | 0,00 | 0,00 | 0,04 | 0,00 | |
| CNN-R | 90.62 | 17.23 | 3.46 | 3.67 | 4.23 | 0,06 | |
| Ann-r | 90.95 | 29.93 | 29.30 | 29.72 | 32.25 | 3.38 | |
| Ann-r-Awn | 90.55 | 45.93 | 42.62 | 43.39 | 46.52 | 18.36 | |
| ResNet-32 | CNN | 92.78 | 23.55 | 0,00 | 0,01 | 0.10 | 0,00 |
| Ann | 92.48 | 35.85 | 0,03 | 0.11 | 1.04 | 0,02 | |
| CNN-R | 91.32 | 20.41 | 5.15 | 5.27 | 6.09 | 0,07 | |
| Ann-r | 91.68 | 19.74 | 15.96 | 16.08 | 17.48 | 0,07 | |
| Ann-r-Awn | 91.25 | 61.30 | 59.41 | 59.74 | 61.54 | 39.79 |
Perbandingan peta pada voc pascal.
| Model | Tulang punggung | Leher | peta |
|---|---|---|---|
| R-CNN lebih cepat | Konvisi R50 | Conv | 79.5 |
| Fcos | Konvisi R50 | Conv | 79.1 |
| Retinanet | Konvisi R50 | Conv | 77.3 |
| Foveabox | Konvisi R50 | Conv | 76.6 |
| Adder-fcos | Adder R50 | Adder | 76.5 |
Anda dapat mengikuti Pytorch/contoh untuk menyiapkan data Imagenet.
Model pretrained tersedia di Google Drive atau Baidu Cloud (Kode Akses: 126b)
Jalankan python main.py untuk berlatih di CIFAR-10.
Jalankan python test.py --data_dir 'path/to/imagenet_root/' untuk mengevaluasi pada set imagenet val . Anda akan mencapai akurasi teratas 74,9% dan akurasi Top-5 91,7% pada dataset Imagenet menggunakan ResNet-50.
Jalankan python test.py --dataset cifar10 --model_dir models/ResNet20-AdderNet.pth --data_dir 'path/to/cifar10_root/' untuk mengevaluasi pada cifar-10. Anda akan mencapai akurasi 91,8% pada dataset CIFAR-10 menggunakan ResNet-20.
Inferensi dan pelatihan Addernets lambat karena filter adder diimplementasikan tanpa akselerasi CUDA. Anda dapat menulis CUDA untuk mencapai kecepatan inferensi yang lebih tinggi.
@article{AdderNet,
title={AdderNet: Do We Really Need Multiplications in Deep Learning?},
author={Chen, Hanting and Wang, Yunhe and Xu, Chunjing and Shi, Boxin and Xu, Chao and Tian, Qi and Xu, Chang},
journal={CVPR},
year={2020}
}
Kami menghargai semua kontribusi. Jika Anda berencana untuk berkontribusi kembali perbaikan bug, silakan lakukan tanpa diskusi lebih lanjut.
Jika Anda berencana untuk menyumbangkan fitur baru, fungsi utilitas atau ekstensi ke inti, silakan buka masalah pertama dan diskusikan fitur dengan kami. Mengirim PR tanpa diskusi mungkin berakhir menghasilkan PR yang ditolak, karena kami mungkin mengambil inti ke arah yang berbeda dari yang mungkin Anda ketahui.


