postgresql exercises
1.0.0
這是關於Alisdair Owen的PostgreSQL練習的所有問題和答案的彙編。請記住,實際解決這些問題將使您不僅要瀏覽本指南,因此請確保支付後Ql練習的訪問。
進行練習非常簡單:您要做的就是打開練習,看看問題,然後嘗試回答它們!
這些練習的數據集用於新創建的鄉村俱樂部,其中包括一套成員,網球場等設施以及為這些設施的預訂歷史。除其他外,俱樂部想了解他們如何使用信息來分析設施的使用/需求。請注意:此數據集純粹是為了支持有趣的練習陣列,並且數據庫模式在幾個方面存在缺陷 - 請不要以它為良好設計的示例。我們將從查看會員表開始:
CREATE TABLE cd .members
(
memid integer NOT NULL ,
surname character varying ( 200 ) NOT NULL ,
firstname character varying ( 200 ) NOT NULL ,
address character varying ( 300 ) NOT NULL ,
zipcode integer NOT NULL ,
telephone character varying ( 20 ) NOT NULL ,
recommendedby integer ,
joindate timestamp not null ,
CONSTRAINT members_pk PRIMARY KEY (memid),
CONSTRAINT fk_members_recommendedby FOREIGN KEY (recommendedby)
REFERENCES cd . members (memid) ON DELETE SET NULL
);每個成員都有一個ID(不能保證是順序的),基本地址信息,對推薦它們的成員的引用(如果有)以及它們加入時的時間戳。數據集中的地址是完全(不切實際)的。
CREATE TABLE cd .facilities
(
facid integer NOT NULL ,
name character varying ( 100 ) NOT NULL ,
membercost numeric NOT NULL ,
guestcost numeric NOT NULL ,
initialoutlay numeric NOT NULL ,
monthlymaintenance numeric NOT NULL ,
CONSTRAINT facilities_pk PRIMARY KEY (facid)
);設施表列出了鄉村俱樂部擁有的所有可預訂設施。俱樂部存儲ID/名稱信息,預訂會員和客人的費用,建造設施的初始成本以及估計的每月維護費用。他們希望使用這些信息來跟踪每個設施的財務價值。
CREATE TABLE cd .bookings
(
bookid integer NOT NULL ,
facid integer NOT NULL ,
memid integer NOT NULL ,
starttime timestamp NOT NULL ,
slots integer NOT NULL ,
CONSTRAINT bookings_pk PRIMARY KEY (bookid),
CONSTRAINT fk_bookings_facid FOREIGN KEY (facid) REFERENCES cd . facilities (facid),
CONSTRAINT fk_bookings_memid FOREIGN KEY (memid) REFERENCES cd . members (memid)
);最後,有一個桌子跟踪設施的預訂。這存儲了設施ID,進行預訂的成員,預訂的開始以及預訂的半小時“老虎機”。這種特殊的設計將使某些查詢更加困難,但應該為您提供一些有趣的挑戰 - 並為使用一些現實世界數據庫的恐怖做好準備:-)。
好的,那應該是您需要的所有信息。您可以從上面的菜單中選擇一個類別的查詢,也可以從一開始就開始。
沒問題!起床並運行並不難。首先,您需要安裝PostgreSQL,您可以從這裡獲得。啟動後,下載SQL。
最後,運行psql -U <username> -f clubdata.sql -d postgres -x -q創建“練習”數據庫,Postgres'PGEXERCERS'PGEXERCESS'用戶,表格,並加載數據。請注意,請注意,您可能會發現,您可能會在網站上使用perge的範圍,因為該端口與網站相差不同,因為該pers可能會在網站上設置:這是一個不同C語言環境)
當您運行查詢時,您可能會發現PSQL有點笨拙。如果是這樣,我建議嘗試使用PGADMIN或Eclipse數據庫開發工具。

此類別涉及SQL的基礎知識。它涵蓋了選擇,案例表達式,工會以及其他一些賠率和終點。如果您已經在SQL中受過教育,則可能會發現這些練習相當容易。如果沒有,您應該發現它們是開始學習未來更困難的類別的好點!
如果您在這些問題上掙扎,我強烈建議Alan Beaulieu撰寫的SQL,作為一本關於該主題的簡潔而精心編寫的書。如果您對數據庫系統的基礎知識感興趣(而不是如何使用它們),則還應通過CJ日期調查數據庫系統的簡介。
如何從CD.FICICITIONS表中檢索所有信息?
預期結果:
| FACID | 姓名 | 成員代表 | 來賓代表 | 初始OUTOUTLAY | 每月保養 |
|---|---|---|---|---|---|
| 0 | 網球場1 | 5 | 25 | 10000 | 200 |
| 1 | 網球場2 | 5 | 25 | 8000 | 200 |
| 2 | 羽毛球法院 | 0 | 15.5 | 4000 | 50 |
| 3 | 乒乓球 | 0 | 5 | 320 | 10 |
| 4 | 按摩室1 | 35 | 80 | 4000 | 3000 |
| 5 | 按摩室2 | 35 | 80 | 4000 | 3000 |
| 6 | 壁球場 | 3.5 | 17.5 | 5000 | 80 |
| 7 | Snooker表 | 0 | 5 | 450 | 15 |
| 8 | 泳池表 | 0 | 5 | 400 | 15 |
回答:
select * from cd . facilities ; SELECT語句是查詢的基本起始塊,這些查詢是從數據庫中讀取信息的。最小的選擇語句通常select [some set of columns] from [some table or group of tables]組成。
在這種情況下,我們希望從設施表中的所有信息。從節很容易 - 我們只需要指定cd.facilities表即可。 “ CD”是表格的架構 - 用於數據庫中相關信息的邏輯分組的術語。
接下來,我們需要指定所有列。方便地,有一個“所有列”的速記 - *。我們可以使用它,而不是費力地指定所有列名。
您想打印出所有設施及其成本的清單。您如何檢索僅設施名稱和成本的列表?
預期結果:
| 姓名 | 成員代表 |
|---|---|
| 網球場1 | 5 |
| 網球場2 | 5 |
| 羽毛球法院 | 0 |
| 乒乓球 | 0 |
| 按摩室1 | 35 |
| 按摩室2 | 35 |
| 壁球場 | 3.5 |
| Snooker表 | 0 |
| 泳池表 | 0 |
回答:
select name, membercost from cd . facilities ; 對於這個問題,我們需要指定所需的列。我們可以使用指定為選擇語句的簡單逗號列表的簡單逗號列表來做到這一點。所有數據庫所做的就是查看從子句中可用的列,然後返回我們要求的列,如下所示
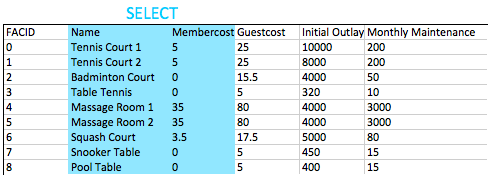
一般而言,對於非throwaway查詢,可以認為可以在查詢中指定所需的列的名稱而不是使用 *。這是因為如果將更多列添加到表中,您的應用程序可能無法應對。
您如何制定向會員收取費用的設施清單?
預期結果:
| FACID | 姓名 | 成員代表 | 來賓代表 | 初始OUTOUTLAY | 每月保養 |
|---|---|---|---|---|---|
| 0 | 網球場1 | 5 | 25 | 10000 | 200 |
| 1 | 網球場2 | 5 | 25 | 8000 | 200 |
| 4 | 按摩室1 | 35 | 80 | 4000 | 3000 |
| 5 | 按摩室2 | 35 | 80 | 4000 | 3000 |
| 6 | 壁球場 | 3.5 | 17.5 | 5000 | 80 |
回答:
select * from cd . facilities where membercost > 0 ; FROM子句用於建立一組候選行以讀取結果。到目前為止,在我們的示例中,這組排只是表的內容。將來我們將探索加入,這使我們能夠創建更多有趣的候選人。
一旦我們建立了一組候選行, WHERE子句允許我們過濾我們感興趣的行 - 在這種情況下,成員代表的成員超過零。正如您將在以後的練習中看到的那樣, WHERE條款可以具有多個組件與布爾邏輯相結合 - 例如,可以搜索其成本大於0且小於10的設施。設施上的WHERE子句的過濾操作如下:
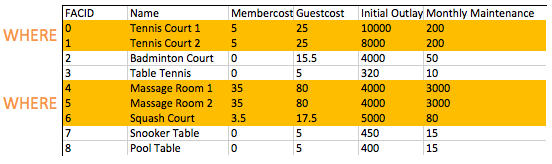
您如何制定向會員收取費用的設施清單,而該費用少於每月維護成本的1/50?返回相關設施的FACID,設施名稱,會員成本和每月維護。
預期結果:
| FACID | 姓名 | 成員代表 | 每月保養 |
|---|---|---|---|
| 4 | 按摩室1 | 35 | 3000 |
| 5 | 按摩室2 | 35 | 3000 |
回答:
select facid, name, membercost, monthlymaintenance
from cd . facilities
where
membercost > 0 and
(membercost < monthlymaintenance / 50 . 0 ); WHERE條款允許我們過濾我們感興趣的行 - 在這種情況下,成員成員的成員超過零,少於每月維護成本的1/50少於1/50。如您所見,由於人員配備成本,按摩室運行非常昂貴!
當我們要測試兩個或多個條件時,我們會使用AND結合它們。如您所期望的那樣,我們可以使用OR測試一對條件中的任何一個是正確的。
您可能已經註意到,這是我們的第一個查詢,將WHERE子句與選擇特定的列相結合。您可以在下面的圖像中看到以下效果:所選列和所選行的相交為我們提供了返回的數據。現在似乎不太有趣,但是正如我們添加了更複雜的操作,例如加入後來,您會看到這種行為的簡單優雅。
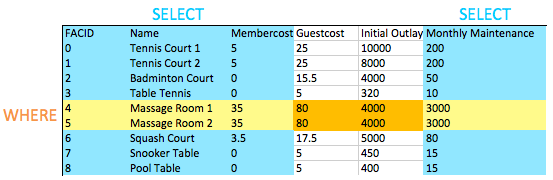
您如何以其名稱以“網球”一詞的形式製作所有設施的列表?
預期結果:
| FACID | 姓名 | 成員代表 | 來賓代表 | 初始OUTOUTLAY | 每月保養 |
|---|---|---|---|---|---|
| 0 | 網球場1 | 5 | 25 | 10000 | 200 |
| 1 | 網球場2 | 5 | 25 | 8000 | 200 |
| 3 | 乒乓球 | 0 | 5 | 320 | 10 |
回答:
select *
from cd . facilities
where
name like ' %Tennis% ' ; SQL的LIKE運營商在字符串上提供了簡單的模式匹配。它幾乎是普遍實現的,並且既易於使用又易於使用 - 它只需帶一個符合任何字符串字符的字符串,_匹配任何單個字符。在這種情況下,我們正在尋找包含“網球”一詞的名稱,因此在任何一邊都貼上一個%的賬單。
還有其他方法可以完成此任務:例如,Postgres支持與操作員的正則表達式。使用讓您感到舒適的任何東西,但請注意, LIKE操作員在系統之間更便攜。
您如何使用ID 1和5檢索設施的詳細信息?嘗試在不使用或操作員的情況下執行此操作。
預期結果:
| FACID | 姓名 | 成員代表 | 來賓代表 | 初始OUTOUTLAY | 每月保養 |
|---|---|---|---|---|---|
| 1 | 網球場2 | 5 | 25 | 8000 | 200 |
| 5 | 按摩室2 | 35 | 80 | 4000 | 3000 |
回答:
select *
from cd . facilities
where
facid in ( 1 , 5 ); 這個問題的明顯答案是使用WHERE看起來像where facid = 1 or facid = 5子句。在IN符中,有大量可能的匹配項更容易。在運算IN獲取可能的值列表,並將它們與(在這種情況下)facid匹配。如果其中一個值匹配,則該行的where子句為true,然後返回行。
IN符是關係模型優雅的良好早期演示者。它採取的參數不僅是值列表 - 它實際上是一個帶有單列的表。由於查詢也返回表,因此如果您創建一個返回單列的查詢,則可以將這些結果饋送到IN員中。舉一個玩具例子:
select *
from cd . facilities
where
facid in (
select facid from cd . facilities
);該示例在功能上等同於僅選擇所有設施,但向您展示瞭如何將一個查詢的結果饋送到另一個查詢的結果。內部查詢稱為子查詢。
您如何製作設施列表,每個設施都標記為“便宜”或“昂貴”,具體取決於其每月維護成本是否超過100美元?返回有關設施的名稱和每月維護。
預期結果:
| 姓名 | 成本 |
|---|---|
| 網球場1 | 昂貴的 |
| 網球場2 | 昂貴的 |
| 羽毛球法院 | 便宜的 |
| 乒乓球 | 便宜的 |
| 按摩室1 | 昂貴的 |
| 按摩室2 | 昂貴的 |
| 壁球場 | 便宜的 |
| Snooker表 | 便宜的 |
| 泳池表 | 便宜的 |
回答:
select name,
case when (monthlymaintenance > 100 ) then
' expensive '
else
' cheap '
end as cost
from cd . facilities ; 本練習包含一些新概念。首先是我們在SELECT和FROM的查詢區域進行計算。以前,我們僅將其用於選擇要返回的列,但是您可以將任何內容都放在每個返回行(包括子查詢)中會產生單個結果。
第二個新概念是CASE陳述本身。 CASE實際上就像其他語言中的/開關語句一樣,其形式如查詢所示。要添加“中間”選項,我們只需when...then插入另一個選項。
最後,有AS操作員。這僅用於標記列或表達式,以使其顯示更精美,或者在用作子查詢的一部分時使其更易於參考。
您如何制定2012年9月開始後加入的成員名單?返回有關成員的MEMID,姓氏,名稱和加入。
預期結果:
| 梅德 | 姓 | 名 | 加入 |
|---|---|---|---|
| 24 | 薩爾文 | 拉姆納雷什 | 2012-09-01 08:44:42 |
| 26 | 瓊斯 | 道格拉斯 | 2012-09-02 18:43:05 |
| 27 | 拉姆尼 | 亨利埃塔 | 2012-09-05 08:42:35 |
| 28 | 法雷爾 | 大衛 | 2012-09-15 08:22:05 |
| 29 | Worthington-Smyth | 亨利 | 2012-09-17 12:27:15 |
| 30 | 範圍 | 米里森 | 2012-09-18 19:04:01 |
| 33 | 特百惠 | 風信子 | 2012-09-18 19:32:05 |
| 35 | 打獵 | 約翰 | 2012-09-19 11:32:45 |
| 36 | 碎屑 | 埃里卡 | 2012-09-22 08:36:38 |
| 37 | 史密斯 | 達倫 | 2012-09-26 18:08:45 |
回答:
select memid, surname, firstname, joindate
from cd . members
where joindate >= ' 2012-09-01 ' ; 這是我們對SQL時間戳的首次瀏覽。它們以降序的數量級格式: YYYY-MM-DD HH:MM:SS.nnnnnn 。我們可以像Unix Timestamp一樣比較它們,儘管在日期之間獲得差異的參與度更高(而且強大!)。在這種情況下,我們剛剛指定了時間戳的日期部分。這將被Postgres自動投入到整個時間戳2012-09-01 00:00:00 。
如何在成員表中產生前10個姓氏的有序列表?該列表不得包含重複項。
預期結果:
| 姓 |
|---|
| 壞人 |
| 貝克 |
| 展位 |
| 奶油 |
| 科普林 |
| 碎屑 |
| 敢 |
| 法雷爾 |
| 客人 |
| 雲頂 |
回答:
select distinct surname
from cd . members
order by surname
limit 10 ; 這裡有三個新概念,但是它們都很簡單。
SELECT後指定DISTINCT之後的不同之後,將從結果集中刪除重複行。請注意,這適用於行:如果行A具有多個列,則僅在所有列中的值相同時,行B僅等於它。一般而言,不要以威利·尼利(Willy-nilly)的方式使用DISTINCT方式 - 從大查詢結果集中刪除重複項並不是免費的,因此請盡一切努力。ORDER BY (在查詢末尾的從FROM和WHERE之後)指定順序,允許通過列或一組列(逗號分隔)訂購結果。LIMIT關鍵字允許您限制檢索到的結果數。這對於一次獲得結果很有用,並且可以與OFFSET關鍵字結合使用以獲取以下頁面。這與MySQL使用的方法相同,並且非常方便 - 不幸的是,您可能會發現此過程在其他DB中更為複雜。由於某種原因,您想要所有姓氏和所有設施名稱的列表。是的,這是一個人為的例子:-)。生產該清單!
預期結果:
| 姓 |
|---|
| 網球場2 |
| Worthington-Smyth |
| 羽毛球法院 |
| 平克 |
| 敢 |
| 壞人 |
| 麥肯齊 |
| 碎屑 |
| 按摩室1 |
| 壁球場 |
回答:
select surname
from cd . members
union
select name
from cd . facilities ; UNION操作員會做您可能期望的事情:將兩個SQL查詢的結果結合到一個表中。需要注意的是,這兩個查詢的兩個結果都必須具有相同數量的列和兼容數據類型。
UNION刪除了重複的行,而UNION ALL沒有。默認情況下,請使用UNION ALL使用,除非您關心重複的結果。
您想獲得最後會員的註冊日期。您如何檢索此信息?
預期結果:
| 最新的 |
|---|
| 2012-09-26 18:08:45 |
回答:
select max (joindate) as latest
from cd . members ; 這是我們第一次涉足SQL的匯總功能。它們用於提取有關整個行的信息,並讓我們輕鬆提出類似的問題:
這裡的最大聚合函數非常簡單:它接收加入的所有可能值,並輸出最大的值。匯總功能還有更多的功能,您將在以後的練習中遇到。
您想獲得註冊的最後一個成員的名字和姓氏,而不僅僅是日期。你怎麼做?
