AdderNet
1.0.0
Este código é uma demonstração do CVPR 2020 Paper Addernet: Realmente precisamos de multiplicações no aprendizado profundo?
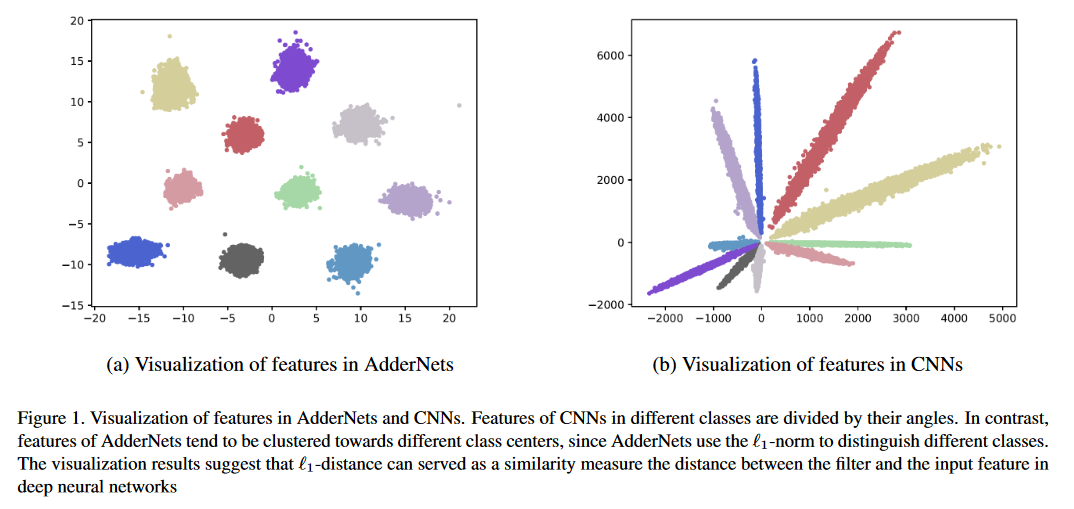
Apresentamos redes de Adder (AdderNets) para negociar multiplicações maciças em redes neurais profundas, especialmente redes neurais convolucionais (CNNs), para adições muito mais baratas para reduzir os custos de computação. Nos AdderNets, pegamos a distância L1-norma entre os filtros e o recurso de entrada como resposta de saída. Como resultado, os AdderNets propostos podem atingir 74,9% de precisão de 1 TOP-1 91,7% Top-5 precisão usando o ResNet-50 no conjunto de dados ImageNet sem qualquer multiplicação na camada de convolução.
Execute python main.py para treinar no CIFAR-10.
Resultados de classificação nos conjuntos de dados CIFAR-10 e CIFAR-100.
| Modelo | Método | Cifar-10 | CIFAR-100 |
|---|---|---|---|
| VGG-small | Ann | 93,72% | 72,64% |
| PKKD Ann | 95,03% | 76,94% | |
| Slac Ann | 93,96% | 73,63% | |
| Resnet-20 | Ann | 92,02% | 67,60% |
| PKKD Ann | 92,96% | 69,93% | |
| Slac Ann | 92,29% | 68,31% | |
| ShiftAddnet* | 89,32%(160EPOCH) | - | |
| Resnet-32 | Ann | 93,01% | 69,17% |
| PKKD Ann | 93,62% | 72,41% | |
| Slac Ann | 93,24% | 69,83% |
Resultados da classificação no conjunto de dados ImageNet.
| Modelo | Método | Top-1 acc | Top 5 ACC |
|---|---|---|---|
| Resnet-18 | CNN | 69,8% | 89,1% |
| Ann | 67,0% | 87,6% | |
| PKKD Ann | 68,8% | 88,6% | |
| Slac Ann | 67,7% | 87,9% | |
| Resnet-50 | CNN | 76,2% | 92,9% |
| Ann | 74,9% | 91,7% | |
| PKKD Ann | 76,8% | 93,3% | |
| Slac Ann | 75,3% | 92,6% |
*ShiftAddNet usou diferentes configurações de treinamento.
Resultados da super-resolução em vários conjuntos de dados SR.
