AdderNet
1.0.0
Dieser Code ist eine Demo von CVPR 2020 Paper Addernet: Benötigen wir wirklich Multiplikationen im Deep Learning?
Wir präsentieren Adder -Netzwerke (AdderNets), um massive Multiplikationen in tiefen neuronalen Netzwerken, insbesondere Faltungsnetzwerken (CNNs), zu tauschen, um viel billigere Ergänzungen zur Reduzierung der Berechnungskosten zu senken. In Addernets nehmen wir den L1-Normabstand zwischen Filtern und Eingangsmerkmalen als Ausgangsantwort. Infolgedessen können die vorgeschlagenen Addernette eine Top-1-Genauigkeit von 74,9% 91,7% der Top-5-Genauigkeit unter Verwendung von RESNET-50 auf dem ImageNet-Datensatz ohne Multiplikation in Faltungsschicht erreichen.
Rennen Sie python main.py , um auf Cifar-10 zu trainieren.
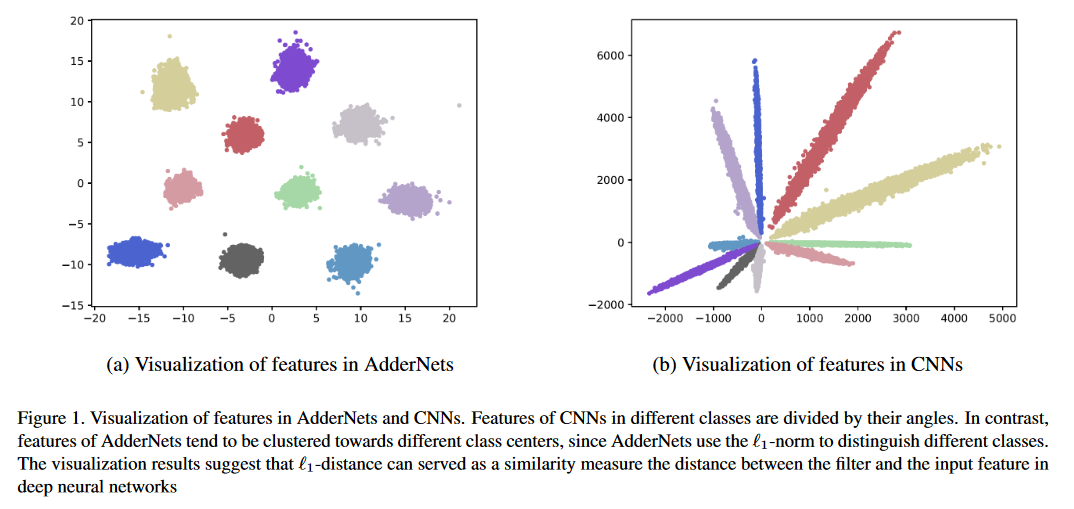
Klassifizierungsergebnisse zu CIFAR-10- und CIFAR-100-Datensätzen.
| Modell | Verfahren | CIFAR-10 | Cifar-100 |
|---|---|---|---|
| VGG-Small | Ann | 93,72% | 72,64% |
| Pkkd Ann | 95,03% | 76,94% | |
| Slac Ann | 93,96% | 73,63% | |
| Resnet-20 | Ann | 92,02% | 67,60% |
| Pkkd Ann | 92,96% | 69,93% | |
| Slac Ann | 92,29% | 68,31% | |
| ShiftAddnet* | 89,32%(160EPOCH) | - - | |
| Resnet-32 | Ann | 93,01% | 69,17% |
| Pkkd Ann | 93,62% | 72,41% | |
| Slac Ann | 93,24% | 69,83% |
Klassifizierungsergebnisse im ImageNet -Datensatz.
| Modell | Verfahren | Top-1 ACC | Top-5 ACC |
|---|---|---|---|
| Resnet-18 | CNN | 69,8% | 89,1% |
| Ann | 67,0% | 87,6% | |
| Pkkd Ann | 68,8% | 88,6% | |
| Slac Ann | 67,7% | 87,9% | |
| Resnet-50 | CNN | 76,2% | 92,9% |
| Ann | 74,9% | 91,7% | |
| Pkkd Ann | 76,8% | 93,3% | |
| Slac Ann | 75,3% | 92,6% |
*SHIFTADDNET hat eine unterschiedliche Trainingseinstellung verwendet.
Super-Auflösung Ergebnisse zu mehreren SR-Datensätzen.