預期結果:
| 名 | 姓 | 加入 |
|---|---|---|
| 達倫 | 史密斯 | 2012-09-26 18:08:45 |
回答:
select firstname, surname, joindate
from cd . members
where joindate =
( select max (joindate)
from cd . members ); 在上面建議的方法中,您使用子查詢來找出最近的結合。此子查詢返回標量表 - 即,一個帶有單列和一行的表。由於我們只有一個值,因此我們可以在可能放置一個恆定值的任何地方替換子查詢。在這種情況下,我們使用它來完成查詢的WHERE子句以找到給定的成員。
您可能希望您能夠做以下類似的事情:
select firstname, surname, max (joindate)
from cd . members不幸的是,這無效。 MAX函數不會像WHERE所做的那樣限制行 - 它只是佔用一大堆值並返回最大的值。然後留下數據庫,想知道如何將一長串名稱列表與最大功能出現的單個加入日期配對,並且失敗。取而代之的是,您不得不說“找到我的行,該行的加入日期與最大聯盟日期相同”。
如提示所述,還有其他方法可以完成這項工作 - 下面是一個示例。在這種方法中,我們只需明確地找出最後一個加入日期是什麼,而是只需以降序的加入日期訂購我們的會員表,然後挑選第一個。請注意,這種方法並不能涵蓋兩個人同時加入的極端情況:-)。
select firstname, surname, joindate
from cd . members
order by joindate desc
limit 1 ;此類別主要涉及關係數據庫系統中的基礎概念:加入。加入使您可以組合來自多個表的相關信息來回答問題。這不僅有利於查詢:缺乏聯接功能會鼓勵數據劃定數據,這增加了保持數據內部一致的複雜性。
該主題涵蓋了內部,外部和自我連接,並花了一點時間在子查詢上(查詢中的查詢)。如果您在這些問題上掙扎,我強烈建議Alan Beaulieu撰寫的SQL,作為一本關於該主題的簡潔而精心編寫的書。
您如何制定名為“ David Farrell”的成員預訂的開始列表?
預期結果:
| 開始時間 |
|---|
| 2012-09-18 09:00:00 |
| 2012-09-18 17:30:00 |
| 2012-09-18 13:30:00 |
| 2012-09-18 20:00:00 |
| 2012-09-19 09:30:00 |
| 2012-09-19 15:00:00 |
| 2012-09-19 12:00:00 |
| 2012-09-20 15:30:00 |
| 2012-09-20 11:30:00 |
| 2012-09-20 14:00:00 |
回答:
select bks . starttime
from
cd . bookings bks
inner join cd . members mems
on mems . memid = bks . memid
where
mems . firstname = ' David '
and mems . surname = ' Farrell ' ; 最常用的類型的聯接是INNER JOIN 。這樣做的方法是根據聯接表達式組合兩個表 - 在這種情況下,對於成員表中的每個成員ID,我們正在尋找預訂表中的匹配值。在我們找到匹配的地方,返回了一個組合每個表的值的行。請注意,我們為每個表提供了一個別名(BKS和MEMS)。這是有兩個原因的:首先,它很方便,其次,我們可能會多次加入同一表,要求我們將列與每個不同時間連接的不同時間區分。
讓我們忽略我們的選擇和現在的條款,而要關注FROM語句的產生的內容。在我們以前的所有示例中, FROM只是一個簡單的表。現在是什麼?另一個桌子!這次,它是作為預訂和成員組成的。您可以看到下面的加入的輸出的子集:

對於成員表中的每個成員,JOIN在預訂表中找到了所有匹配的成員ID。對於每場比賽,然後製作了一排從成員表組合行,以及預訂表中的行。
顯然,這本身就是太多的信息,任何有用的問題都希望將其過濾。在我們的查詢中,我們使用SELECT子句的開始來選擇列,以及選擇行的WHERE子句,如下所示:

這就是我們需要找到大衛預訂的全部!通常,我鼓勵您記住,從FROM的輸出本質上是一張大表格,然後您將信息過濾掉。這聽起來可能效率低下 - 但不用擔心,在封面下,數據庫的行為會更加聰明:-)。
最後一個注意:內在連接有兩個不同的語法。我向您展示了我喜歡的那個,發現與其他聯接類型更一致。您通常會看到不同的語法,如下所示:
select bks . starttime
from
cd . bookings bks,
cd . members mems
where
mems . firstname = ' David '
and mems . surname = ' Farrell '
and mems . memid = bks . memid ;這在功能上與批准的答案完全相同。如果您對此語法更舒適,請隨時使用它!
您如何在“ 2012-09-21”日期為網球場預訂的開始時間列表?返回按時間訂購的開始時間和設施配對的列表。
預期結果:
| 開始 | 姓名 |
|---|---|
| 2012-09-21 08:00:00 | 網球場1 |
| 2012-09-21 08:00:00 | 網球場2 |
| 2012-09-21 09:30:00 | 網球場1 |
| 2012-09-21 10:00:00 | 網球場2 |
| 2012-09-21 11:30:00 | 網球場2 |
| 2012-09-21 12:00:00 | 網球場1 |
| 2012-09-21 13:30:00 | 網球場1 |
| 2012-09-21 14:00:00 | 網球場2 |
| 2012-09-21 15:30:00 | 網球場1 |
| 2012-09-21 16:00:00 | 網球場2 |
| 2012-09-21 17:00:00 | 網球場1 |
| 2012-09-21 18:00:00 | 網球場2 |
回答:
select bks . starttime as start, facs . name as name
from
cd . facilities facs
inner join cd . bookings bks
on facs . facid = bks . facid
where
facs . facid in ( 0 , 1 ) and
bks . starttime >= ' 2012-09-21 ' and
bks . starttime < ' 2012-09-22 '
order by bks . starttime ; 這是另一個INNER JOIN查詢,儘管它的複雜性更加複雜!查詢的FROM很容易 - 我們只是將設施和預訂表加在一起。這會產生一張表格,對於預訂中的每一行,我們都附加了有關預訂設施的詳細信息。
到查詢的WHERE組件。對開始時間的檢查是相當自我解釋的 - 我們確保所有預訂都在指定的日期之間開始。由於我們只對網球場感興趣,因此我們還使用IN運營商告訴數據庫系統,僅向我們提供回式設施IDS 0或1-法院的IDS。還有其他方法可以表達出來:我們可以where facs.facid = 0 or facs.facid = 1使用,甚至where facs.name like 'Tennis%' 。
其餘的非常簡單:我們SELECT我們感興趣的列,然後在開始時間ORDER BY 。
您如何輸出所有推薦其他成員的成員的列表?確保列表中沒有重複項,並且結果由(姓氏,firstName)訂購。
預期結果:
| 名 | 姓 |
|---|---|
| 佛羅倫斯 | 壞人 |
| 蒂莫西 | 貝克 |
| 杰拉爾德 | 奶油 |
| 傑米瑪 | 法雷爾 |
| 馬修 | 雲頂 |
| 大衛 | 瓊斯 |
| 珍妮絲 | 喬普特 |
| 米里森 | 範圍 |
| 蒂姆 | 羅恩南 |
| 達倫 | 史密斯 |
| 特雷西 | 史密斯 |
| 思考 | Stibbons |
| 伯頓 | 特雷西 |
回答:
select distinct recs . firstname as firstname, recs . surname as surname
from
cd . members mems
inner join cd . members recs
on recs . memid = mems . recommendedby
order by surname, firstname; 這是一些人感到困惑的概念:您可以加入桌子!如果您在同一表中具有參考數據的列,就像我們在cd.members中使用的推荐一樣,這真的很有用。
如果您難以實現此目標,請記住,這與任何其他內部聯接一樣。我們的加入將每行都帶入具有推薦值的成員中,並再次查找具有匹配成員ID的行。然後,它生成一個組合兩個成員條目的輸出行。這看起來像以下圖:

請注意,儘管我們可能在輸出集中有兩個“姓氏”列,但它們可以通過其表格別名區分。一旦選擇了所需的列,我們就簡單地使用DISTINCT來確保沒有重複。
您如何輸出所有成員的列表,包括推薦他們的個人(如果有)?確保結果由(姓氏,名稱)訂購。
預期結果:
| memfname | memsname | recFname | recsname |
|---|---|---|---|
| 佛羅倫斯 | 壞人 | 思考 | Stibbons |
| 安妮 | 貝克 | 思考 | Stibbons |
| 蒂莫西 | 貝克 | 傑米瑪 | 法雷爾 |
| 蒂姆 | 展位 | 蒂姆 | 羅恩南 |
| 杰拉爾德 | 奶油 | 達倫 | 史密斯 |
| 瓊 | 科普林 | 蒂莫西 | 貝克 |
| 埃里卡 | 碎屑 | 特雷西 | 史密斯 |
| 南希 | 敢 | 珍妮絲 | 喬普特 |
| 大衛 | 法雷爾 | ||
| 傑米瑪 | 法雷爾 | ||
| 客人 | 客人 | ||
| 馬修 | 雲頂 | 杰拉爾德 | 奶油 |
| 約翰 | 打獵 | 米里森 | 範圍 |
| 大衛 | 瓊斯 | 珍妮絲 | 喬普特 |
| 道格拉斯 | 瓊斯 | 大衛 | 瓊斯 |
| 珍妮絲 | 喬普特 | 達倫 | 史密斯 |
| 安娜 | 麥肯齊 | 達倫 | 史密斯 |
| 查爾斯 | 歐文 | 達倫 | 史密斯 |
| 大衛 | 平克 | 傑米瑪 | 法雷爾 |
| 米里森 | 範圍 | 特雷西 | 史密斯 |
| 蒂姆 | 羅恩南 | ||
| 亨利埃塔 | 拉姆尼 | 馬修 | 雲頂 |
| 拉姆納雷什 | 薩爾文 | 佛羅倫斯 | 壞人 |
| 達倫 | 史密斯 | ||
| 達倫 | 史密斯 | ||
| 傑克 | 史密斯 | 達倫 | 史密斯 |
| 特雷西 | 史密斯 | ||
| 思考 | Stibbons | 伯頓 | 特雷西 |
| 伯頓 | 特雷西 | ||
| 風信子 | 特百惠 | ||
| 亨利 | Worthington-Smyth | 特雷西 | 史密斯 |
回答:
select mems . firstname as memfname, mems . surname as memsname, recs . firstname as recfname, recs . surname as recsname
from
cd . members mems
left outer join cd . members recs
on recs . memid = mems . recommendedby
order by memsname, memfname; 讓我們介紹另一個新概念: LEFT OUTER JOIN 。最好通過它們與內在的連接不同的方式來解釋這些。內部連接左右桌子,並根據聯接條件( ON )尋找匹配行。滿足條件後,會產生一個連接的行。 LEFT OUTER JOIN運行方式類似,只是,如果左側表上的一個給定行與任何內容都不匹配,則仍然會產生輸出行。該輸出行由左手錶行組成,並代替右手錶行的一堆NULLS 。
在這樣的情況下,這很有用,我們想在其中產生帶有可選數據的輸出。我們想要所有成員的名字,以及如果該人的存在的名稱。您無法通過內在聯接正確表達這一點。
您可能已經猜到了,還有其他外部連接。 RIGHT OUTER JOIN非常類似於LEFT OUTER JOIN ,只是表達式的左側是包含可選數據的表達式。很少使用的FULL OUTER JOIN將表達式的兩側視為可選的。
您如何找到使用網球場的所有成員的清單?在您的輸出中包括法院的名稱,以及以單列格式的成員名稱。確保沒有重複的數據,並按成員名稱訂購。
預期結果:
| 成員 | 設施 |
|---|---|
| 安妮·貝克 | 網球場2 |
| 安妮·貝克 | 網球場1 |
| 伯頓·特雷西 | 網球場2 |
| 伯頓·特雷西 | 網球場1 |
| 查爾斯·歐文 | 網球場2 |
| 查爾斯·歐文 | 網球場1 |
| 達倫·史密斯(Darren Smith) | 網球場2 |
| 大衛·法雷爾(David Farrell) | 網球場2 |
| 大衛·法雷爾(David Farrell) | 網球場1 |
| 大衛·瓊斯 | 網球場1 |
| 大衛·瓊斯 | 網球場2 |
| 大衛·平克(David Pinker) | 網球場1 |
| 道格拉斯·瓊斯(Douglas Jones) | 網球場1 |
| Erica Crumpet | 網球場1 |
| 佛羅倫薩·巴德 | 網球場1 |
| 佛羅倫薩·巴德 | 網球場2 |
| 來賓 | 網球場2 |
| 來賓 | 網球場1 |
| 杰拉爾德·巴特斯(Gerald Butters) | 網球場1 |
| 杰拉爾德·巴特斯(Gerald Butters) | 網球場2 |
| Henrietta Rumney | 網球場2 |
| 傑克·史密斯 | 網球場1 |
| 傑克·史密斯 | 網球場2 |
| 珍妮絲·喬普萊特(Janice Joplette) | 網球場1 |
| 珍妮絲·喬普萊特(Janice Joplette) | 網球場2 |
| 傑米瑪·法雷爾(Jemima Farrell) | 網球場2 |
| 傑米瑪·法雷爾(Jemima Farrell) | 網球場1 |
| 瓊·科普林 | 網球場1 |
| 約翰·亨特 | 網球場1 |
| 約翰·亨特 | 網球場2 |
| 馬修·雲頂 | 網球場1 |
| Millicent Purview | 網球場2 |
| 南希·敢 | 網球場2 |
| 南希·敢 | 網球場1 |
| 思考史蒂布斯 | 網球場2 |
| 思考史蒂布斯 | 網球場1 |
| Ramnaresh Sarwin | 網球場2 |
| Ramnaresh Sarwin | 網球場1 |
| 蒂姆·布特 | 網球場1 |
| 蒂姆·布特 | 網球場2 |
| 蒂姆·羅恩納姆(Tim Rownam) | 網球場1 |
| 蒂姆·羅恩納姆(Tim Rownam) | 網球場2 |
| 蒂莫西·貝克(Timothy Baker) | 網球場2 |
| 蒂莫西·貝克(Timothy Baker) | 網球場1 |
| 特雷西·史密斯 | 網球場2 |
| 特雷西·史密斯 | 網球場1 |
回答:
select distinct mems . firstname || ' ' || mems . surname as member, facs . name as facility
from
cd . members mems
inner join cd . bookings bks
on mems . memid = bks . memid
inner join cd . facilities facs
on bks . facid = facs . facid
where
bks . facid in ( 0 , 1 )
order by member 這項練習在很大程度上是您在先前問題中學到的知識的更為複雜的應用。這也是我們第一次使用多個加入,這可能有些混亂。在閱讀加入表達式時,請記住,一個連接是一個有效的函數,該函數佔兩個表,一個標記為左表,另一個標記為右表。只需在查詢中加入一個即可可視化這很容易可視化,但與兩個相關。
我們在此查詢中的第二個INNER JOIN具有CD.FICISITIONS的右側。這很容易掌握。但是,左側是通過將CD.會員加入CD.Bookings返回的桌子。強調這一點很重要:關係模型與表有關。任何加入的輸出是另一個表。查詢的輸出是一個表。單列列表是表。一旦掌握了這一點,就可以掌握模型的基本美。
最後,我們確實在這裡介紹了一件新事物: ||操作員用於連接字符串。
您如何在2012-09-14當天制定預訂列表,這將使會員(或來賓)損失超過30美元?請記住,客人對成員的費用不同(列出的成本為每半小時的“插槽”),並且來賓用戶始終是ID 0。在您的輸出中包括設施的名稱,成員名稱為單一列,以及成本。通過下降成本訂購,不要使用任何子征服。
預期結果:
| 成員 | 設施 | 成本 |
|---|---|---|
| 來賓 | 按摩室2 | 320 |
| 來賓 | 按摩室1 | 160 |
| 來賓 | 按摩室1 | 160 |
| 來賓 | 按摩室1 | 160 |
| 來賓 | 網球場2 | 150 |
| 傑米瑪·法雷爾(Jemima Farrell) | 按摩室1 | 140 |
| 來賓 | 網球場1 | 75 |
| 來賓 | 網球場2 | 75 |
| 來賓 | 網球場1 | 75 |
| 馬修·雲頂 | 按摩室1 | 70 |
| 佛羅倫薩·巴德 | 按摩室2 | 70 |
| 來賓 | 壁球場 | 70.0 |
| 傑米瑪·法雷爾(Jemima Farrell) | 按摩室1 | 70 |
| 思考史蒂布斯 | 按摩室1 | 70 |
| 伯頓·特雷西 | 按摩室1 | 70 |
| 傑克·史密斯 | 按摩室1 | 70 |
| 來賓 | 壁球場 | 35.0 |
| 來賓 | 壁球場 | 35.0 |
回答:
select mems . firstname || ' ' || mems . surname as member,
facs . name as facility,
case
when mems . memid = 0 then
bks . slots * facs . guestcost
else
bks . slots * facs . membercost
end as cost
from
cd . members mems
inner join cd . bookings bks
on mems . memid = bks . memid
inner join cd . facilities facs
on bks . facid = facs . facid
where
bks . starttime >= ' 2012-09-14 ' and
bks . starttime < ' 2012-09-15 ' and (
( mems . memid = 0 and bks . slots * facs . guestcost > 30 ) or
( mems . memid != 0 and bks . slots * facs . membercost > 30 )
)
order by cost desc ; 這有點複雜!雖然它比我們以前使用的要復雜的邏輯還要復雜,但並沒有很多值得注意的話題。 WHERE子句將我們的產出限制為在2012 - 09-14的足夠昂貴的行,記得區分客人和其他人。然後,我們在“選擇”列中使用CASE語句為會員或來賓輸出正確的成本。
您如何在不使用任何加入的情況下輸出所有成員的列表,包括推薦他們的個人(如果有的話)?確保列表中沒有重複項,並且每個firstName +姓氏配對都格式化為列並訂購。
預期結果:
| 成員 | 推薦人 |
|---|---|
| 安娜·麥肯齊(Anna Mackenzie) | 達倫·史密斯(Darren Smith) |
| 安妮·貝克 | 思考史蒂布斯 |
| 伯頓·特雷西 | |
| 查爾斯·歐文 | 達倫·史密斯(Darren Smith) |
| 達倫·史密斯(Darren Smith) | |
| 大衛·法雷爾(David Farrell) | |