| Escala | Modelo | Método | SET5 (PSNR/SSIM) | SET14 (PSNR/SSIM) | B100 (PSNR/SSIM) | Urban100 (PSNR/SSIM) |
|---|---|---|---|---|---|---|
| × 2 | Vdsr | CNN | 37.53/0,9587 | 33.03/0,9124 | 31.90/0,8960 | 30.76/0,9140 |
| Ann | 37.37/0,9575 | 32.91/0.9112 | 31.82/0.8947 | 30.48/0.9099 | ||
| Edsr | CNN | 38.11/0.9601 | 33.92/0.9195 | 32.32/0.9013 | 32.93/0,9351 | |
| Ann | 37.92/0.9589 | 33.82/0,9183 | 32.23/0,9000 | 32.63/0.9309 | ||
| × 3 | Vdsr | CNN | 33.66/0,9213 | 29.77/0,8314 | 28.82/0,7976 | 27.14/0.8279 |
| Ann | 33.47/0.9151 | 29.62/0,8276 | 28.72/0,7953 | 26.95/0.8189 | ||
| Edsr | CNN | 34.65/0,9282 | 30.52/0,8462 | 29.25/0.8093 | 28.80/0,8653 | |
| Ann | 34.35/0,9212 | 30.33/0,8420 | 29.13/0.8068 | 28.54/0,8555 | ||
| × 4 | Vdsr | CNN | 31.35/0.8838 | 28.01/0,7674 | 27.29/0,7251 | 25.18/0,7524 |
| Ann | 31.27/0,8762 | 27.93/0.7630 | 27.25/0,7229 | 25.09/0,7445 | ||
| Edsr | CNN | 32.46/0,8968 | 28.80/0.7876 | 27.71/0,7420 | 26.64/0.8033 | |
| Ann | 32.13/0,8864 | 28.57/0,7800 | 27.58/0,7368 | 26.33/0,7874 |
Robustez adversária no CIFAR-10 sob ataques de caixa branca sem treinamento adversário.
| Modelo | Método | Limpar | FGSM | Bim7 | PGD7 | MIM5 | RFGSM5 |
|---|---|---|---|---|---|---|---|
| Resnet-20 | CNN | 92.68 | 16.33 | 0,00 | 0,00 | 0,01 | 0,00 |
| Ann | 91.72 | 18.42 | 0,00 | 0,00 | 0,04 | 0,00 | |
| CNN-R | 90.62 | 17.23 | 3.46 | 3.67 | 4.23 | 0,06 | |
| Ann-R | 90.95 | 29.93 | 29.30 | 29.72 | 32.25 | 3.38 | |
| Ann-R-Ianhar | 90.55 | 45.93 | 42.62 | 43.39 | 46.52 | 18.36 | |
| Resnet-32 | CNN | 92.78 | 23.55 | 0,00 | 0,01 | 0,10 | 0,00 |
| Ann | 92.48 | 35.85 | 0,03 | 0.11 | 1.04 | 0,02 | |
| CNN-R | 91.32 | 20.41 | 5.15 | 5.27 | 6.09 | 0,07 | |
| Ann-R | 91.68 | 19.74 | 15.96 | 16.08 | 17.48 | 0,07 | |
| Ann-R-Ianhar | 91.25 | 61.30 | 59.41 | 59.74 | 61.54 | 39.79 |
Comparações de mapa no Pascal Voc.
| Modelo | Espinha dorsal | Pescoço | mapa |
|---|---|---|---|
| R-CNN mais rápido | Conv r50 | Conv | 79.5 |
| FCOS | Conv r50 | Conv | 79.1 |
| Retinnet | Conv r50 | Conv | 77.3 |
| Boveabox | Conv r50 | Conv | 76.6 |
| Adder-fCos | Adder R50 | Adicionador | 76.5 |
Você pode seguir o Pytorch/Exemplos para preparar os dados do ImageNet.
Os modelos pré -treinados estão disponíveis no Google Drive ou Baidu Cloud (Código de Acesso: 126b)
Execute python main.py para treinar no CIFAR-10.
Execute python test.py --data_dir 'path/to/imagenet_root/' para avaliar no ImageNet val Set. Você atingirá 74,9% de precisão superior e 91,7% de precisão Top-5 no conjunto de dados ImageNet usando o ResNet-50.
Execute python test.py --dataset cifar10 --model_dir models/ResNet20-AdderNet.pth --data_dir 'path/to/cifar10_root/' para avaliar no CIFAR-10. Você atingirá 91,8% de precisão no conjunto de dados CIFAR-10 usando o ResNet-20.
A inferência e o treinamento de AdderNets é lenta, pois os filtros de Adder são implementados sem aceleração do CUDA. Você pode escrever CUDA para obter maior velocidade de inferência.
@article{AdderNet,
title={AdderNet: Do We Really Need Multiplications in Deep Learning?},
author={Chen, Hanting and Wang, Yunhe and Xu, Chunjing and Shi, Boxin and Xu, Chao and Tian, Qi and Xu, Chang},
journal={CVPR},
year={2020}
}
Agradecemos todas as contribuições. Se você planeja contribuir com fixos de bug, faça-o sem nenhuma discussão adicional.
Se você planeja contribuir com novos recursos, funções de utilidade ou extensões para o núcleo, primeiro abra um problema e discuta o recurso conosco. Enviar um PR sem discussão pode acabar resultando em um PR rejeitado, porque podemos estar tomando o núcleo em uma direção diferente da que você pode estar ciente.


