AdderNet
1.0.0
هذا الرمز هو عرض تجريبي لـ CVPR 2020 Paper Addernet: هل نحتاج حقًا إلى مضاعفات في التعلم العميق؟
نقدم شبكات Adder (Addernets) لتداول الضربات الهائلة في الشبكات العصبية العميقة ، وخاصة الشبكات العصبية التلافيفية (CNNs) ، لإضافات أرخص بكثير لتقليل تكاليف الحساب. في Addernets ، نأخذ مسافة Norm L1 بين المرشحات وميزة الإدخال كاستجابة للإخراج. ونتيجة لذلك ، يمكن لـ Addernets المقترحة تحقيق دقة أعلى من أعلى بنسبة 74.9 ٪ من أعلى درجة 91.7 ٪ عن أعلى 5 دقة باستخدام Resnet-50 على مجموعة بيانات ImageNet دون أي تكاثر في طبقة الالتزام.
قم بتشغيل python main.py للتدريب على Cifar-10.
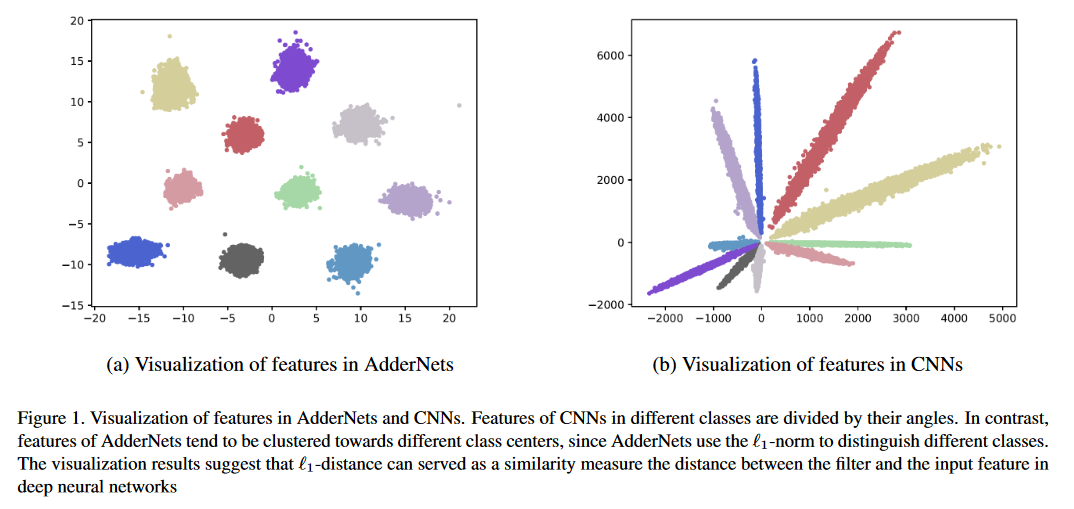
نتائج التصنيف على مجموعات بيانات CIFAR-10 و CIFAR-100.
| نموذج | طريقة | CIFAR-10 | CIFAR-100 |
|---|---|---|---|
| vgg-small | آن | 93.72 ٪ | 72.64 ٪ |
| PKKD آن | 95.03 ٪ | 76.94 ٪ | |
| Slac Ann | 93.96 ٪ | 73.63 ٪ | |
| RESNET-20 | آن | 92.02 ٪ | 67.60 ٪ |
| PKKD آن | 92.96 ٪ | 69.93 ٪ | |
| Slac Ann | 92.29 ٪ | 68.31 ٪ | |
| ShiftAddnet* | 89.32 ٪ (160epoch) | - | |
| RESNET-32 | آن | 93.01 ٪ | 69.17 ٪ |
| PKKD آن | 93.62 ٪ | 72.41 ٪ | |
| Slac Ann | 93.24 ٪ | 69.83 ٪ |
نتائج التصنيف على مجموعة بيانات ImageNet.
| نموذج | طريقة | أعلى 1 ACC | أعلى 5 ACC |
|---|---|---|---|
| RESNET-18 | سي إن إن | 69.8 ٪ | 89.1 ٪ |
| آن | 67.0 ٪ | 87.6 ٪ | |
| PKKD آن | 68.8 ٪ | 88.6 ٪ | |
| Slac Ann | 67.7 ٪ | 87.9 ٪ | |
| RESNET-50 | سي إن إن | 76.2 ٪ | 92.9 ٪ |
| آن | 74.9 ٪ | 91.7 ٪ | |
| PKKD آن | 76.8 ٪ | 93.3 ٪ | |
| Slac Ann | 75.3 ٪ | 92.6 ٪ |
*ShiftAddnet استخدم إعداد التدريب مختلف.