| 大衛·瓊斯 | 珍妮絲·喬普萊特(Janice Joplette) |
| 大衛·平克(David Pinker) | 傑米瑪·法雷爾(Jemima Farrell) |
| 道格拉斯·瓊斯(Douglas Jones) | 大衛·瓊斯 |
| Erica Crumpet | 特雷西·史密斯 |
| 佛羅倫薩·巴德 | 思考史蒂布斯 |
| 來賓 | |
| 杰拉爾德·巴特斯(Gerald Butters) | 達倫·史密斯(Darren Smith) |
| Henrietta Rumney | 馬修·雲頂 |
| 亨利·沃辛頓 - 史密斯 | 特雷西·史密斯 |
| 風信子特百惠 | |
| 傑克·史密斯 | 達倫·史密斯(Darren Smith) |
| 珍妮絲·喬普萊特(Janice Joplette) | 達倫·史密斯(Darren Smith) |
| 傑米瑪·法雷爾(Jemima Farrell) | |
| 瓊·科普林 | 蒂莫西·貝克(Timothy Baker) |
| 約翰·亨特 | Millicent Purview |
| 馬修·雲頂 | 杰拉爾德·巴特斯(Gerald Butters) |
| Millicent Purview | 特雷西·史密斯 |
| 南希·敢 | 珍妮絲·喬普萊特(Janice Joplette) |
| 思考史蒂布斯 | 伯頓·特雷西 |
| Ramnaresh Sarwin | 佛羅倫薩·巴德 |
| 蒂姆·布特 | 蒂姆·羅恩納姆(Tim Rownam) |
| 蒂姆·羅恩納姆(Tim Rownam) | |
| 蒂莫西·貝克(Timothy Baker) | 傑米瑪·法雷爾(Jemima Farrell) |
| 特雷西·史密斯 |
回答:
select distinct mems . firstname || ' ' || mems . surname as member,
( select recs . firstname || ' ' || recs . surname as recommender
from cd . members recs
where recs . memid = mems . recommendedby
)
from
cd . members mems
order by member; 此練習標誌著次級的引入。顧名思義,在查詢中查詢。它們通常與聚集體一起使用,以回答諸如“讓我在網球場1中度過最多時間的成員的所有細節”之類的問題。
在這種情況下,我們只是使用子查詢模仿外部連接。對於成員的每個值,都會運行一次子查詢以找到推薦它們的個人名稱(如果有)。以這種方式使用來自外部查詢的信息(因此必須在結果集中的每一行運行)的子查詢稱為相關子查詢。
農產品清單的昂貴預訂練習包含一些混亂的邏輯:我們必須在Where子句和案例陳述中計算預訂成本。嘗試使用子查詢來簡化此計算。作為參考,問題是:
您如何在2012-09-14當天制定預訂列表,這將使會員(或來賓)損失超過30美元?請記住,客人對成員的費用不同(列出的成本為每半小時的“插槽”),並且來賓用戶始終是ID 0。在您的輸出中包括設施的名稱,成員名稱為單一列,以及成本。通過下降成本訂購。
預期結果:
| 成員 | 設施 | 成本 |
|---|---|---|
| 來賓 | 按摩室2 | 320 |
| 來賓 | 按摩室1 | 160 |
| 來賓 | 按摩室1 | 160 |
| 來賓 | 按摩室1 | 160 |
| 來賓 | 網球場2 | 150 |
| 傑米瑪·法雷爾(Jemima Farrell) | 按摩室1 | 140 |
| 來賓 | 網球場1 | 75 |
| 來賓 | 網球場2 | 75 |
| 來賓 | 網球場1 | 75 |
| 馬修·雲頂 | 按摩室1 | 70 |
| 佛羅倫薩·巴德 | 按摩室2 | 70 |
| 來賓 | 壁球場 | 70.0 |
| 傑米瑪·法雷爾(Jemima Farrell) | 按摩室1 | 70 |
| 思考史蒂布斯 | 按摩室1 | 70 |
| 伯頓·特雷西 | 按摩室1 | 70 |
| 傑克·史密斯 | 按摩室1 | 70 |
| 來賓 | 壁球場 | 35.0 |
| 來賓 | 壁球場 | 35.0 |
回答:
select member, facility, cost from (
select
mems . firstname || ' ' || mems . surname as member,
facs . name as facility,
case
when mems . memid = 0 then
bks . slots * facs . guestcost
else
bks . slots * facs . membercost
end as cost
from
cd . members mems
inner join cd . bookings bks
on mems . memid = bks . memid
inner join cd . facilities facs
on bks . facid = facs . facid
where
bks . starttime >= ' 2012-09-14 ' and
bks . starttime < ' 2012-09-15 '
) as bookings
where cost > 30
order by cost desc ; 此答案為上一個迭代提供了溫和的簡化:在“無標題”版本中,我們必須在WHERE子句和CASE語句中計算成員或來賓的費用。在我們的新版本中,我們製作了一個內聯查詢,該查詢計算了我們的總預訂成本,從而使外部查詢可以簡單地選擇所需的預訂。作為參考,您可能還會在稱為內聯視圖的“從FROM中”中看到子查詢。
查詢數據非常好,但是在某些時候,您可能想將數據放入數據庫中!本節涉及插入,更新和刪除信息。改變這樣的數據的操作統稱為數據操縱語言或DML。
在以前的部分中,我們向您返回了您執行的查詢結果。由於像我們在本節中進行的修改不會返回任何查詢結果,因此我們向您展示您應該處理的表格的更新內容。您可以將此與“預期結果”中顯示的表進行比較,以查看您的工作方式。
如果您在這些問題上掙扎,我強烈建議Alan Beaulieu的學習SQL。
俱樂部正在增加一個新的設施 - 水療中心。我們需要將其添加到設施表中。使用以下值:
預期結果:
| FACID | 姓名 | 成員代表 | 來賓代表 | 初始OUTOUTLAY | 每月保養 |
|---|---|---|---|---|---|
| 0 | 網球場1 | 5 | 25 | 10000 | 200 |
| 1 | 網球場2 | 5 | 25 | 8000 | 200 |
| 2 | 羽毛球法院 | 0 | 15.5 | 4000 | 50 |
| 3 | 乒乓球 | 0 | 5 | 320 | 10 |
| 4 | 按摩室1 | 35 | 80 | 4000 | 3000 |
| 5 | 按摩室2 | 35 | 80 | 4000 | 3000 |
| 6 | 壁球場 | 3.5 | 17.5 | 5000 | 80 |
| 7 | Snooker表 | 0 | 5 | 450 | 15 |
| 8 | 泳池表 | 0 | 5 | 400 | 15 |
| 9 | 溫泉 | 20 | 30 | 100000 | 800 |
回答:
insert into cd . facilities
(facid, name, membercost, guestcost, initialoutlay, monthlymaintenance)
values ( 9 , ' Spa ' , 20 , 30 , 100000 , 800 ); INSERT INTO ... VALUES是將數據插入表中的最簡單方法。這裡沒有很多要討論的內容: VALUES用於構造一排數據,插入語句INSERT插入表中。這很簡單。
您可以看到括號中有兩個部分。第一個是INSERT語句的一部分,並指定了我們提供數據的列。第二個是VALUES的一部分,並指定要插入每列的實際數據。
如果我們將數據插入表的每一列,如本示例,明確指定列名是可選的。只要您填寫表所有表的所有列的數據,就按照您創建表時定義的順序,您就可以執行以下操作:
insert into cd . facilities values ( 9 , ' Spa ' , 20 , 30 , 100000 , 800 );一般而言,對於將要重複使用的SQL,我傾向於傾向於說明並指定列名。
在上一個練習中,您學會瞭如何添加設施。現在,您將在一個命令中添加多個設施。使用以下值:
預期結果:
| FACID | 姓名 | 成員代表 | 來賓代表 | 初始OUTOUTLAY | 每月保養 |
|---|---|---|---|---|---|
| 0 | 網球場1 | 5 | 25 | 10000 | 200 |
| 1 | 網球場2 | 5 | 25 | 8000 | 200 |
| 2 | 羽毛球法院 | 0 | 15.5 | 4000 | 50 |
| 3 | 乒乓球 | 0 | 5 | 320 | 10 |
| 4 | 按摩室1 | 35 | 80 | 4000 | 3000 |
| 5 | 按摩室2 | 35 | 80 | 4000 | 3000 |
| 6 | 壁球場 | 3.5 | 17.5 | 5000 | 80 |
| 7 | Snooker表 | 0 | 5 | 450 | 15 |
| 8 | 泳池表 | 0 | 5 | 400 | 15 |
| 9 | 溫泉 | 20 | 30 | 100000 | 800 |
| 10 | 壁球法院2 | 3.5 | 17.5 | 5000 | 80 |
回答:
insert into cd . facilities
(facid, name, membercost, guestcost, initialoutlay, monthlymaintenance)
values
( 9 , ' Spa ' , 20 , 30 , 100000 , 800 ),
( 10 , ' Squash Court 2 ' , 3 . 5 , 17 . 5 , 5000 , 80 ); 如本示例所示, VALUES可用於生成多個行以插入表中。希望這裡很清楚,這裡發生了什麼: VALUES輸出是一個表,並且該表被複製到CD.FICISITIONS中,該表在INSERT命令中指定的表。
雖然您最常在插入數據時會看到VALUES ,但Postgres允許您在可能使用SELECT任何地方使用VALUES 。這是有道理的:兩個命令的輸出都是一個表,僅在使用恆定數據時, VALUES只是更符合人體工程學。
同樣,可以在看到VALUES任何地方使用SELECT 。這意味著您可以INSERT SELECT的結果。例如:
insert into cd . facilities
(facid, name, membercost, guestcost, initialoutlay, monthlymaintenance)
SELECT 9 , ' Spa ' , 20 , 30 , 100000 , 800
UNION ALL
SELECT 10 , ' Squash Court 2 ' , 3 . 5 , 17 . 5 , 5000 , 80 ;在以後的練習中,您會看到我們使用INSERT ... SELECT以生成數據以基於數據庫中的信息插入。
讓我們嘗試再次將水療中心添加到設施表中。但是,這次我們希望自動生成下一個FACID的值,而不是將其指定為常數。對其他所有內容使用以下值:
預期結果:
| FACID | 姓名 | 成員代表 | 來賓代表 | 初始OUTOUTLAY | 每月保養 |
|---|---|---|---|---|---|
| 0 | 網球場1 | 5 | 25 | 10000 | 200 |
| 1 | 網球場2 | 5 | 25 | 8000 | 200 |
| 2 | 羽毛球法院 | 0 | 15.5 | 4000 | 50 |
| 3 | 乒乓球 | 0 | 5 | 320 | 10 |
| 4 | 按摩室1 | 35 | 80 | 4000 | 3000 |
| 5 | 按摩室2 | 35 | 80 | 4000 | 3000 |
| 6 | 壁球場 | 3.5 | 17.5 | 5000 | 80 |
| 7 | Snooker表 | 0 | 5 | 450 | 15 |
| 8 | 泳池表 | 0 | 5 | 400 | 15 |
| 9 | 溫泉 | 20 | 30 | 100000 | 800 |
回答:
insert into cd . facilities
(facid, name, membercost, guestcost, initialoutlay, monthlymaintenance)
select ( select max (facid) from cd . facilities ) + 1 , ' Spa ' , 20 , 30 , 100000 , 800 ; 在先前的練習中,我們使用VALUES將恆定數據插入設施表中。但是,在這裡,我們有一個新的要求:動態生成的ID。這為我們帶來了真正的生活質量,因為我們不必手動弄清當前最大的ID是什麼:SQL命令為我們做到了。
由於VALUES條款僅用於提供恆定數據,因此我們需要用查詢替換它。 SELECT語句非常簡單:有一個內部子查詢根據最大當前ID來算出下一個faciD,其餘的只是恆定數據。語句的輸出是我們插入設施表中的一行。
儘管這在我們的簡單示例中效果很好,但這並不是您通常在現實世界中實現增量ID的方式。 Postgres插入一行時,Postgres提供的SERIAL類型會自動填充下一個ID。除了節省我們的努力外,這些類型也更安全:與本練習中給出的答案不同,無需擔心並發操作生成相同的ID。
在輸入第二個網球場的數據時,我們犯了一個錯誤。初始支出是10000而不是8000:您需要更改數據以解決錯誤。
預期結果:
| FACID | 姓名 | 成員代表 | 來賓代表 | 初始OUTOUTLAY | 每月保養 |
|---|---|---|---|---|---|
| 0 | 網球場1 | 5 | 25 | 10000 | 200 |
| 1 | 網球場2 | 5 | 25 | 10000 | 200 |
| 2 | 羽毛球法院 | 0 | 15.5 | 4000 | 50 |
| 3 | 乒乓球 | 0 | 5 | 320 | 10 |
| 4 | 按摩室1 | 35 | 80 | 4000 | 3000 |
| 5 | 按摩室2 | 35 | 80 | 4000 | 3000 |
| 6 | 壁球場 | 3.5 | 17.5 | 5000 | 80 |
| 7 | Snooker表 | 0 | 5 | 450 | 15 |
| 8 | 泳池表 | 0 | 5 | 400 | 15 |
回答:
update cd . facilities
set initialoutlay = 10000
where facid = 1 ; UPDATE語句用於更改現有數據。如果您熟悉SELECT查詢,則很容易閱讀: WHERE子句以完全相同的方式工作,從而使我們能夠過濾我們想要使用的一組行。然後根據SET子句的規格修改這些行:在這種情況下,設置初始支出。
WHERE條款極為重要。出於災難性的結果,很容易弄錯它,甚至忽略它。考慮以下命令:
update cd . facilities
set initialoutlay = 10000 ;沒有WHERE子句要過濾我們感興趣的行。結果是,更新在表中的每個行上運行!這很少是我們想發生的事情。
我們想為成員和客人提高網球場的價格。更新成員的成本為6,客人30。
| FACID | 姓名 | 成員代表 | 來賓代表 | 初始OUTOUTLAY | 每月保養 |
|---|---|---|---|---|---|
| 0 | 網球場1 | 6 | 30 | 10000 | 200 |
| 1 | 網球場2 | 6 | 30 | 8000 | 200 |
| 2 | 羽毛球法院 | 0 | 15.5 | 4000 | 50 |
| 3 | 乒乓球 | 0 | 5 | 320 | 10 |
| 4 | 按摩室1 | 35 | 80 | 4000 | 3000 |
| 5 | 按摩室2 | 35 | 80 | 4000 | 3000 |
| 6 | 壁球場 | 3.5 | 17.5 | 5000 | 80 |
| 7 | Snooker表 | 0 | 5 | 450 | 15 |
| 8 | 泳池表 | 0 | 5 | 400 | 15 |
回答:
update cd . facilities
set
membercost = 6 ,
guestcost = 30
where facid in ( 0 , 1 ); SET子句接受您要更新的逗號分開的值列表。
我們想更改第二個網球場的價格,以使其比第一個網球的價格高10%。嘗試在不使用價格恆定值的情況下執行此操作,以便如果需要,我們可以重複使用該語句。
預期結果:
| FACID | 姓名 | 成員代表 | 來賓代表 | 初始OUTOUTLAY | 每月保養 |
|---|---|---|---|---|---|
| 0 | 網球場1 | 5 | 25 | 10000 | 200 |
| 1 | 網球場2 | 5.5 | 27.5 | 8000 | 200 |
| 2 | 羽毛球法院 | 0 | 15.5 | 4000 | 50 |
| 3 | 乒乓球 | 0 | 5 | 320 | 10 |
| 4 | 按摩室1 | 35 | 80 | 4000 | 3000 |
| 5 | 按摩室2 | 35 | 80 | 4000 | 3000 |
| 6 | 壁球場 | 3.5 | 17.5 | 5000 | 80 |
| 7 | Snooker表 | 0 | 5 | 450 | 15 |
| 8 | 泳池表 | 0 | 5 | 400 | 15 |
回答:
update cd . facilities facs
set
membercost = ( select membercost * 1 . 1 from cd . facilities where facid = 0 ),
guestcost = ( select guestcost * 1 . 1 from cd . facilities where facid = 0 )
where facs . facid = 1 ; 基於計算數據的更新列在本質上並不是太困難了:使用子查詢我們可以輕鬆地這樣做。您可以在我們選擇的答案中看到這種方法。
隨著我們要更新的列數量的數量,標準SQL可能會變得非常尷尬:您不想為15個不同的列更新中的每一個指定單獨的子查詢。 Postgres為SQL提供了一個非標準擴展名,稱為UPDATE...FROM從此地址:它允許您提供從FROM提供以生成在SET子句中使用的值。下面的示例:
update cd . facilities facs
set
membercost = facs2 . membercost * 1 . 1 ,
guestcost = facs2 . guestcost * 1 . 1
from ( select * from cd . facilities where facid = 0 ) facs2
where facs . facid = 1 ;作為清除數據庫的一部分,我們希望從CD.Bookings表中刪除所有預訂。我們如何實現這一目標?
預期結果:
| Bookid | FACID | 梅德 | 開始時間 | 老虎機 |
|---|---|---|---|---|
回答:
delete from cd . bookings ; DELETE語句在錫上說的是從表中刪除行上的話。在這裡,我們以最簡單的形式顯示命令,沒有預選賽。在這種情況下,它會刪除表中的所有內容。顯然,您應該謹慎刪除,並確保它們始終有限 - 我們將在下一個練習中查看如何做到這一點。
無限制DELETE的替代方案是以下內容:
truncate cd . bookings ; TRUNCATE還刪除了表中的所有內容,但是使用較快的基礎機制來進行。但是,在任何情況下,這都不是完全安全的,因此請明智地使用。如有疑問,請使用DELETE 。
我們想從我們的數據庫中刪除從未預訂的成員37。我們該如何實現?