| Skala | Modell | Verfahren | Set5 (psnr/ssim) | Set14 (psnr/ssim) | B100 (PSNR/SSIM) | Urban100 (PSNR/SSIM) |
|---|---|---|---|---|---|---|
| × 2 | Vdsr | CNN | 37,53/0,9587 | 33.03/0,9124 | 31.90/0,8960 | 30.76/0,9140 |
| Ann | 37,37/0,9575 | 32,91/0,9112 | 31.82/0,8947 | 30.48/0,9099 | ||
| Edsr | CNN | 38.11/0,9601 | 33,92/0,9195 | 32,32/0,9013 | 32,93/0,9351 | |
| Ann | 37,92/0,9589 | 33,82/0,9183 | 32,23/0,9000 | 32,63/0,9309 | ||
| × 3 | Vdsr | CNN | 33,66/0,9213 | 29,77/0,8314 | 28.82/0,7976 | 27.14/0,8279 |
| Ann | 33,47/0,9151 | 29,62/0,8276 | 28.72/0,7953 | 26.95/0,8189 | ||
| Edsr | CNN | 34,65/0,9282 | 30,52/0,8462 | 29,25/0,8093 | 28.80/0,8653 | |
| Ann | 34,35/0,9212 | 30.33/0,8420 | 29,13/0,8068 | 28.54/0,8555 | ||
| × 4 | Vdsr | CNN | 31.35/0,8838 | 28.01/0,7674 | 27.29/0,7251 | 25.18/0,7524 |
| Ann | 31.27/0,8762 | 27.93/0,7630 | 27.25/0,7229 | 25.09/0,7445 | ||
| Edsr | CNN | 32,46/0,8968 | 28.80/0,7876 | 27.71/0,7420 | 26.64/0,8033 | |
| Ann | 32.13/0,8864 | 28.57/0,7800 | 27.58/0,7368 | 26.33/0,7874 |
Gegentliche Robustheit bei CIFAR-10 unter White-Box-Angriffen ohne kontroverses Training.
| Modell | Verfahren | Sauber | FGSM | BIM7 | PGD7 | Mim5 | RFGSM5 |
|---|---|---|---|---|---|---|---|
| Resnet-20 | CNN | 92.68 | 16.33 | 0,00 | 0,00 | 0,01 | 0,00 |
| Ann | 91.72 | 18.42 | 0,00 | 0,00 | 0,04 | 0,00 | |
| CNN-R | 90.62 | 17.23 | 3.46 | 3.67 | 4.23 | 0,06 | |
| Ann-r | 90,95 | 29.93 | 29.30 | 29.72 | 32.25 | 3.38 | |
| Ann-r-Awn | 90,55 | 45,93 | 42.62 | 43.39 | 46,52 | 18.36 | |
| Resnet-32 | CNN | 92.78 | 23.55 | 0,00 | 0,01 | 0,10 | 0,00 |
| Ann | 92.48 | 35,85 | 0,03 | 0,11 | 1.04 | 0,02 | |
| CNN-R | 91.32 | 20.41 | 5.15 | 5.27 | 6.09 | 0,07 | |
| Ann-r | 91.68 | 19.74 | 15.96 | 16.08 | 17.48 | 0,07 | |
| Ann-r-Awn | 91.25 | 61.30 | 59.41 | 59.74 | 61.54 | 39.79 |
Vergleiche der Karte auf Pascal VOC.
| Modell | Rückgrat | Nacken | Karte |
|---|---|---|---|
| Schneller r-cnn | Überzeugen | Conc | 79,5 |
| Fcos | Überzeugen | Conc | 79.1 |
| Retinanet | Überzeugen | Conc | 77,3 |
| FoveAbox | Überzeugen | Conc | 76,6 |
| Adder-Fcos | Adder R50 | Addierer | 76,5 |
Sie können Pytorch/Beispielen befolgen, um die ImageNet -Daten vorzubereiten.
Die vorbereiteten Modelle sind in Google Drive oder Baidu Cloud (Zugriffscode: 126B) verfügbar.
Rennen Sie python main.py , um auf Cifar-10 zu trainieren.
Führen Sie python test.py --data_dir 'path/to/imagenet_root/' aus, um im ImageNet val -Satz zu bewerten. Sie erzielen mit ResNET-50 74,9% Top-Genauigkeit und 91,7% TOP-5-Genauigkeit im ImageNet-Datensatz.
Führen Sie python test.py --dataset cifar10 --model_dir models/ResNet20-AdderNet.pth --data_dir 'path/to/cifar10_root/' um CIFAR-10 zu bewerten. Sie erhalten eine Genauigkeit von 91,8% im CIFAR-10-Datensatz mit RESNET-20.
Die Schlussfolgerung und Schulung von Addernets ist langsam, da die Adderfilter ohne CUDA -Beschleunigung implementiert werden. Sie können CUDA schreiben, um eine höhere Inferenzgeschwindigkeit zu erreichen.
@article{AdderNet,
title={AdderNet: Do We Really Need Multiplications in Deep Learning?},
author={Chen, Hanting and Wang, Yunhe and Xu, Chunjing and Shi, Boxin and Xu, Chao and Tian, Qi and Xu, Chang},
journal={CVPR},
year={2020}
}
Wir schätzen alle Beiträge. Wenn Sie planen, Back-Bug-Fixes beizutragen, tun Sie dies bitte ohne weitere Diskussion.
Wenn Sie vorhaben, neue Funktionen, Versorgungsfunktionen oder Erweiterungen in den Kern beizutragen, eröffnen Sie bitte zunächst ein Problem und diskutieren Sie die Funktion mit uns. Wenn Sie eine PR ohne Diskussion senden, kann dies zu einer abgelehnten PR führen, da wir den Kern möglicherweise in eine andere Richtung nehmen, als Sie sich vielleicht bewusst sind.