نتائج الدقة الفائقة على عدة مجموعات بيانات SR.
| حجم | نموذج | طريقة | set5 (PSNR/SSIM) | set14 (PSNR/SSIM) | B100 (PSNR/SSIM) | Urban100 (PSNR/SSIM) |
|---|---|---|---|---|---|---|
| × 2 | VDSR | سي إن إن | 37.53/0.9587 | 33.03/0.9124 | 31.90/0.8960 | 30.76/0.9140 |
| آن | 37.37/0.9575 | 32.91/0.9112 | 31.82/0.8947 | 30.48/0.9099 | ||
| edsr | سي إن إن | 38.11/0.9601 | 33.92/0.9195 | 32.32/0.9013 | 32.93/0.9351 | |
| آن | 37.92/0.9589 | 33.82/0.9183 | 32.23/0.9000 | 32.63/0.9309 | ||
| × 3 | VDSR | سي إن إن | 33.66/0.9213 | 29.77/0.8314 | 28.82/0.7976 | 27.14/0.8279 |
| آن | 33.47/0.9151 | 29.62/0.8276 | 28.72/0.7953 | 26.95/0.8189 | ||
| edsr | سي إن إن | 34.65/0.9282 | 30.52/0.8462 | 29.25/0.8093 | 28.80/0.8653 | |
| آن | 34.35/0.9212 | 30.33/0.8420 | 29.13/0.8068 | 28.54/0.8555 | ||
| × 4 | VDSR | سي إن إن | 31.35/0.8838 | 28.01/0.7674 | 27.29/0.7251 | 25.18/0.7524 |
| آن | 31.27/0.8762 | 27.93/0.7630 | 27.25/0.7229 | 25.09/0.7445 | ||
| edsr | سي إن إن | 32.46/0.8968 | 28.80/0.7876 | 27.71/0.7420 | 26.64/0.8033 | |
| آن | 32.13/0.8864 | 28.57/0.7800 | 27.58/0.7368 | 26.33/0.7874 |
المتانة العدائية على CIFAR-10 تحت هجمات الصندوق الأبيض دون تدريب عدائي.
| نموذج | طريقة | ينظف | FGSM | BIM7 | PGD7 | MIM5 | RFGSM5 |
|---|---|---|---|---|---|---|---|
| RESNET-20 | سي إن إن | 92.68 | 16.33 | 0.00 | 0.00 | 0.01 | 0.00 |
| آن | 91.72 | 18.42 | 0.00 | 0.00 | 0.04 | 0.00 | |
| CNN-R | 90.62 | 17.23 | 3.46 | 3.67 | 4.23 | 0.06 | |
| آن ر | 90.95 | 29.93 | 29.30 | 29.72 | 32.25 | 3.38 | |
| آن آن | 90.55 | 45.93 | 42.62 | 43.39 | 46.52 | 18.36 | |
| RESNET-32 | سي إن إن | 92.78 | 23.55 | 0.00 | 0.01 | 0.10 | 0.00 |
| آن | 92.48 | 35.85 | 0.03 | 0.11 | 1.04 | 0.02 | |
| CNN-R | 91.32 | 20.41 | 5.15 | 5.27 | 6.09 | 0.07 | |
| آن ر | 91.68 | 19.74 | 15.96 | 16.08 | 17.48 | 0.07 | |
| آن آن | 91.25 | 61.30 | 59.41 | 59.74 | 61.54 | 39.79 |
مقارنات الخريطة على Pascal Voc.
| نموذج | العمود الفقري | رقبة | رسم خريطة |
|---|---|---|---|
| أسرع r-cnn | Conv R50 | مقنعة | 79.5 |
| FCOS | Conv R50 | مقنعة | 79.1 |
| الريتينانيت | Conv R50 | مقنعة | 77.3 |
| FoveaBox | Conv R50 | مقنعة | 76.6 |
| adder-fcos | adder R50 | أفعى | 76.5 |
يمكنك متابعة Pytorch/أمثلة لإعداد بيانات ImageNet.
تتوفر النماذج المسبقة في Google Drive أو Baidu Cloud (رمز الوصول: 126B)
قم بتشغيل python main.py للتدريب على Cifar-10.
قم بتشغيل python test.py --data_dir 'path/to/imagenet_root/' لتقييم مجموعة ImageNet val . ستحقق دقة أعلى بنسبة 74.9 ٪ و 91.7 ٪ من أعلى 5 دقة على مجموعة بيانات ImageNet باستخدام RESNET-50.
قم بتشغيل python test.py --dataset cifar10 --model_dir models/ResNet20-AdderNet.pth --data_dir 'path/to/cifar10_root/' للتقييم على CIFAR-10. ستحقق دقة 91.8 ٪ على مجموعة بيانات CIFAR-10 باستخدام RESNET-20.
إن استنتاج وتدريب Addernets بطيء نظرًا لأن مرشحات Adder يتم تنفيذها دون تسارع CUDA. يمكنك كتابة CUDA لتحقيق سرعة استنتاج أعلى.
@article{AdderNet,
title={AdderNet: Do We Really Need Multiplications in Deep Learning?},
author={Chen, Hanting and Wang, Yunhe and Xu, Chunjing and Shi, Boxin and Xu, Chao and Tian, Qi and Xu, Chang},
journal={CVPR},
year={2020}
}
نحن نقدر جميع المساهمات. إذا كنت تخطط للمساهمة في إصلاح الأخطاء ، فيرجى القيام بذلك دون أي نقاش آخر.
إذا كنت تخطط للمساهمة بميزات جديدة أو وظائف الأداة المساعدة أو الإضافات في القلب ، فيرجى أولاً فتح مشكلة ومناقشة الميزة معنا. قد ينتهي إرسال العلاقات العامة دون مناقشة إلى حد ما إلى العلاقات العامة المرفوضة ، لأننا قد نأخذ القلب في اتجاه مختلف عما قد تكون على دراية به.