預期結果:
| 梅德 | 姓 | 名 | 地址 | 郵遞區號 | 電話 | 推薦 | 加入 |
|---|---|---|---|---|---|---|---|
| 0 | 客人 | 客人 | 客人 | 0 | (000)000-0000 | 2012-07-01 00:00:00 | |
| 1 | 史密斯 | 達倫 | 8 Bloomsbury Close,波士頓 | 4321 | 555-555-5555 | 2012-07-02 12:02:05 | |
| 2 | 史密斯 | 特雷西 | 8布盧姆斯伯里關閉,紐約 | 4321 | 555-555-5555 | 2012-07-02 12:08:23 | |
| 3 | 羅恩南 | 蒂姆 | 23 Highway Way,波士頓 | 23423 | (844)693-0723 | 2012-07-03 09:32:15 | |
| 4 | 喬普特 | 珍妮絲 | 紐約十字路20號 | 234 | (833)942-4710 | 1 | 2012-07-03 10:25:05 |
| 5 | 奶油 | 杰拉爾德 | 波士頓亨廷頓大街1065號 | 56754 | (844)078-4130 | 1 | 2012-07-09 10:44:09 |
| 6 | 特雷西 | 伯頓 | 3突尼斯大道,波士頓 | 45678 | (822)354-9973 | 2012-07-15 08:52:55 | |
| 7 | 敢 | 南希 | 波士頓6狩獵小屋 | 10383 | (833)776-4001 | 4 | 2012-07-25 08:59:12 |
| 8 | 展位 | 蒂姆 | 3 Bloomsbury Close,Reading,00234 | 234 | (811)433-2547 | 3 | 2012-07-25 16:02:35 |
| 9 | Stibbons | 思考 | 5龍之路,溫徹斯特 | 87630 | (833)160-3900 | 6 | 2012-07-25 17:09:05 |
| 10 | 歐文 | 查爾斯 | 52 Cheshire Grove,溫徹斯特,28563 | 28563 | (855)542-5251 | 1 | 2012-08-03 19:42:37 |
| 11 | 瓊斯 | 大衛 | 976 gnats關閉,閱讀 | 33862 | (844)536-8036 | 4 | 2012-08-06 16:32:55 |
| 12 | 貝克 | 安妮 | 波士頓粉狀街55號 | 80743 | 844-076-5141 | 9 | 2012-08-10 14:23:22 |
| 13 | 法雷爾 | 傑米瑪 | 北雷丁的Firth Avenue 103 | 57392 | (855)016-0163 | 2012-08-10 14:28:01 | |
| 14 | 史密斯 | 傑克 | 252 Binkington Way,波士頓 | 69302 | (822)163-3254 | 1 | 2012-08-10 16:22:05 |
| 15 | 壞人 | 佛羅倫斯 | 韋斯特福德264 Ursula Drive | 84923 | (833)499-3527 | 9 | 2012-08-10 17:52:03 |
| 16 | 貝克 | 蒂莫西 | 詹姆斯街329號,閱讀 | 58393 | 833-941-0824 | 13 | 2012-08-15 10:34:25 |
| 17 | 平克 | 大衛 | 波士頓Impreza Road 5 | 65332 | 811 409-6734 | 13 | 2012-08-16 11:32:47 |
| 20 | 雲頂 | 馬修 | 4 Nunnington Place,Wingfield,波士頓 | 52365 | (811)972-1377 | 5 | 2012-08-19 14:55:55 |
| 21 | 麥肯齊 | 安娜 | 64 Perkington Lane,閱讀 | 64577 | (822)661-2898 | 1 | 2012-08-26 09:32:05 |
| 22 | 科普林 | 瓊 | 波士頓布盧明頓Bard Street 85 | 43533 | (822)499-2232 | 16 | 2012-08-29 08:32:41 |
| 24 | 薩爾文 | 拉姆納雷什 | 波士頓的布丁頓巷12號 | 65464 | (822)413-1470 | 15 | 2012-09-01 08:44:42 |
| 26 | 瓊斯 | 道格拉斯 | 976 gnats關閉,閱讀 | 11986 | 844 536-8036 | 11 | 2012-09-02 18:43:05 |
| 27 | 拉姆尼 | 亨利埃塔 | 3伯金頓廣場,波士頓 | 78533 | (822)989-8876 | 20 | 2012-09-05 08:42:35 |
| 28 | 法雷爾 | 大衛 | 韋斯特福德的437 Granite Farm Road | 43532 | (855)755-9876 | 2012-09-15 08:22:05 | |
| 29 | Worthington-Smyth | 亨利 | 55 Jagbi Way,North Reading | 97676 | (855)894-3758 | 2 | 2012-09-17 12:27:15 |
| 30 | 範圍 | 米里森 | 641繁瑣的關閉,波士頓伯寧頓 | 34232 | (855)941-9786 | 2 | 2012-09-18 19:04:01 |
| 33 | 特百惠 | 風信子 | 韋斯特福德的德雷克路33號開朗廣場 | 68666 | (822)665-5327 | 2012-09-18 19:32:05 | |
| 35 | 打獵 | 約翰 | 5波士頓的布靈頓巷 | 54333 | (899)720-6978 | 30 | 2012-09-19 11:32:45 |
| 36 | 碎屑 | 埃里卡 | 北雷丁深紅色路 | 75655 | (811)732-4816 | 2 | 2012-09-22 08:36:38 |
回答:
delete from cd . members where memid = 37 ; 這項練習對我們以前的練習是一個小的增量。這次我們希望成為更有目標的,而不是刪除所有預訂,而是刪除從未進行預訂的單個成員。為此,我們只需在命令中添加一個WHERE ,指定要刪除的成員。您可以在此處查看與SELECT和UPDATE語句的相似之處。
這裡有一個有趣的皺紋。嘗試使用此命令,但代替成員ID 0。該成員已經進行了許多預訂,您會發現刪除失敗會出現違反外鍵約束的錯誤。這是關係數據庫中的重要概念,因此讓我們進一步探索。
外鍵是定義不同表列之間關係的機制。在我們的情況下,我們使用它們來指定預訂表的MEMID列與成員表的MEMID列有關。關係(或“約束”)指定對於給定的預訂,預訂中指定的成員必須存在於成員表中。擁有該數據庫執行此保證是有用的:這意味著使用數據庫的代碼可以依靠成員的存在。在更高級別上執行此操作是很難的(甚至不可能):並發操作可以乾擾並將數據庫留在破裂狀態。
PostgreSQL支持各種不同類型的約束,使您可以在數據上執行結構。有關約束的更多信息,請查看外國鑰匙的PostgreSQL文檔
在以前的練習中,我們刪除了從未進行預訂的特定成員。我們如何使這一更為籠統,刪除從未進行預訂的所有成員?
預期結果:
| 梅德 | 姓 | 名 | 地址 | 郵遞區號 | 電話 | 推薦 | 加入 |
|---|---|---|---|---|---|---|---|
| 0 | 客人 | 客人 | 客人 | 0 | (000)000-0000 | 2012-07-01 00:00:00 | |
| 1 | 史密斯 | 達倫 | 8 Bloomsbury Close,波士頓 | 4321 | 555-555-5555 | 2012-07-02 12:02:05 | |
| 2 | 史密斯 | 特雷西 | 8布盧姆斯伯里關閉,紐約 | 4321 | 555-555-5555 | 2012-07-02 12:08:23 | |
| 3 | 羅恩南 | 蒂姆 | 23 Highway Way,波士頓 | 23423 | (844)693-0723 | 2012-07-03 09:32:15 | |
| 4 | 喬普特 | 珍妮絲 | 紐約十字路20號 | 234 | (833)942-4710 | 1 | 2012-07-03 10:25:05 |
| 5 | 奶油 | 杰拉爾德 | 波士頓亨廷頓大街1065號 | 56754 | (844)078-4130 | 1 | 2012-07-09 10:44:09 |
| 6 | 特雷西 | 伯頓 | 3突尼斯大道,波士頓 | 45678 | (822)354-9973 | 2012-07-15 08:52:55 | |
| 7 | 敢 | 南希 | 波士頓6狩獵小屋 | 10383 | (833)776-4001 | 4 | 2012-07-25 08:59:12 |
| 8 | 展位 | 蒂姆 | 3 Bloomsbury Close,Reading,00234 | 234 | (811)433-2547 | 3 | 2012-07-25 16:02:35 |
| 9 | Stibbons | 思考 | 5龍之路,溫徹斯特 | 87630 | (833)160-3900 | 6 | 2012-07-25 17:09:05 |
| 10 | 歐文 | 查爾斯 | 52 Cheshire Grove,溫徹斯特,28563 | 28563 | (855)542-5251 | 1 | 2012-08-03 19:42:37 |
| 11 | 瓊斯 | 大衛 | 976 gnats關閉,閱讀 | 33862 | (844)536-8036 | 4 | 2012-08-06 16:32:55 |
| 12 | 貝克 | 安妮 | 波士頓粉狀街55號 | 80743 | 844-076-5141 | 9 | 2012-08-10 14:23:22 |
| 13 | 法雷爾 | 傑米瑪 | 北雷丁的Firth Avenue 103 | 57392 | (855)016-0163 | 2012-08-10 14:28:01 | |
| 14 | 史密斯 | 傑克 | 252 Binkington Way,波士頓 | 69302 | (822)163-3254 | 1 | 2012-08-10 16:22:05 |
| 15 | 壞人 | 佛羅倫斯 | 韋斯特福德264 Ursula Drive | 84923 | (833)499-3527 | 9 | 2012-08-10 17:52:03 |
| 16 | 貝克 | 蒂莫西 | 詹姆斯街329號,閱讀 | 58393 | 833-941-0824 | 13 | 2012-08-15 10:34:25 |
| 17 | 平克 | 大衛 | 波士頓Impreza Road 5 | 65332 | 811 409-6734 | 13 | 2012-08-16 11:32:47 |
| 20 | 雲頂 | 馬修 | 4 Nunnington Place,Wingfield,波士頓 | 52365 | (811)972-1377 | 5 | 2012-08-19 14:55:55 |
| 21 | 麥肯齊 | 安娜 | 64 Perkington Lane,閱讀 | 64577 | (822)661-2898 | 1 | 2012-08-26 09:32:05 |
| 22 | 科普林 | 瓊 | 波士頓布盧明頓Bard Street 85 | 43533 | (822)499-2232 | 16 | 2012-08-29 08:32:41 |
| 24 | 薩爾文 | 拉姆納雷什 | 波士頓的布丁頓巷12號 | 65464 | (822)413-1470 | 15 | 2012-09-01 08:44:42 |
| 26 | 瓊斯 | 道格拉斯 | 976 gnats關閉,閱讀 | 11986 | 844 536-8036 | 11 | 2012-09-02 18:43:05 |
| 27 | 拉姆尼 | 亨利埃塔 | 3伯金頓廣場,波士頓 | 78533 | (822)989-8876 | 20 | 2012-09-05 08:42:35 |
| 28 | 法雷爾 | 大衛 | 韋斯特福德的437 Granite Farm Road | 43532 | (855)755-9876 | 2012-09-15 08:22:05 | |
| 29 | Worthington-Smyth | 亨利 | 55 Jagbi Way,North Reading | 97676 | (855)894-3758 | 2 | 2012-09-17 12:27:15 |
| 30 | 範圍 | 米里森 | 641繁瑣的關閉,波士頓伯寧頓 | 34232 | (855)941-9786 | 2 | 2012-09-18 19:04:01 |
| 33 | 特百惠 | 風信子 | 韋斯特福德的德雷克路33號開朗廣場 | 68666 | (822)665-5327 | 2012-09-18 19:32:05 | |
| 35 | 打獵 | 約翰 | 5波士頓的布靈頓巷 | 54333 | (899)720-6978 | 30 | 2012-09-19 11:32:45 |
| 36 | 碎屑 | 埃里卡 | 北雷丁深紅色路 | 75655 | (811)732-4816 | 2 | 2012-09-22 08:36:38 |
回答:
delete from cd . members where memid not in ( select memid from cd . bookings ); 我們可以使用子查詢來確定是否應刪除一行。有幾種標準方法可以做到這一點。在我們的特色答案中,該子查詢在CD.Bookings表中產生了所有不同成員ID的列表。如果表中的一行不在子查詢生成的列表中,則將被刪除。
另一種選擇是使用相關的子查詢。如果我們以前的示例一次運行一個大型子查詢,則相關方法相反,指定一個較小的子查詢對每行的運行。
delete from cd . members mems where not exists ( select 1 from cd . bookings where memid = mems . memid );兩種不同的形式可以具有不同的性能特徵。在引擎蓋下,您的數據庫引擎可以自由轉換查詢以相關或不相關的方式執行該查詢,因此很難預測情況。
聚合是真正使您欣賞關係數據庫系統的力量的功能之一。它使您可以超越僅保留數據,進入一個真正有趣的問題的領域,這些問題可用於為決策提供信息。此類別詳細介紹了聚合,利用標準分組以及更新的窗口功能。
如果您在這些問題上掙扎,我強烈建議Alan Beaulieu和Anthony Molinaro的SQL食譜Learning SQL。實際上,無論如何都可以獲取後者 - 它將帶您超越您在此站點上找到的任何內容,以及在多個不同的數據庫系統上啟動。
對於我們第一次進入聚集體,我們將堅持一些簡單的事情。我們想知道存在多少個設施 - 只需產生總數即可。
預期結果:
| 數數 |
|---|
| 9 |
回答:
select count ( * ) from cd . facilities ; 聚集起來很簡單!上面的SQL從我們的設施表中選擇所有內容,然後計算結果集中的行數。計數功能有多種用途:
COUNT(*)簡單地返回行數COUNT(address)計數結果集中的非NULL地址的數量。COUNT(DISTINCT address)計數設施表中不同地址的數量。匯總函數的基本思想是,它採用一列數據,對其執行一些函數,並輸出標量(單個)值。有更多的聚合功能,包括MAX , MIN , SUM和AVG 。這些都做了您從他們的名字中所期望的:-)。
人們經常發現令人困惑的匯總功能的一個方面是查詢如下:
select facid, count ( * ) from cd . facilities嘗試一下,您會發現它不起作用。這是因為Count(*)希望將設施表折疊成一個值 - 不幸的是,它不能做到這一點,因為CD.FACISICITIONS中有很多不同的位置 - Postgres不知道哪個方面可以與計數配對。
相反,如果您想要一個查詢,以返回所有面板以及每行的計數,則可以將匯總分解為以下的子查詢:
select facid,
( select count ( * ) from cd . facilities )
from cd . facilities當我們有一個返回這樣的標量值的子查詢時,Postgres知道只需重複CD.FACISISITIONS中每個行的值即可。
生產有10個或更多客人的設施數量。
| 數數 |
|---|
| 6 |
回答:
select count ( * ) from cd . facilities where guestcost >= 10 ; 這只是對上一個問題的簡單修改:我們需要淘汰便宜的設施。使用WHERE子句很容易做到這一點。現在,我們的聚合只能看到昂貴的設施。
產生每個成員提出的建議數量的計數。按會員ID訂購。
預期結果:
| 推薦 | 數數 |
|---|---|
| 1 | 5 |
| 2 | 3 |
| 3 | 1 |
| 4 | 2 |
| 5 | 1 |
| 6 | 1 |
| 9 | 2 |
| 11 | 1 |
| 13 | 2 |
| 15 | 1 |
| 16 | 1 |
| 20 | 1 |
| 30 | 1 |
回答:
select recommendedby, count ( * )
from cd . members
where recommendedby is not null
group by recommendedby
order by recommendedby; 以前,我們已經看到聚合函數應用於值列,並將它們轉換為聚合的標量值。這很有用,但是我們經常發現我們不需要一個匯總的結果:例如,我不知道俱樂部本月賺取的總金額,而是想知道每個不同設施所賺多少錢,或者一天中的哪個時間最有利可圖。
為了支持這種行為,SQL GROUP BY 。這樣做的是將數據分組在一起,並為每個組分別運行聚合函數。當您通過一GROUP BY指定時,數據庫會在所提供的列中為每個不同值產生一個匯總值。在這種情況下,我們要說的是“針對推薦的每個獨特價值,請給我一個值出現的次數”。
生成每個設施預訂的老虎機總數的列表。目前,只需製作一個由設施ID和插槽組成的輸出表,並通過設施ID排序。
預期結果:
| FACID | 總插槽 |
|---|---|
| 0 | 1320 |
| 1 | 1278 |
| 2 | 1209 |
| 3 | 830 |
| 4 | 1404 |
| 5 | 228 |
| 6 | 1104 |
| 7 | 908 |
| 8 | 911 |
回答:
select facid, sum (slots) as " Total Slots "
from cd . bookings
group by facid
order by facid; 除了我們介紹了SUM函數的事實外,關於這項練習的事實並不多。對於每個不同的設施ID, SUM函數將插槽列中的所有內容添加在一起。
生成2012年9月在每個設施中預訂的插槽總數的列表。生產一個由設施ID和插槽組成的輸出表,並按插槽數量排序。
預期結果:
| FACID | 總插槽 |
|---|---|
| 5 | 122 |
| 3 | 422 |
| 7 | 426 |
| 8 | 471 |
| 6 | 540 |
| 2 | 570 |
| 1 | 588 |
| 0 | 591 |
| 4 | 648 |
回答:
select facid, sum (slots) as " Total Slots "
from cd . bookings
where
starttime >= ' 2012-09-01 '
and starttime < ' 2012-10-01 '
group by facid
order by sum (slots); 這只是我們上一個示例的一個小變化。請記住,聚集在評估WHERE子句之後發生:因此,我們使用WHERE我們匯總的數據,而我們的聚合只能看到一個月的數據。
製作2012年每月預訂每月預訂的插槽總數的列表。生產一個由ID和月份排序的設施ID和插槽組成的輸出表。
預期結果:
| FACID | 月 | 總插槽 |
|---|---|---|
| 0 | 7 | 270 |
| 0 | 8 | 459 |
| 0 | 9 | 591 |
| 1 | 7 | 207 |
| 1 | 8 | 483 |
| 1 | 9 | 588 |
| 2 | 7 | 180 |
| 2 | 8 | 459 |
| 2 | 9 | 570 |
| 3 | 7 | 104 |
| 3 | 8 | 304 |
| 3 | 9 | 422 |
| 4 | 7 | 264 |
| 4 | 8 | 492 |
| 4 | 9 | 648 |
| 5 | 7 | 24 |
| 5 | 8 | 82 |
| 5 | 9 | 122 |
| 6 | 7 | 164 |
| 6 | 8 | 400 |
| 6 | 9 | 540 |
| 7 | 7 | 156 |
| 7 | 8 | 326 |
| 7 | 9 | 426 |
| 8 | 7 | 117 |
| 8 | 8 | 322 |
| 8 | 9 | 471 |
回答:
select facid, extract(month from starttime) as month, sum (slots) as " Total Slots "
from cd . bookings
where
starttime >= ' 2012-01-01 '
and starttime < ' 2013-01-01 '
group by facid, month
order by facid, month; 這個問題的新功能的主要部分是EXTRACT功能。 EXTRACT允許您獲得時間戳的單個組件,例如日,月,年等。我們按照此功能的輸出進行分組以提供每月值。如果我們需要區分不同年份的同一個月,則替代方案是使用DATE_TRUNC函數,該功能將日期截斷為給定的粒度。
還值得注意的是,這是我們第一次真正利用多個列進行分組的能力。
找到至少進行一次預訂的成員總數。
預期結果:
| 數數 |
|---|
| 30 |
回答:
select count (distinct memid) from cd . bookings 您的第一個本能可能是在這裡尋求一個副標題。類似以下內容:
select count ( * ) from
( select distinct memid from cd . bookings ) as mems這確實很好地工作了,但是我們可以藉助一些額外的知識來簡化觸摸,以COUNT DISTINCT形式。這可以實現您可能期望的,併計算傳遞列中的不同值。
製作了預訂1000多個插槽的設施列表。產生由設施ID和小時數組成的輸出表,並按設施ID排序。
預期結果:
| FACID | 總插槽 |
|---|---|
| 0 | 1320 |
| 1 | 1278 |
| 2 | 1209 |
| 4 | 1404 |
| 6 | 1104 |
回答:
select facid, sum (slots) as " Total Slots "
from cd . bookings
group by facid
having sum (slots) > 1000
order by facid 事實證明,實際上有一個SQL關鍵字旨在幫助從聚合功能過濾輸出。此關鍵字HAVING 。
HAVING的行為很容易與WHERE混淆。思考它的最佳方法是,在具有聚合函數的查詢的上下文中, WHERE過濾哪些數據輸入到聚合函數中,而一旦HAVING從函數輸出後用於過濾數據。嘗試嘗試探索這種差異!
制定設施清單及其總收入。輸出表應由設施名稱和收入組成,並按收入排序。請記住,對於客人和成員來說,費用有所不同!
預期結果:
| 姓名 | 收入 |
|---|---|
| 乒乓球 | 180 |
| Snooker表 | 240 |
| 泳池表 | 270 |
| 羽毛球法院 | 1906.5 |
| 壁球場 | 13468.0 |
| 網球場1 | 13860 |
| 網球場2 | 14310 |
| 按摩室2 | 15810 |
| 按摩室1 | 72540 |
回答:
select facs . name , sum (slots * case
when memid = 0 then facs . guestcost
else facs . membercost
end) as revenue
from cd . bookings bks
inner join cd . facilities facs
on bks . facid = facs . facid
group by facs . name
order by revenue; 此查詢中唯一的真正複雜性是客人(成員ID 0)對其他所有人都有不同的成本。我們使用案例聲明為每個會話產生成本,然後總和由設施分組的每個會話。
生產總收入少於1000的設施清單。生產由設施名稱和收入組成的輸出表,並按收入排序。請記住,對於客人和成員來說,費用有所不同!
預期結果:
| 姓名 | 收入 |
|---|---|
| 乒乓球 | 180 |
| Snooker表 | 240 |
| 泳池表 | 270 |
回答:
select name, revenue from (
select facs . name , sum (case
when memid = 0 then slots * facs . guestcost
else slots * membercost
end) as revenue
from cd . bookings bks
inner join cd . facilities facs
on bks . facid = facs . facid
group by facs . name
) as agg where revenue < 1000
order by revenue; 您很可能已經嘗試使用我們在較早練習中引入的HAVING ,並產生以下類似的內容:
select facs . name , sum (case
when memid = 0 then slots * facs . guestcost
else slots * membercost
end) as revenue
from cd . bookings bks
inner join cd . facilities facs
on bks . facid = facs . facid
group by facs . name
having revenue < 1000
order by revenue;不幸的是,這無效!您將沿著ERROR: column "revenue" does not exist 。與SQL Server和MySQL等其他一些RDBMS不同,Postgres不支持將列名放在HAVING子句中。這意味著要進行此查詢的工作,您必須產生以下內容:
select facs . name , sum (case
when memid = 0 then slots * facs . guestcost
else slots * membercost
end) as revenue
from cd . bookings bks
inner join cd . facilities facs
on bks . facid = facs . facid
group by facs . name
having sum (case
when memid = 0 then slots * facs . guestcost
else slots * membercost
end) < 1000
order by revenue;必須重複這樣的重大計算代碼是凌亂的,因此我們的膏解決方案只是將主查詢體作為子查詢包裹,然後使用WHERE子句從中選擇。通常,我建議使用簡單HAVING ,因為它會提高清晰度。否則,這種子查詢方法通常更容易使用。
輸出預訂插槽數量最多的設施ID。對於獎勵積分,請嘗試一個沒有限制條款的版本。這個版本可能看起來很混亂!
預期結果:
| FACID | 總插槽 |
|---|---|
| 4 | 1404 |
回答:
select facid, sum (slots) as " Total Slots "
from cd . bookings
group by facid
order by sum (slots) desc
LIMIT 1 ; 讓我們從可以說的最簡單方法開始:製作設施ID的列表和所使用的插槽總數,按使用的插槽總數訂購,僅選擇最佳結果。
但是,值得一提的是,這種方法具有重大弱點。如果有領帶,我們仍然只會得到一個結果!為了獲得所有相關結果,我們可能會嘗試使用MAX匯總函數,類似以下內容:
select facid, max (totalslots) from (
select facid, sum (slots) as totalslots
from cd . bookings
group by facid
) as sub group by facid此查詢的目的是獲得最高的總體插槽值及其相關的位置。不幸的是,這只是行不通的!如果有多個facid的插槽數量相同,則應該將facid與MAX函數中的單個(或標量)值配對。這意味著Postgres會告訴您,Facid應該GROUP BY ,這不會產生我們想要的結果。
讓我們第一次刺入工作查詢:
select facid, sum (slots) as totalslots
from cd . bookings
group by facid
having sum (slots) = ( select max ( sum2 . totalslots ) from
( select sum (slots) as totalslots
from cd . bookings
group by facid
) as sum2);該查詢產生了設施ID的列表和所使用的插槽數,然後使用一個符合最大總體插槽值的子句。我們從本質上說:“製作一份列表及其預訂的老虎機數量,並過濾出所有沒有等於最大值的插槽的所有插槽。”
但是,我們的查詢非常HAVING 。為了改善這一點,讓我們介紹另一個新概念:常見表表達式(CTE)。可以將CTE視為允許您在查詢中定義數據庫視圖內聯。在這樣的情況下,這確實很有幫助,您必須重複很多自己。
CTE WITH CTEName as (SQL-Expression)以形式聲明。您可以重新定義我們的查詢以使用以下CTE:
with sum as ( select facid, sum (slots) as totalslots
from cd . bookings
group by facid
)
select facid, totalslots
from sum
where totalslots = ( select max (totalslots) from sum);您可以看到,我們已經從CD.Bookings中重複選擇了單個CTE的重複選擇,並使查詢在此過程中更容易閱讀!
但是等等。還有更多。也可以使用窗口函數來完成此問題。我們將其保留到以後,但是可以更好地解決此類問題。
單個練習是很多信息。如果您現在不現在就不用,請不要擔心 - 我們將在以後的練習中重複使用這些概念。
製作2012年每月預訂的每個設施總數的總數列表。在此版本中,包括包含每個設施的所有月份的輸出行,以及所有設施的所有月總數。輸出表應由設施ID,月份和插槽組成,並按ID和月份排序。在計算所有月份和所有範圍的匯總值時,在月份返回零值和facid列。
預期結果:
| FACID | 月 | 老虎機 |
|---|---|---|
| 0 | 7 | 270 |
| 0 | 8 | 459 |
| 0 | 9 | 591 |
| 0 | 1320 | |
| 1 | 7 | 207 |
| 1 | 8 | 483 |
| 1 | 9 | 588 |
| 1 | 1278 | |
| 2 | 7 | 180 |
| 2 | 8 | 459 |
| 2 | 9 | 570 |
| 2 | 1209 | |
| 3 | 7 | 104 |
| 3 | 8 | 304 |
| 3 | 9 | 422 |
| 3 | 830 | |
| 4 | 7 | 264 |
| 4 | 8 | 492 |
| 4 | 9 | 648 |
| 4 | 1404 | |
| 5 | 7 | 24 |
| 5 | 8 | 82 |
| 5 | 9 | 122 |
| 5 | 228 | |
| 6 | 7 | 164 |
| 6 | 8 | 400 |
| 6 | 9 | 540 |
| 6 | 1104 | |
| 7 | 7 | 156 |
| 7 | 8 | 326 |
| 7 | 9 | 426 |
| 7 | 908 | |
| 8 | 7 | 117 |
| 8 | 8 | 322 |
| 8 | 9 | 471 |
| 8 | 910 | |
| 9191 |
回答:
select facid, extract(month from starttime) as month, sum (slots) as slots
from cd . bookings
where
starttime >= ' 2012-01-01 '
and starttime < ' 2013-01-01 '
group by rollup(facid, month)
order by facid, month; 當我們進行數據分析時,有時我們希望執行多個級別的聚合,以使自己可以“放大”到不同的深度。在這種情況下,我們可能會查看每個設施的整體用法,但隨後想潛入來看看它們的每月表現。到目前為止,使用我們知道的SQL,產生一個可以執行我們想要的單個查詢非常繁瑣 - 我們有效地訴諸使用UNION ALL Compate condentent condentent:
select facid, extract(month from starttime) as month, sum (slots) as slots
from cd . bookings
where
starttime >= ' 2012-01-01 '
and starttime < ' 2013-01-01 '
group by facid, month
union all
select facid, null , sum (slots) as slots
from cd . bookings
where
starttime >= ' 2012-01-01 '
and starttime < ' 2013-01-01 '
group by facid
union all
select null , null , sum (slots) as slots
from cd . bookings
where
starttime >= ' 2012-01-01 '
and starttime < ' 2013-01-01 '
order by facid, month;如您所見,每個子查詢都執行不同級別的聚合,我們只是將結果結合在一起。我們可以通過使用CTE考慮共同點來清理很多:
with bookings as (
select facid, extract(month from starttime) as month, slots
from cd . bookings
where
starttime >= ' 2012-01-01 '
and starttime < ' 2013-01-01 '
)
select facid, month, sum (slots) from bookings group by facid, month
union all
select facid, null , sum (slots) from bookings group by facid
union all
select null , null , sum (slots) from bookings
order by facid, month;這個版本在眼睛上並不難,但是隨著聚合列的數量增加,它變得繁瑣。幸運的是,PostgreSQL 9.5引入了對ROLLUP操作員的支持,我們用來簡化了我們接受的答案。
ROLLUP在傳遞的順序中產生聚合的層次結構:例如, ROLLUP(facid, month)輸出(facid,月份),(facID)和()的聚合。如果我們想要一個月的所有設施(而不是設施的所有月份),我們必須使用ROLLUP(month, facid)扭轉訂單。另外,如果我們希望我們傳遞的列的所有可能排列,則可以使用立方體而不是ROLLUP 。這將產生(FACID,月),(月),(FACID)和()。
ROLLUP和CUBE是GROUPING SETS的特殊情況。 GROUPING SETS允許您指定所需的確切聚合排列:例如,您可以要求(facid,一個月)和(facid)跳過頂級聚合。
列出每個設施預訂的小時數的列表,記住一個插槽持續半小時。輸出表應由設施ID,名稱和預訂的小時數組成,並按設施ID排序。嘗試將小時的格式化為兩個小數點。
預期結果:
| FACID | 姓名 | 總小時 |
|---|---|---|
| 0 | 網球場1 | 660.00 |
| 1 | 網球場2 | 639.00 |
| 2 | 羽毛球法院 | 604.50 |
| 3 | 乒乓球 | 415.00 |
| 4 | 按摩室1 | 702.00 |
| 5 | 按摩室2 | 114.00 |
| 6 | 壁球場 | 552.00 |
| 7 | Snooker表 | 454.00 |
| 8 | 泳池表 | 455.50 |
回答:
select facs . facid , facs . name ,
trim (to_char( sum ( bks . slots ) / 2 . 0 , ' 9999999999999999D99 ' )) as " Total Hours "
from cd . bookings bks
inner join cd . facilities facs
on facs . facid = bks . facid
group by facs . facid , facs . name
order by facs . facid ; 這個問題有一些小興趣。首先,您可以看到,當我們以1:1的基礎加入另一個表格時,我們的聚合效果很好。另請注意,我們由facs.facid和facs.name進行分組。這似乎很奇怪:畢竟,由於facid是設施表的主要鑰匙,因此每個facid都有一個名稱,並且通過兩個字段進行分組與單獨的FACID分組相同。實際上,您會發現,如果您刪除facs.name by GROUP BY Crause,則查詢工作正常:Postgres算出,此1:1映射存在,並且不堅持我們將這兩個列分組。
不幸的是,根據我們使用的數據庫系統,驗證可能不是那麼聰明,並且可能不會意識到映射嚴格是1:1。情況就是這樣,如果每個facid都有多個names ,並且我們沒有按name進行分組,則DBMS必須在多個(同樣有效)的name中選擇。由於這是無效的,因此數據庫系統將堅持我們通過兩個字段進行分組。通常,我建議通過所有列進行分組,您沒有匯總功能:這將確保更好的跨平台兼容性。
接下來是分區。那些熟悉MySQL的人可能會意識到整數部門會自動投入到浮子上。在這方面,Postgres有點傳統,並希望您能告訴它,如果您想要浮點劃分。在這種情況下,您可以通過分配2.0而不是2來輕鬆做到這一點。
最後,讓我們看格式化。 TO_CHAR函數將值轉換為字符字符串。它需要一個格式的字符串,我們將其指定為(多達)小數位,十進制位置和十進制位置之後的兩個數字。該函數的輸出可以用一個空間進行預培養,這就是為什麼我們包含外部TRIM函數的原因。
在2012年9月1日之後生成每個會員名稱,ID和他們的第一次預訂的列表。按會員ID訂購。
預期結果:
| 姓 | 名 | 梅德 | 開始時間 |
|---|---|---|---|
| 客人 | 客人 | 0 | 2012-09-01 08:00:00 |
| 史密斯 | 達倫 | 1 | 2012-09-01 09:00:00 |
| 史密斯 | 特雷西 | 2 | 2012-09-01 11:30:00 |
| 羅恩南 | 蒂姆 | 3 | 2012-09-01 16:00:00 |
| 喬普特 | 珍妮絲 | 4 | 2012-09-01 15:00:00 |
| 奶油 | 杰拉爾德 | 5 | 2012-09-02 12:30:00 |
| 特雷西 | 伯頓 | 6 | 2012-09-01 15:00:00 |
| 敢 | 南希 | 7 | 2012-09-01 12:30:00 |
| 展位 | 蒂姆 | 8 | 2012-09-01 08:30:00 |
| Stibbons | 思考 | 9 | 2012-09-01 11:00:00 |
| 歐文 | 查爾斯 | 10 | 2012-09-01 11:00:00 |
| 瓊斯 | 大衛 | 11 | 2012-09-01 09:30:00 |
| 貝克 | 安妮 | 12 | 2012-09-01 14:30:00 |
| 法雷爾 | 傑米瑪 | 13 | 2012-09-01 09:30:00 |
| 史密斯 | 傑克 | 14 | 2012-09-01 11:00:00 |
| 壞人 | 佛羅倫斯 | 15 | 2012-09-01 10:30:00 |
| 貝克 | 蒂莫西 | 16 | 2012-09-01 15:00:00 |
| 平克 | 大衛 | 17 | 2012-09-01 08:30:00 |
| 雲頂 | 馬修 | 20 | 2012-09-01 18:00:00 |
| 麥肯齊 | 安娜 | 21 | 2012-09-01 08:30:00 |
| 科普林 | 瓊 | 22 | 2012-09-02 11:30:00 |
| 薩爾文 | 拉姆納雷什 | 24 | 2012-09-04 11:00:00 |
| 瓊斯 | 道格拉斯 | 26 | 2012-09-08 13:00:00 |
| 拉姆尼 | 亨利埃塔 | 27 | 2012-09-16 13:30:00 |
| 法雷爾 | 大衛 | 28 | 2012-09-18 09:00:00 |
| Worthington-Smyth | 亨利 | 29 | 2012-09-19 09:30:00 |
| 範圍 | 米里森 | 30 | 2012-09-19 11:30:00 |
| 特百惠 | 風信子 | 33 | 2012-09-20 08:00:00 |
| 打獵 | 約翰 | 35 | 2012-09-23 14:00:00 |
| 碎屑 | 埃里卡 | 36 | 2012-09-27 11:30:00 |
回答:
select mems . surname , mems . firstname , mems . memid , min ( bks . starttime ) as starttime
from cd . bookings bks
inner join cd . members mems on
mems . memid = bks . memid
where starttime >= ' 2012-09-01 '
group by mems . surname , mems . firstname , mems . memid
order by mems . memid ; 該答案證明了在日期使用聚合功能的使用。 MIN完全按照您的預期工作,從結果集中提取了最低日期。為了進行這項工作,我們需要確保結果集僅包含9月開始的日期。我們使用WHERE子句來做到這一點。
您通常可以使用這樣的查詢來查找客戶的下一個預訂。您可以通過使用函數替換日期'2012-09-01'來使用此功能now()
產生成員名稱列表,每行包含總成員數量。加入日期訂購。
預期結果:
| 數數 | 名 | 姓 |
|---|---|---|
| 31 | 客人 | 客人 |
| 31 | 達倫 | 史密斯 |
| 31 | 特雷西 | 史密斯 |
| 31 | 蒂姆 | 羅恩南 |
| 31 | 珍妮絲 | 喬普特 |
| 31 | 杰拉爾德 | 奶油 |
| 31 | 伯頓 | 特雷西 |
| 31 | 南希 | 敢 |
| 31 | 蒂姆 | 展位 |
| 31 | 思考 | Stibbons |
| 31 | 查爾斯 | 歐文 |
| 31 | 大衛 | 瓊斯 |
| 31 | 安妮 | 貝克 |
| 31 | 傑米瑪 | 法雷爾 |
| 31 | 傑克 | 史密斯 |
| 31 | 佛羅倫斯 | 壞人 |
| 31 | 蒂莫西 | 貝克 |
| 31 | 大衛 | 平克 |
| 31 | 馬修 | 雲頂 |
| 31 | 安娜 | 麥肯齊 |
| 31 | 瓊 | 科普林 |
| 31 | 拉姆納雷什 | 薩爾文 |
| 31 | 道格拉斯 | 瓊斯 |
| 31 | 亨利埃塔 | 拉姆尼 |
| 31 | 大衛 | 法雷爾 |
| 31 | 亨利 | Worthington-Smyth |
| 31 | 米里森 | 範圍 |
| 31 | 風信子 | 特百惠 |
| 31 | 約翰 | 打獵 |
| 31 | 埃里卡 | 碎屑 |
| 31 | 達倫 | 史密斯 |
回答:
select count ( * ) over(), firstname, surname
from cd . members
order by joindate 使用我們到目前為止所建立的知識,最明顯的答案是下面的。我們使用子查詢,因為否則SQL將要求我們以FirstName和姓氏進行分組,從而與我們想要的結果產生不同的結果。
select ( select count ( * ) from cd . members ) as count, firstname, surname
from cd . members
order by joindate這個答案完全沒有錯,但是我們選擇了另一種方法來介紹一個名為窗口函數的新概念。窗口功能提供了極大的功能,形式通常比標準聚合功能更方便。儘管此練習只是一個玩具,但我們將在不久的將來進行更複雜的示例。
窗口函數在您(子)查詢的結果集, WHERE子句和所有標準聚合之後的結果集操作。他們在數據窗口上操作。默認情況下,這是不受限制的:整個結果集,但可以限制以提供更有用的結果。例如,假設我們不需要所有成員的計數,而是希望與該成員同月加入的所有成員的計數:
select count ( * ) over(partition by date_trunc( ' month ' ,joindate)),
firstname, surname
from cd . members
order by joindate在此示例中,我們按月將數據分配。對於每行,窗口函數都可以運行,窗口是同一個月具有加入的任何行。因此,窗口功能會產生該月加入的成員數量的計數。
你可以走得更遠。想像一下,您是否想知道那個月加入的成員總數,而不是加入該月的成員。您可以通過將ORDER BY添加到窗口函數來做到這一點:
select count ( * ) over(partition by date_trunc( ' month ' ,joindate) order by joindate),
firstname, surname
from cd . members
order by joindate ORDER BY再次更改窗口。窗口從分區的開始到當前行,而不是超越,而不是讓每一行的窗口是整個分區的窗口。因此,對於第一個在給定月份加入的成員來說,計數為1。在第二個月份中,計數為2,依此類推。
關於窗口功能的最後一件事值得一提:您可以在同一查詢中具有多個無關的函數。嘗試以下查詢以示例 - 您將看到成員朝相反方向的數字! This flexibility can lead to more concise, readable, and maintainable queries.
select count ( * ) over(partition by date_trunc( ' month ' ,joindate) order by joindate asc ),
count ( * ) over(partition by date_trunc( ' month ' ,joindate) order by joindate desc ),
firstname, surname
from cd . members
order by joindateWindow functions are extraordinarily powerful, and they will change the way you write and think about SQL. Make good use of them!
Produce a monotonically increasing numbered list of members, ordered by their date of joining. Remember that member IDs are not guaranteed to be sequential.
預期結果:
| row_number | 名 | 姓 |
|---|---|---|
| 1 | 客人 | 客人 |
| 2 | 達倫 | 史密斯 |
| 3 | 特雷西 | 史密斯 |
| 4 | 蒂姆 | 羅恩南 |
| 5 | 珍妮絲 | 喬普特 |
| 6 | 杰拉爾德 | 奶油 |
| 7 | 伯頓 | 特雷西 |
| 8 | 南希 | 敢 |
| 9 | 蒂姆 | 展位 |
| 10 | 思考 | Stibbons |
| 11 | 查爾斯 | 歐文 |
| 12 | 大衛 | 瓊斯 |
| 13 | 安妮 | 貝克 |
| 14 | 傑米瑪 | 法雷爾 |
| 15 | 傑克 | 史密斯 |
| 16 | 佛羅倫斯 | 壞人 |
| 17 | 蒂莫西 | 貝克 |
| 18 | 大衛 | 平克 |
| 19 | 馬修 | 雲頂 |
| 20 | 安娜 | 麥肯齊 |
| 21 | 瓊 | 科普林 |
| 22 | 拉姆納雷什 | 薩爾文 |
| 23 | 道格拉斯 | 瓊斯 |
| 24 | 亨利埃塔 | 拉姆尼 |
| 25 | 大衛 | 法雷爾 |
| 26 | 亨利 | Worthington-Smyth |
| 27 | 米里森 | 範圍 |
| 28 | 風信子 | 特百惠 |
| 29 | 約翰 | 打獵 |
| 30 | 埃里卡 | 碎屑 |
| 31 | 達倫 | 史密斯 |
回答:
select row_number() over( order by joindate), firstname, surname
from cd . members
order by joindate This exercise is a simple bit of window function practise! You could just as easily use count(*) over(order by joindate) here, so don't worry if you used that instead.
In this query, we don't define a partition, meaning that the partition is the entire dataset. Since we define an order for the window function, for any given row the window is: start of the dataset -> current row.
Output the facility id that has the highest number of slots booked. Ensure that in the event of a tie, all tieing results get output.
預期結果:
| FACID | 全部的 |
|---|---|
| 4 | 1404 |
回答:
select facid, total from (
select facid, sum (slots) total, rank() over ( order by sum (slots) desc ) rank
from cd . bookings
group by facid
) as ranked
where rank = 1 You may recall that this is a problem we've already solved in an earlier exercise. We came up with an answer something like below, which we then cut down using CTEs:
select facid, sum (slots) as totalslots
from cd . bookings
group by facid
having sum (slots) = ( select max ( sum2 . totalslots ) from
( select sum (slots) as totalslots
from cd . bookings
group by facid
) as sum2);Once we've cleaned it up, this solution is perfectly adequate. Explaining how the query works makes it seem a little odd, though - 'find the number of slots booked by the best facility. Calculate the total slots booked for each facility, and return only the rows where the slots booked are the same as for the best'. Wouldn't it be nicer to be able to say 'calculate the number of slots booked for each facility, rank them, and pick out any at rank 1'?
Fortunately, window functions allow us to do this - although it's fair to say that doing so is not trivial to the untrained eye. The first key piece of information is the existence of the éfunction. This ranks values based on the ORDER BY that is passed to it. If there's a tie for (say) second place), the next gets ranked at position 4. So, what we need to do is get the number of slots for each facility, rank them, and pick off the ones at the top rank. A first pass at this might look something like the below:
select facid, total from (
select facid, total, rank() over ( order by total desc ) rank from (
select facid, sum (slots) total
from cd . bookings
group by facid
) as sumslots
) as ranked
where rank = 1 The inner query calculates the total slots booked, the middle one ranks them, and the outer one creams off the top ranked. We can actually tidy this up a little: recall that window function get applied pretty late in the select function, after aggregation. That being the case, we can move the aggregation into the ORDER BY part of the function, as shown in the approved answer.
While the window function approach isn't massively simpler in terms of lines of code, it arguably makes more semantic sense.
Produce a list of members, along with the number of hours they've booked in facilities, rounded to the nearest ten hours. Rank them by this rounded figure, producing output of first name, surname, rounded hours, rank. Sort by rank, surname, and first name.
預期結果:
| 名 | 姓 | 小時 | 秩 |
|---|---|---|---|
| 客人 | 客人 | 1200 | 1 |
| 達倫 | 史密斯 | 340 | 2 |
| 蒂姆 | 羅恩南 | 330 | 3 |
| 蒂姆 | 展位 | 220 | 4 |
| 特雷西 | 史密斯 | 220 | 4 |
| 杰拉爾德 | 奶油 | 210 | 6 |
| 伯頓 | 特雷西 | 180 | 7 |
| 查爾斯 | 歐文 | 170 | 8 |
| 珍妮絲 | 喬普特 | 160 | 9 |
| 安妮 | 貝克 | 150 | 10 |
| 蒂莫西 | 貝克 | 150 | 10 |
| 大衛 | 瓊斯 | 150 | 10 |
| 南希 | 敢 | 130 | 13 |
| 佛羅倫斯 | 壞人 | 120 | 14 |
| 安娜 | 麥肯齊 | 120 | 14 |
| 思考 | Stibbons | 120 | 14 |
| 傑克 | 史密斯 | 110 | 17 |
| 傑米瑪 | 法雷爾 | 90 | 18 |
| 大衛 | 平克 | 80 | 19 |
| 拉姆納雷什 | 薩爾文 | 80 | 19 |
| 馬修 | 雲頂 | 70 | 21 |
| 瓊 | 科普林 | 50 | 22 |
| 大衛 | 法雷爾 | 30 | 23 |
| 亨利 | Worthington-Smyth | 30 | 23 |
| 約翰 | 打獵 | 20 | 25 |
| 道格拉斯 | 瓊斯 | 20 | 25 |
| 米里森 | 範圍 | 20 | 25 |
| 亨利埃塔 | 拉姆尼 | 20 | 25 |
| 埃里卡 | 碎屑 | 10 | 29 |
| 風信子 | 特百惠 | 10 | 29 |
回答:
select firstname, surname,
(( sum ( bks . slots ) + 10 ) / 20 ) * 10 as hours,
rank() over ( order by (( sum ( bks . slots ) + 10 ) / 20 ) * 10 desc ) as rank
from cd . bookings bks
inner join cd . members mems
on bks . memid = mems . memid
group by mems . memid
order by rank, surname, firstname; This answer isn't a great stretch over our previous exercise, although it does illustrate the function of RANK better. You can see that some of the clubgoers have an equal rounded number of hours booked in, and their rank is the same. If position 2 is shared between two members, the next one along gets position 4. There's a different function, DENSE_RANK , that would assign that member position 3 instead.
It's worth noting the technique we use to do rounding here. Adding 5, dividing by 10, and multiplying by 10 has the effect (thanks to integer arithmetic cutting off fractions) of rounding a number to the nearest 10. In our case, because slots are half an hour, we need to add 10, divide by 20, and multiply by 10. One could certainly make the argument that we should do the slots -> hours conversion independently of the rounding, which would increase clarity.
Talking of clarity, this rounding malarky is starting to introduce a noticeable amount of code repetition. At this point it's a judgement call, but you may wish to factor it out using a subquery as below:
select firstname, surname, hours, rank() over ( order by hours desc ) from
( select firstname, surname,
(( sum ( bks . slots ) + 10 ) / 20 ) * 10 as hours
from cd . bookings bks
inner join cd . members mems
on bks . memid = mems . memid
group by mems . memid
) as subq
order by rank, surname, firstname;Produce a list of the top three revenue generating facilities (including ties). Output facility name and rank, sorted by rank and facility name.
預期結果:
| 姓名 | 秩 |
|---|---|
| 按摩室1 | 1 |
| 按摩室2 | 2 |
| 網球場2 | 3 |
回答:
select name, rank from (
select facs . name as name, rank() over ( order by sum (case
when memid = 0 then slots * facs . guestcost
else slots * membercost
end) desc ) as rank
from cd . bookings bks
inner join cd . facilities facs
on bks . facid = facs . facid
group by facs . name
) as subq
where rank <= 3
order by rank; This question doesn't introduce any new concepts, and is just intended to give you the opportunity to practise what you already know. We use the CASE statement to calculate the revenue for each slot, and aggregate that on a per-facility basis using SUM . We then use the RANK window function to produce a ranking, wrap it all up in a subquery, and extract everything with a rank less than or equal to 3.
Classify facilities into equally sized groups of high, average, and low based on their revenue. Order by classification and facility name.
預期結果:
| 姓名 | 收入 |
|---|---|
| 按摩室1 | 高的 |
| 按摩室2 | 高的 |
| 網球場2 | 高的 |
| 羽毛球法院 | 平均的 |
| 壁球場 | 平均的 |
| 網球場1 | 平均的 |
| 泳池表 | 低的 |
| Snooker表 | 低的 |
| 乒乓球 | 低的 |
回答:
select name, case when class = 1 then ' high '
when class = 2 then ' average '
else ' low '
end revenue
from (
select facs . name as name, ntile( 3 ) over ( order by sum (case
when memid = 0 then slots * facs . guestcost
else slots * membercost
end) desc ) as class
from cd . bookings bks
inner join cd . facilities facs
on bks . facid = facs . facid
group by facs . name
) as subq
order by class, name; This exercise should mostly use familiar concepts, although we do introduce the NTILE window function. NTILE groups values into a passed-in number of groups, as evenly as possible. It outputs a number from 1->number of groups. We then use a CASE statement to turn that number into a label!
Based on the 3 complete months of data so far, calculate the amount of time each facility will take to repay its cost of ownership. Remember to take into account ongoing monthly maintenance. Output facility name and payback time in months, order by facility name. Don't worry about differences in month lengths, we're only looking for a rough value here!
預期結果:
| 姓名 | 月份 |
|---|---|
| 羽毛球法院 | 6.8317677198975235 |
| 按摩室1 | 0.18885741265344664778 |
| 按摩室2 | 1.7621145374449339 |
| 泳池表 | 5.3333333333333333 |
| Snooker表 | 6.9230769230769231 |
| 壁球場 | 1.1339582703356516 |
| 乒乓球 | 6.4000000000000000 |
| 網球場1 | 2.2624434389140271 |
| 網球場2 | 1.7505470459518600 |
回答:
select facs . name as name,
facs . initialoutlay / (( sum (case
when memid = 0 then slots * facs . guestcost
else slots * membercost
end) / 3 ) - facs . monthlymaintenance ) as months
from cd . bookings bks
inner join cd . facilities facs
on bks . facid = facs . facid
group by facs . facid
order by name; In contrast to all our recent exercises, there's no need to use window functions to solve this problem: it's just a bit of maths involving monthly revenue, initial outlay, and monthly maintenance. Again, for production code you might want to clarify what's going on a little here using a subquery (although since we've hard-coded the number of months, putting this into production is unlikely!). A tidied-up version might look like:
select name,
initialoutlay / (monthlyrevenue - monthlymaintenance) as repaytime
from
( select facs . name as name,
facs . initialoutlay as initialoutlay,
facs . monthlymaintenance as monthlymaintenance,
sum (case
when memid = 0 then slots * facs . guestcost
else slots * membercost
end) / 3 as monthlyrevenue
from cd . bookings bks
inner join cd . facilities facs
on bks . facid = facs . facid
group by facs . facid
) as subq
order by name;But, I hear you ask, what would an automatic version of this look like? One that didn't need to have a hard-coded number of months in it? That's a little more complicated, and involves some date arithmetic. I've factored that out into a CTE to make it a little more clear.
with monthdata as (
select mincompletemonth,
maxcompletemonth,
(extract(year from maxcompletemonth) * 12 ) +
extract(month from maxcompletemonth) -
(extract(year from mincompletemonth) * 12 ) -
extract(month from mincompletemonth) as nummonths
from (
select date_trunc( ' month ' ,
( select max (starttime) from cd . bookings )) as maxcompletemonth,
date_trunc( ' month ' ,
( select min (starttime) from cd . bookings )) as mincompletemonth
) as subq
)
select name,
initialoutlay / (monthlyrevenue - monthlymaintenance) as repaytime
from
( select facs . name as name,
facs . initialoutlay as initialoutlay,
facs . monthlymaintenance as monthlymaintenance,
sum (case
when memid = 0 then slots * facs . guestcost
else slots * membercost
end) / ( select nummonths from monthdata) as monthlyrevenue
from cd . bookings bks
inner join cd . facilities facs
on bks . facid = facs . facid
where bks . starttime < ( select maxcompletemonth from monthdata)
group by facs . facid
) as subq
order by name;This code restricts the data that goes in to complete months. It does this by selecting the maximum date, rounding down to the month, and stripping out all dates larger than that. Even this code is not completely-complete. It doesn't handle the case of a facility making a loss. Fixing that is not too hard, and is left as (another) exercise for the reader!
For each day in August 2012, calculate a rolling average of total revenue over the previous 15 days. Output should contain date and revenue columns, sorted by the date. Remember to account for the possibility of a day having zero revenue. This one's a bit tough, so don't be afraid to check out the hint!
預期結果:
| 日期 | 收入 |
|---|---|
| 2012-08-01 | 1126.8333333333333333 |
| 2012-08-02 | 1153.0000000000000000 |
| 2012-08-03 | 1162.9000000000000000 |
| 2012-08-04 | 1177.3666666666666667 |
| 2012-08-05 | 1160.9333333333333333 |
| 2012-08-06 | 1185.4000000000000000 |
| 2012-08-07 | 1182.8666666666666667 |
| 2012-08-08 | 1172.6000000000000000 |
| 2012-08-09 | 1152.4666666666666667 |
| 2012-08-10 | 1175.0333333333333333 |
| 2012-08-11 | 1176.6333333333333333 |
| 2012-08-12 | 1195.6666666666666667 |
| 2012-08-13 | 1218.0000000000000000 |
| 2012-08-14 | 1247.4666666666666667 |
| 2012-08-15 | 1274.1000000000000000 |
| 2012-08-16 | 1281.2333333333333333 |
| 2012-08-17 | 1324.4666666666666667 |
| 2012-08-18 | 1373.7333333333333333 |
| 2012-08-19 | 1406.0666666666666667 |
| 2012-08-20 | 1427.0666666666666667 |
| 2012-08-21 | 1450.3333333333333333 |
| 2012-08-22 | 1539.7000000000000000 |
| 2012-08-23 | 1567.3000000000000000 |
| 2012-08-24 | 1592.3333333333333333 |
| 2012-08-25 | 1615.0333333333333333 |
| 2012-08-26 | 1631.2000000000000000 |
| 2012-08-27 | 1659.4333333333333333 |
| 2012-08-28 | 1687.0000000000000000 |
| 2012-08-29 | 1684.6333333333333333 |
| 2012-08-30 | 1657.9333333333333333 |
| 2012-08-31 | 1703.4000000000000000 |
回答:
select dategen . date ,
(
-- correlated subquery that, for each day fed into it,
-- finds the average revenue for the last 15 days
select sum (case
when memid = 0 then slots * facs . guestcost
else slots * membercost
end) as rev
from cd . bookings bks
inner join cd . facilities facs
on bks . facid = facs . facid
where bks . starttime > dategen . date - interval ' 14 days '
and bks . starttime < dategen . date + interval ' 1 day '
) / 15 as revenue
from
(
-- generates a list of days in august
select cast(generate_series( timestamp ' 2012-08-01 ' ,
' 2012-08-31 ' , ' 1 day ' ) as date ) as date
) as dategen
order by dategen . date ; There's at least two equally good solutions to this question. I've put the simplest to write as the answer, but there's also a more flexible solution that uses window functions.
Let's look at the selected answer first. When I read SQL queries, I tend to read the SELECT part of the statement last - the FROM and WHERE parts tend to be more interesting. So, what do we have in our FROM ? A call to the GENERATE_SERIES function. This does pretty much what it says on the tin - generates a series of values. You can specify a start value, a stop value, and an increment. It works for integer types and dates - although, as you can see, we need to be explicit about what types are going into and out of the function. Try removing the casts, and seeing the result!
So, we've generated a timestamp for each day in August. Now, for each day, we need to generate our average. We can do this using a correlated subquery . If you remember, a correlated subquery is a subquery that uses values from the outer query. This means that it gets executed once for each result row in the outer query. This is in contrast to an uncorrelated subquery, which only has to be executed once.
If we look at our correlated subquery, we can see that it's correlated on the dategen.date field. It produces a sum of revenue for this day and the 14 days prior to it, and then divides that sum by 15. This produces the output we're looking for!
I mentioned that there's a window function-based solution for this problem as well - you can see it below. The approach we use for this is generating a list of revenue for each day, and then using window function aggregation over that list. The nice thing about this method is that once you have the per-day revenue, you can produce a wide range of results quite easily - you might, for example, want rolling averages for the previous month, 15 days, and 5 days. This is easy to do using this method, and rather harder using conventional aggregation.
select date , avgrev from (
-- AVG over this row and the 14 rows before it.
select dategen . date as date ,
avg ( revdata . rev ) over( order by dategen . date rows 14 preceding) as avgrev
from
-- generate a list of days. This ensures that a row gets generated
-- even if the day has 0 revenue. Note that we generate days before
-- the start of october - this is because our window function needs
-- to know the revenue for those days for its calculations.
( select
cast(generate_series( timestamp ' 2012-07-10 ' , ' 2012-08-31 ' , ' 1 day ' ) as date ) as date
) as dategen
left outer join
-- left join to a table of per-day revenue
( select cast( bks . starttime as date ) as date ,
sum (case
when memid = 0 then slots * facs . guestcost
else slots * membercost
end) as rev
from cd . bookings bks
inner join cd . facilities facs
on bks . facid = facs . facid
group by cast( bks . starttime as date )
) as revdata
on dategen . date = revdata . date
) as subq
where date >= ' 2012-08-01 '
order by date ;You'll note that we've been wanting to work out daily revenue quite frequently. Rather than inserting that calculation into all our queries, which is rather messy (and will cause us a big headache if we ever change our schema), we probably want to store that information somewhere. Your first thought might be to calculate information and store it somewhere for later use. This is a common tactic for large data warehouses, but it can cause us some problems - if we ever go back and edit our data, we need to remember to recalculate. For non-enormous-scale data like we're looking at here, we can just create a view instead. A view is essentially a stored query that looks exactly like a table. Under the covers, the DBMS just subsititutes in the relevant portion of the view definition when you select data from it. They're very easy to create, as you can see below:
create or replace view cd .dailyrevenue as
select cast( bks . starttime as date ) as date ,
sum (case
when memid = 0 then slots * facs . guestcost
else slots * membercost
end) as rev
from cd . bookings bks
inner join cd . facilities facs
on bks . facid = facs . facid
group by cast( bks . starttime as date );You can see that this makes our query an awful lot simpler!
select date , avgrev from (
select dategen . date as date ,
avg ( revdata . rev ) over( order by dategen . date rows 14 preceding) as avgrev
from
( select
cast(generate_series( timestamp ' 2012-07-10 ' , ' 2012-08-31 ' , ' 1 day ' ) as date ) as date
) as dategen
left outer join
cd . dailyrevenue as revdata on dategen . date = revdata . date
) as subq
where date >= ' 2012-08-01 '
order by date ;As well as storing frequently-used query fragments, views can be used for a variety of purposes, including restricting access to certain columns of a table.
Dates/Times in SQL are a complex topic, deserving of a category of their own. They're also fantastically powerful, making it easier to work with variable-length concepts like 'months' than many programming languages.
Before getting started on this category, it's probably worth taking a look over the PostgreSQL docs page on date/time functions. You might also want to complete the aggregate functions category, since we'll use some of those capabilities in this section.
Produce a timestamp for 1 am on the 31st of August 2012.
預期結果:
| 時間戳 |
|---|
| 2012-08-31 01:00:00 |
回答:
select timestamp ' 2012-08-31 01:00:00 ' ; Here's a pretty easy question to start off with! SQL has a bunch of different date and time types, which you can peruse at your leisure over at the excellent Postgres documentation. These basically allow you to store dates, times, or timestamps (date+time).
The approved answer is the best way to create a timestamp under normal circumstances. You can also use casts to change a correctly formatted string into a timestamp, for example:
select ' 2012-08-31 01:00:00 ' :: timestamp ;
select cast( ' 2012-08-31 01:00:00 ' as timestamp );The former approach is a Postgres extension, while the latter is SQL-standard. You'll note that in many of our earlier questions, we've used bare strings without specifying a data type. This works because when Postgres is working with a value coming out of a timestamp column of a table (say), it knows to cast our strings to timestamps.
Timestamps can be stored with or without time zone information. We've chosen not to here, but if you like you could format the timestamp like "2012-08-31 01:00:00 +00:00", assuming UTC. Note that timestamp with time zone is a different type to timestamp - when you're declaring it, you should use TIMESTAMP WITH TIME ZONE 2012-08-31 01:00:00 +00:00.
Finally, have a bit of a play around with some of the different date/time serialisations described in the Postgres docs. You'll find that Postgres is extremely flexible with the formats it accepts, although my recommendation to you would be to use the standard serialisation we've used here - you'll find it unambiguous and easy to port to other DBs.
Find the result of subtracting the timestamp '2012-07-30 01:00:00' from the timestamp '2012-08-31 01:00:00'
預期結果:
| 間隔 |
|---|
| 32天 |
回答:
select timestamp ' 2012-08-31 01:00:00 ' - timestamp ' 2012-07-30 01:00:00 ' as interval; Subtracting timestamps produces an INTERVAL data type. INTERVAL s are a special data type for representing the difference between two TIMESTAMP types. When subtracting timestamps, Postgres will typically give an interval in terms of days, hours, minutes, seconds, without venturing into months. This generally makes life easier, since months are of variable lengths.
One of the useful things about intervals, though, is the fact that they can encode months. Let's imagine that I want to schedule something to occur in exactly one month's time, regardless of the length of my month. To do this, I could use [timestamp] + interval '1 month' .
Intervals stand in contrast to SQL's treatment of DATE types. Dates don't use intervals - instead, subtracting two dates will return an integer representing the number of days between the two dates. You can also add integer values to dates. This is sometimes more convenient, depending on how much intelligence you require in the handling of your dates!
Produce a list of all the dates in October 2012. They can be output as a timestamp (with time set to midnight) or a date.
預期結果:
| TS |
|---|
| 2012-10-01 00:00:00 |
| 2012-10-02 00:00:00 |
| 2012-10-03 00:00:00 |
| 2012-10-04 00:00:00 |
| 2012-10-05 00:00:00 |
| 2012-10-06 00:00:00 |
| 2012-10-07 00:00:00 |
| 2012-10-08 00:00:00 |
| 2012-10-09 00:00:00 |
| 2012-10-10 00:00:00 |
| 2012-10-11 00:00:00 |
| 2012-10-12 00:00:00 |
| 2012-10-13 00:00:00 |
| 2012-10-14 00:00:00 |
| 2012-10-15 00:00:00 |
| 2012-10-16 00:00:00 |
| 2012-10-17 00:00:00 |
| 2012-10-18 00:00:00 |
| 2012-10-19 00:00:00 |
| 2012-10-20 00:00:00 |
| 2012-10-21 00:00:00 |
| 2012-10-22 00:00:00 |
| 2012-10-23 00:00:00 |
| 2012-10-24 00:00:00 |
| 2012-10-25 00:00:00 |
| 2012-10-26 00:00:00 |
| 2012-10-27 00:00:00 |
| 2012-10-28 00:00:00 |
| 2012-10-29 00:00:00 |
| 2012-10-30 00:00:00 |
| 2012-10-31 00:00:00 |
回答:
select generate_series( timestamp ' 2012-10-01 ' , timestamp ' 2012-10-31 ' , interval ' 1 day ' ) as ts; One of the best features of Postgres over other DBs is a simple function called GENERATE_SERIES . This function allows you to generate a list of dates or numbers, specifying a start, an end, and an increment value. It's extremely useful for situations where you want to output, say, sales per day over the course of a month. A typical way to do that on a table containing a list of sales might be to use a SUM aggregation, grouping by the date and product type. Unfortunately, this approach has a flaw: if there are no sales for a given day, it won't show up! To make it work properly, you need to left join from a sequential list of timestamps to the aggregated data to fill in the blank spaces.
On other database systems, it's not uncommon to keep a 'calendar table' full of dates, with which you can perform these joins. Alternatively, on some systems you can write an analogue to generate_series using recursive CTEs. Fortunately for us, Postgres makes our lives a lot easier!
Get the day of the month from the timestamp '2012-08-31' as an integer.
預期結果:
| date_part |
|---|
| 31 |
回答:
select extract(day from timestamp ' 2012-08-31 ' ); The EXTRACT function is used for getting sections of a timestamp or interval. You can get the value of any field in the timestamp as an integer.
Work out the number of seconds between the timestamps '2012-08-31 01:00:00' and '2012-09-02 00:00:00'
預期結果:
| date_part |
|---|
| 169200 |
回答:
select extract(epoch from ( timestamp ' 2012-09-02 00:00:00 ' - ' 2012-08-31 01:00:00 ' )); The above answer is a Postgres-specific trick. Extracting the epoch converts an interval or timestamp into a number of seconds, or the number of seconds since epoch (January 1st, 1970) respectively. If you want the number of minutes, hours, etc you can just divide the number of seconds appropriately.
If you want to write more portable code, you will unfortunately find that you cannot use extract epoch . Instead you will need to use something like:
select extract(day from ts . int ) * 60 * 60 * 24 +
extract(hour from ts . int ) * 60 * 60 +
extract(minute from ts . int ) * 60 +
extract(second from ts . int )
from
( select timestamp ' 2012-09-02 00:00:00 ' - ' 2012-08-31 01:00:00 ' as int ) ts回答:
This is, as you can observe, rather awful. If you're planning to write cross platform SQL, I would consider having a library of common user defined functions for each DBMS, allowing you to normalise any common requirements like this. This keeps your main codebase a lot cleaner.
For each month of the year in 2012, output the number of days in that month. Format the output as an integer column containing the month of the year, and a second column containing an interval data type.
預期結果:
| 月 | 長度 |
|---|---|
| 1 | 31天 |
| 2 | 29 days |
| 3 | 31天 |
| 4 | 30天 |
| 5 | 31天 |
| 6 | 30天 |
| 7 | 31天 |
| 8 | 31天 |
| 9 | 30天 |
| 10 | 31天 |
| 11 | 30天 |
| 12 | 31天 |
回答:
select extract(month from cal . month ) as month,
( cal . month + interval ' 1 month ' ) - cal . month as length
from
(
select generate_series( timestamp ' 2012-01-01 ' , timestamp ' 2012-12-01 ' , interval ' 1 month ' ) as month
) cal
order by month; This answer shows several of the concepts we've learned. We use the GENERATE_SERIES function to produce a year's worth of timestamps, incrementing a month at a time. We then use the EXTRACT function to get the month number. Finally, we subtract each timestamp + 1 month from itself.
It's worth noting that subtracting two timestamps will always produce an interval in terms of days (or portions of a day). You won't just get an answer in terms of months or years, because the length of those time periods is variable.
For any given timestamp, work out the number of days remaining in the month. The current day should count as a whole day, regardless of the time. Use '2012-02-11 01:00:00' as an example timestamp for the purposes of making the answer. Format the output as a single interval value.
預期結果:
| 其餘的 |
|---|
| 19天 |
回答:
select (date_trunc( ' month ' , ts . testts ) + interval ' 1 month ' )
- date_trunc( ' day ' , ts . testts ) as remaining
from ( select timestamp ' 2012-02-11 01:00:00 ' as testts) ts The star of this particular show is the DATE_TRUNC function. It does pretty much what you'd expect - truncates a date to a given minute, hour, day, month, and so on. The way we've solved this problem is to truncate our timestamp to find the month we're in, add a month to that, and subtract our timestamp. To ensure partial days get treated as whole days, the timestamp we subtract is truncated to the nearest day.
Note the way we've put the timestamp into a subquery. This isn't required, but it does mean you can give the timestamp a name, rather than having to list the literal repeatedly.
Return a list of the start and end time of the last 10 bookings (ordered by the time at which they end, followed by the time at which they start) in the system.
預期結果:
| 開始時間 | 末日 |
|---|---|
| 2013-01-01 15:30:00 | 2013-01-01 16:00:00 |
| 2012-09-30 19:30:00 | 2012-09-30 20:30:00 |
| 2012-09-30 19:00:00 | 2012-09-30 20:30:00 |
| 2012-09-30 19:30:00 | 2012-09-30 20:00:00 |
| 2012-09-30 19:00:00 | 2012-09-30 20:00:00 |
| 2012-09-30 19:00:00 | 2012-09-30 20:00:00 |
| 2012-09-30 18:30:00 | 2012-09-30 20:00:00 |
| 2012-09-30 18:30:00 | 2012-09-30 20:00:00 |
| 2012-09-30 19:00:00 | 2012-09-30 19:30:00 |
| 2012-09-30 18:30:00 | 2012-09-30 19:30:00 |
回答:
select starttime, starttime + slots * (interval ' 30 minutes ' ) endtime
from cd . bookings
order by endtime desc , starttime desc
limit 10 This question simply returns the start time for a booking, and a calculated end time which is equal to start time + (30 minutes * slots) . Note that it's perfectly okay to multiply intervals.
The other thing you'll notice is the use of order by and limit to get the last ten bookings. All this does is order the bookings by the (descending) time at which they end, and pick off the top ten.
Return a count of bookings for each month, sorted by month
預期結果:
| 月 | 數數 |
|---|---|
| 2012-07-01 00:00:00 | 658 |
| 2012-08-01 00:00:00 | 1472 |
| 2012-09-01 00:00:00 | 1913年 |
| 2013-01-01 00:00:00 | 1 |
回答:
select date_trunc( ' month ' , starttime) as month, count ( * )
from cd . bookings
group by month
order by month This one is a fairly simple reuse of concepts we've seen before. We simply count the number of bookings, and aggregate by the booking's start time, truncated to the month.
Work out the utilisation percentage for each facility by month, sorted by name and month, rounded to 1 decimal place. Opening time is 8am, closing time is 8.30pm. You can treat every month as a full month, regardless of if there were some dates the club was not open.
預期結果:
| 姓名 | 月 | 利用率 |
|---|---|---|
| 羽毛球法院 | 2012-07-01 00:00:00 | 23.2 |
| 羽毛球法院 | 2012-08-01 00:00:00 | 59.2 |
| 羽毛球法院 | 2012-09-01 00:00:00 | 76.0 |
| 按摩室1 | 2012-07-01 00:00:00 | 34.1 |
| 按摩室1 | 2012-08-01 00:00:00 | 63.5 |
| 按摩室1 | 2012-09-01 00:00:00 | 86.4 |
| 按摩室2 | 2012-07-01 00:00:00 | 3.1 |
| 按摩室2 | 2012-08-01 00:00:00 | 10.6 |
| 按摩室2 | 2012-09-01 00:00:00 | 16.3 |
| 泳池表 | 2012-07-01 00:00:00 | 15.1 |
| 泳池表 | 2012-08-01 00:00:00 | 41.5 |
| 泳池表 | 2012-09-01 00:00:00 | 62.8 |
| 泳池表 | 2013-01-01 00:00:00 | 0.1 |
| Snooker表 | 2012-07-01 00:00:00 | 20.1 |
| Snooker表 | 2012-08-01 00:00:00 | 42.1 |
| Snooker表 | 2012-09-01 00:00:00 | 56.8 |
| 壁球場 | 2012-07-01 00:00:00 | 21.2 |
| 壁球場 | 2012-08-01 00:00:00 | 51.6 |
| 壁球場 | 2012-09-01 00:00:00 | 72.0 |
| 乒乓球 | 2012-07-01 00:00:00 | 13.4 |
| 乒乓球 | 2012-08-01 00:00:00 | 39.2 |
| 乒乓球 | 2012-09-01 00:00:00 | 56.3 |
| 網球場1 | 2012-07-01 00:00:00 | 34.8 |
| 網球場1 | 2012-08-01 00:00:00 | 59.2 |
| 網球場1 | 2012-09-01 00:00:00 | 78.8 |
| 網球場2 | 2012-07-01 00:00:00 | 26.7 |
| 網球場2 | 2012-08-01 00:00:00 | 62.3 |
| 網球場2 | 2012-09-01 00:00:00 | 78.4 |
回答:
select name, month,
round(( 100 * slots) /
cast(
25 * (cast((month + interval ' 1 month ' ) as date )
- cast (month as date )) as numeric ), 1 ) as utilisation
from (
select facs . name as name, date_trunc( ' month ' , starttime) as month, sum (slots) as slots
from cd . bookings bks
inner join cd . facilities facs
on bks . facid = facs . facid
group by facs . facid , month
) as inn
order by name, month The meat of this query (the inner subquery) is really quite simple: an aggregation to work out the total number of slots used per facility per month. If you've covered the rest of this section and the category on aggregates, you likely didn't find this bit too challenging.
This query does, unfortunately, have some other complexity in it: working out the number of days in each month. We can calculate the number of days between two months by subtracting two timestamps with a month between them. This, unfortunately, gives us back on interval datatype, which we can't use to do mathematics. In this case we've worked around that limitation by converting our timestamps into dates before subtracting. Subtracting date types gives us an integer number of days.
A alternative to this workaround is to convert the interval into an epoch value: that is, a number of seconds. To do this use EXTRACT(EPOCH FROM month)/(24*60*60) . This is arguably a much nicer way to do things, but is much less portable to other database systems.
String operations in most RDBMSs are, arguably, needlessly painful. Fortunately, Postgres is better than most in this regard, providing strong regular expression support. This section covers basic string manipulation, use of the LIKE operator, and use of regular expressions. I also make an effort to show you some alternative approaches that work reliably in most RDBMSs. Be sure to check out Postgres' string function docs page if you're not confident about these exercises.
Anthony Molinaro's SQL Cookbook provides some excellent documentation of (difficult) cross-DBMS compliant SQL string manipulation. I'd strongly recommend his book, particularly as it's published by O'Reilly, whose ethical policy of DRM-free ebook distribution deserves rich rewards.
Output the names of all members, formatted as 'Surname, Firstname'
預期結果:
| 姓名 |
|---|
| GUEST, GUEST |
| Smith, Darren |
| Smith, Tracy |
| Rownam, Tim |
| Joplette, Janice |
| Butters, Gerald |
| Tracy, Burton |
| Dare, Nancy |
| Boothe, Tim |
| Stibbons, Ponder |
| Owen, Charles |
| Jones, David |
| Baker, Anne |
| Farrell, Jemima |
| Smith, Jack |
| Bader, Florence |
| Baker, Timothy |
| Pinker, David |
| Genting, Matthew |
| Mackenzie, Anna |
| Coplin, Joan |
| Sarwin, Ramnaresh |
| Jones, Douglas |
| Rumney, Henrietta |
| Farrell, David |
| Worthington-Smyth, Henry |
| Purview, Millicent |
| Tupperware, Hyacinth |
| Hunt, John |
| Crumpet, Erica |
| Smith, Darren |
回答:
select surname || ' , ' || firstname as name from cd . members Building strings in sql is similar to other languages, with the exception of the concatenation operator: ||. Some systems (like SQL Server) use +, but || is the SQL standard.
Find all facilities whose name begins with 'Tennis'. Retrieve all columns.
預期結果:
| FACID | 姓名 | 成員代表 | 來賓代表 | 初始OUTOUTLAY | 每月保養 |
|---|---|---|---|---|---|
| 0 | 網球場1 | 5 | 25 | 10000 | 200 |
| 1 | 網球場2 | 5 | 25 | 8000 | 200 |
回答:
select * from cd . facilities where name like ' Tennis% ' ; The SQL LIKE operator is a highly standard way of searching for a string using basic matching. The % character matches any string, while _ matches any single character.
One point that's worth considering when you use LIKE is how it uses indexes. If you're using the 'C' locale, any LIKE string with a fixed beginning (as in our example here) can use an index. If you're using any other locale, LIKE will not use any index by default. See here for details on how to change that.
Perform a case-insensitive search to find all facilities whose name begins with 'tennis'. Retrieve all columns.
預期結果:
| FACID | 姓名 | 成員代表 | 來賓代表 | 初始OUTOUTLAY | 每月保養 |
|---|---|---|---|---|---|
| 0 | 網球場1 | 5 | 25 | 10000 | 200 |
| 1 | 網球場2 | 5 | 25 | 8000 | 200 |
回答:
select * from cd . facilities where upper (name) like ' TENNIS% ' ; There's no direct operator for case-insensitive comparison in standard SQL. Fortunately, we can take a page from many other language's books, and simply force all values into upper case when we do our comparison. This renders case irrelevant, and gives us our result.
Alternatively, Postgres does provide the ILIKE operator, which performs case insensitive searches. This isn't standard SQL, but it's arguably more clear.
You should realise that running a function like UPPER over a column value prevents Postgres from making use of any indexes on the column (the same is true for ILIKE ). Fortunately, Postgres has got your back: rather than simply creating indexes over columns, you can also create indexes over expressions. If you created an index over UPPER(name) , this query could use it quite happily.
You've noticed that the club's member table has telephone numbers with very inconsistent formatting. You'd like to find all the telephone numbers that contain parentheses, returning the member ID and telephone number sorted by member ID.
預期結果:
| 梅德 | 電話 |
|---|---|
| 0 | (000)000-0000 |
| 3 | (844) 693-0723 |
| 4 | (833) 942-4710 |
| 5 | (844) 078-4130 |
| 6 | (822) 354-9973 |
| 7 | (833) 776-4001 |
| 8 | (811) 433-2547 |
| 9 | (833) 160-3900 |
| 10 | (855) 542-5251 |
| 11 | (844) 536-8036 |
| 13 | (855) 016-0163 |
| 14 | (822) 163-3254 |
| 15 | (833) 499-3527 |
| 20 | (811) 972-1377 |
| 21 | (822) 661-2898 |
| 22 | (822) 499-2232 |
| 24 | (822) 413-1470 |
| 27 | (822) 989-8876 |
| 28 | (855) 755-9876 |
| 29 | (855) 894-3758 |
| 30 | (855) 941-9786 |
| 33 | (822) 665-5327 |
| 35 | (899) 720-6978 |
| 36 | (811) 732-4816 |
| 37 | (822) 577-3541 |
回答:
select memid, telephone from cd . members where telephone ~ ' [()] ' ; We've chosen to answer this using regular expressions, although Postgres does provide other string functions like POSITION that would do the job at least as well. Postgres implements POSIX regular expression matching via the ~ operator. If you've used regular expressions before, the functionality of the operator will be very familiar to you.
As an alternative, you can use the SQL standard SIMILAR TO operator. The regular expressions for this have similarities to the POSIX standard, but a lot of differences as well. Some of the most notable differences are:
LIKE operator, SIMILAR TO uses the '_' character to mean 'any character', and the '%' character to mean 'any string'.SIMILAR TO expression must match the whole string, not just a substring as in posix regular expressions. This means that you'll typically end up bracketing an expression in '%' characters.SIMILAR TO regexes: it's just a plain character. The SIMILAR TO equivalent of the given answer is shown below:
select memid, telephone from cd . members where telephone similar to ' %[()]% ' ;Finally, it's worth noting that regular expressions usually don't use indexes. Generally you don't want your regex to be responsible for doing heavy lifting in your query, because it will be slow. If you need fuzzy matching that works fast, consider working out if your needs can be met by full text search.
The zip codes in our example dataset have had leading zeroes removed from them by virtue of being stored as a numeric type. Retrieve all zip codes from the members table, padding any zip codes less than 5 characters long with leading zeroes. Order by the new zip code.
預期結果:
| 拉鍊 |
|---|
| 00000 |
| 00234 |
| 00234 |
| 04321 |
| 04321 |
| 10383 |
| 11986 |
| 23423 |
| 28563 |
| 33862 |
| 34232 |
| 43532 |
| 43533 |
| 45678 |
| 52365 |
| 54333 |
| 56754 |
| 57392 |
| 58393 |
| 64577 |
| 65332 |
| 65464 |
| 66796 |
| 68666 |
| 69302 |
| 75655 |
| 78533 |
| 80743 |
| 84923 |
| 87630 |
| 97676 |
回答:
select lpad(cast(zipcode as char ( 5 )), 5 , ' 0 ' ) zip from cd . members order by zip Postgres' LPAD function is the star of this particular show. It does basically what you'd expect: allow us to produce a padded string. We need to remember to cast the zipcode to a string for it to be accepted by the LPAD function.
When inheriting an old database, It's not that unusual to find wonky decisions having been made over data types. You may wish to fix mistakes like these, but have a lot of code that would break if you changed datatypes. In that case, one option (depending on performance requirements) is to create a view over your table which presents the data in a fixed-up manner, and gradually migrate.
You'd like to produce a count of how many members you have whose surname starts with each letter of the alphabet. Sort by the letter, and don't worry about printing out a letter if the count is 0.
預期結果:
| 信 | 數數 |
|---|---|
| b | 5 |
| c | 2 |
| d | 1 |
| f | 2 |
| g | 2 |
| h | 1 |
| j | 3 |
| m | 1 |
| o | 1 |
| p | 2 |
| r | 2 |
| s | 6 |
| t | 2 |
| w | 1 |
回答:
select substr ( mems . surname , 1 , 1 ) as letter, count ( * ) as count
from cd . members mems
group by letter
order by letter This exercise is fairly straightforward. You simply need to retrieve the first letter of the member's surname, and do some basic aggregation to achieve a count. We use the SUBSTR function here, but there's a variety of other ways you can achieve the same thing. The LEFT function, for example, returns you the first n characters from the left of the string. Alternatively, you could use the SUBSTRING function, which allows you to use regular expressions to extract a portion of the string.
One point worth noting: as you can see, string functions in SQL are based on 1-indexing, not the 0-indexing that you're probably used to. This will likely trip you up once or twice before you get used to it :-)
The telephone numbers in the database are very inconsistently formatted. You'd like to print a list of member ids and numbers that have had '-','(',')', and ' ' characters removed. Order by member id.
預期結果:
| 梅德 | 電話 |
|---|---|
| 0 | 0000000000 |
| 1 | 555555555 |
| 2 | 555555555 |
| 3 | 8446930723 |
| 4 | 8339424710 |
| 5 | 8440784130 |
| 6 | 8223549973 |
| 7 | 8337764001 |
| 8 | 8114332547 |
| 9 | 8331603900 |
| 10 | 8555425251 |
| 11 | 8445368036 |
| 12 | 8440765141 |
| 13 | 8550160163 |
| 14 | 8221633254 |
| 15 | 8334993527 |
| 16 | 8339410824 |
| 17 | 8114096734 |
| 20 | 8119721377 |
| 21 | 8226612898 |
| 22 | 8224992232 |
| 24 | 8224131470 |
| 26 | 8445368036 |
| 27 | 8229898876 |
| 28 | 8557559876 |
| 29 | 8558943758 |
| 30 | 8559419786 |
| 33 | 8226655327 |
| 35 | 8997206978 |
| 36 | 8117324816 |
| 37 | 8225773541 |
回答:
select memid, translate (telephone, ' -() ' , ' ' ) as telephone
from cd . members
order by memid; The most direct solution is probably the TRANSLATE function, which can be used to replace characters in a string. You pass it three strings: the value you want altered, the characters to replace, and the characters you want them replaced with. In our case, we want all the characters deleted, so our third parameter is an empty string.
As is often the way with strings, we can also use regular expressions to solve our problem. The REGEXP_REPLACE function provides what we're looking for: we simply pass a regex that matches all non-digit characters, and replace them with nothing, as shown below. The 'g' flag tells the function to replace as many instances of the pattern as it can find. This solution is perhaps more robust, as it cleans out more bad formatting.
select memid, regexp_replace(telephone, ' [^0-9] ' , ' ' , ' g ' ) as telephone
from cd . members
order by memid;Making automated use of free-formatted text data can be a chore. Ideally you want to avoid having to constantly write code to clean up the data before using it, so you should consider having your database enforce correct formatting for you. You can do this using a CHECK constraint on your column, which allow you to reject any poorly-formatted entry. It's tempting to perform this kind of validation in the application layer, and this is certainly a valid approach. As a general rule, if your database is getting used by multiple applications, favour pushing more of your checks down into the database to ensure consistent behaviour between the apps.
Occasionally, adding a constraint isn't feasible. You may, for example, have two different legacy applications asserting differently formatted information. If you're unable to alter the applications, you have a couple of options to consider. Firstly, you can define a trigger on your table. This allows you to intercept data before (or after) it gets asserted to your table, and normalise it into a single format. Alternatively, you could build a view over your table that cleans up information on the fly, as it's read out. Newer applications can read from the view and benefit from more reliably formatted information.
Common Table Expressions allow us to, effectively, create our own temporary tables for the duration of a query - they're largely a convenience to help us make more readable SQL. Using the WITH RECURSIVE modifier, however, it's possible for us to create recursive queries. This is enormously advantageous for working with tree and graph-structured data - imagine retrieving all of the relations of a graph node to a given depth, for example.
This category shows you some basic recursive queries that are possible using our dataset.
Find the upward recommendation chain for member ID 27: that is, the member who recommended them, and the member who recommended that member, and so on. Return member ID, first name, and surname. Order by descending member id.
預期結果:
| 推薦人 | 名 | 姓 |
|---|---|---|
| 20 | 馬修 | 雲頂 |
| 5 | 杰拉爾德 | 奶油 |
| 1 | 達倫 | 史密斯 |
回答:
with recursive recommenders(recommender) as (
select recommendedby from cd . members where memid = 27
union all
select mems . recommendedby
from recommenders recs
inner join cd . members mems
on mems . memid = recs . recommender
)
select recs . recommender , mems . firstname , mems . surname
from recommenders recs
inner join cd . members mems
on recs . recommender = mems . memid
order by memid desc WITH RECURSIVE is a fantastically useful piece of functionality that many developers are unaware of. It allows you to perform queries over hierarchies of data, which is very difficult by other means in SQL. Such scenarios often leave developers resorting to multiple round trips to the database system.
You've seen WITH before. The Common Table Expressions (CTEs) defined by WITH give you the ability to produce inline views over your data. This is normally just a syntactic convenience, but the RECURSIVE modifier adds the ability to join against results already produced to produce even more. A recursive WITH takes the basic form of:
WITH RECURSIVE NAME(columns) as (
< initial statement >
UNION ALL
< recursive statement >
)The initial statement populates the initial data, and then the recursive statement runs repeatedly to produce more. Each step of the recursion can access the CTE, but it sees within it only the data produced by the previous iteration. It repeats until an iteration produces no additional data.
The most simple example of a recursive WITH might look something like this:
with recursive increment(num) as (
select 1
union all
select increment . num + 1 from increment where increment . num < 5
)
select * from increment; The initial statement produces '1'. The first iteration of the recursive statement sees this as the content of increment , and produces '2'. The next iteration sees the content of increment as '2', and so on. Execution terminates when the recursive statement produces no additional data.
With the basics out of the way, it's fairly easy to explain our answer here. The initial statement gets the ID of the person who recommended the member we're interested in. The recursive statement takes the results of the initial statement, and finds the ID of the person who recommended them. This value gets forwarded on to the next iteration, and so on.
Now that we've constructed the recommenders CTE, all our main SELECT statement has to do is get the member IDs from recommenders, and join to them members table to find out their names.
Find the downward recommendation chain for member ID 1: that is, the members they recommended, the members those members recommended, and so on. Return member ID and name, and order by ascending member id.
預期結果:
| 梅德 | 名 | 姓 |
|---|---|---|
| 4 | 珍妮絲 | 喬普特 |
| 5 | 杰拉爾德 | 奶油 |
| 7 | 南希 | 敢 |
| 10 | 查爾斯 | 歐文 |
| 11 | 大衛 | 瓊斯 |
| 14 | 傑克 | 史密斯 |
| 20 | 馬修 | 雲頂 |
| 21 | 安娜 | 麥肯齊 |
| 26 | 道格拉斯 | 瓊斯 |
| 27 | 亨利埃塔 | 拉姆尼 |
回答:
with recursive recommendeds(memid) as (
select memid from cd . members where recommendedby = 1
union all
select mems . memid
from recommendeds recs
inner join cd . members mems
on mems . recommendedby = recs . memid
)
select recs . memid , mems . firstname , mems . surname
from recommendeds recs
inner join cd . members mems
on recs . memid = mems . memid
order by memid This is a pretty minor variation on the previous question. The essential difference is that we're now heading in the opposite direction. One interesting point to note is that unlike the previous example, this CTE produces multiple rows per iteration, by virtue of the fact that we're heading down the recommendation tree (following all branches) rather than up it.
Produce a CTE that can return the upward recommendation chain for any member. You should be able to select recommender from recommenders where member=x. Demonstrate it by getting the chains for members 12 and 22. Results table should have member and recommender, ordered by member ascending, recommender descending.
預期結果:
| 成員 | 推薦人 | 名 | 姓 |
|---|---|---|---|
| 12 | 9 | 思考 | Stibbons |
| 12 | 6 | 伯頓 | 特雷西 |
| 22 | 16 | 蒂莫西 | 貝克 |
| 22 | 13 | 傑米瑪 | 法雷爾 |
回答:
with recursive recommenders(recommender, member) as (
select recommendedby, memid
from cd . members
union all
select mems . recommendedby , recs . member
from recommenders recs
inner join cd . members mems
on mems . memid = recs . recommender
)
select recs . member member, recs . recommender , mems . firstname , mems . surname
from recommenders recs
inner join cd . members mems
on recs . recommender = mems . memid
where recs . member = 22 or recs . member = 12
order by recs . member asc , recs . recommender desc This question requires us to produce a CTE that can calculate the upward recommendation chain for any user. Most of the complexity of working out the answer is in realising that we now need our CTE to produce two columns: one to contain the member we're asking about, and another to contain the members in their recommendation tree. Essentially what we're doing is producing a table that flattens out the recommendation hierarchy.
Since we're looking to produce the chain for every user, our initial statement needs to select data for each user: their ID and who recommended them. Subsequently, we want to pass the member field through each iteration without changing it, while getting the next recommender. You can see that the recursive part of our statement hasn't really changed, except to pass through the 'member' field.


