transformers bloom inference
1.0.0
筆記
該存儲庫已被存檔,並且由於最近發布了像VLLM和TGI這樣的更高效的服務框架,因此沒有再維護。
該倉庫提供了演示和軟件包,以執行Bloom的快速推理解決方案。某些解決方案具有自己的存儲庫,在這種情況下,提供了指向相應存儲庫的鏈接。
我們支持擁抱面的加速和深速推斷。
安裝所需的軟件包:
pip install flask flask_api gunicorn pydantic accelerate huggingface_hub > =0.9.0 deepspeed > =0.7.3 deepspeed-mii==0.0.2另外,您也可以從源頭安裝DeepSpeed:
git clone https://github.com/microsoft/DeepSpeed
cd DeepSpeed
CFLAGS= " -I $CONDA_PREFIX /include/ " LDFLAGS= " -L $CONDA_PREFIX /lib/ " TORCH_CUDA_ARCH_LIST= " 7.0 " DS_BUILD_CPU_ADAM=1 DS_BUILD_AIO=1 DS_BUILD_UTILS=1 pip install -e . --global-option= " build_ext " --global-option= " -j8 " --no-cache -v --disable-pip-version-check所有提供的腳本均在8個A100 A100 80GB GPU上進行BLOOM 176B(FP16/BF16)和4 A100 80GB GPU,用於Bloom 176b(INT8)。這些腳本可能不適用於其他模型或不同數量的GPU。
DS推斷是使用從DeepSpeed MII庫借入的邏輯來部署的。
注意:有時DS推理部署崩潰時,有時GPU內存不會釋放。您可以通過在終端運行killall python來釋放此內存。
要使用Bloom量化,請使用dtype = int8。另外,將model_name更改為Microsoft/Bloom-Deepspeed-Int8,以進行深速推動。對於HF加速,model_name不需要更改。
HF加速使用llm.int8(),而DS-推斷使用零定量進行培訓量化。
這每次都要求generate_kwargs。示例:generate_kwargs =
{ "min_length" : 100 , "max_new_tokens" : 100 , "do_sample" : false }python -m inference_server.cli --model_name bigscience/bloom --model_class AutoModelForCausalLM --dtype bf16 --deployment_framework hf_accelerate --generate_kwargs ' {"min_length": 100, "max_new_tokens": 100, "do_sample": false} 'python -m inference_server.cli --model_name microsoft/bloom-deepspeed-inference-fp16 --model_class AutoModelForCausalLM --dtype fp16 --deployment_framework ds_inference --generate_kwargs ' {"min_length": 100, "max_new_tokens": 100, "do_sample": false} ' 製作<model_name>可用於啟動生成服務器。請注意,服務方法是同步的,用戶必須等待隊列,直到處理上述請求為止。這裡給出了一個fire服務器請求的示例。還提供了dockerfile的替代品,它在端口5000上啟動了一家發電服務器。
可以通過以下命令啟動交互式UI,以連接到Generation Server。 UI的默認URL為http://127.0.0.1:5001/ 。 UI僅使用model_name來檢查模型是解碼器還是編碼器模型。
python -m ui --model_name bigscience/bloom該命令啟動以下UI來播放一代。對不起,糟糕的設計。未來的是,我的UI技能只會走得太遠。 ??? 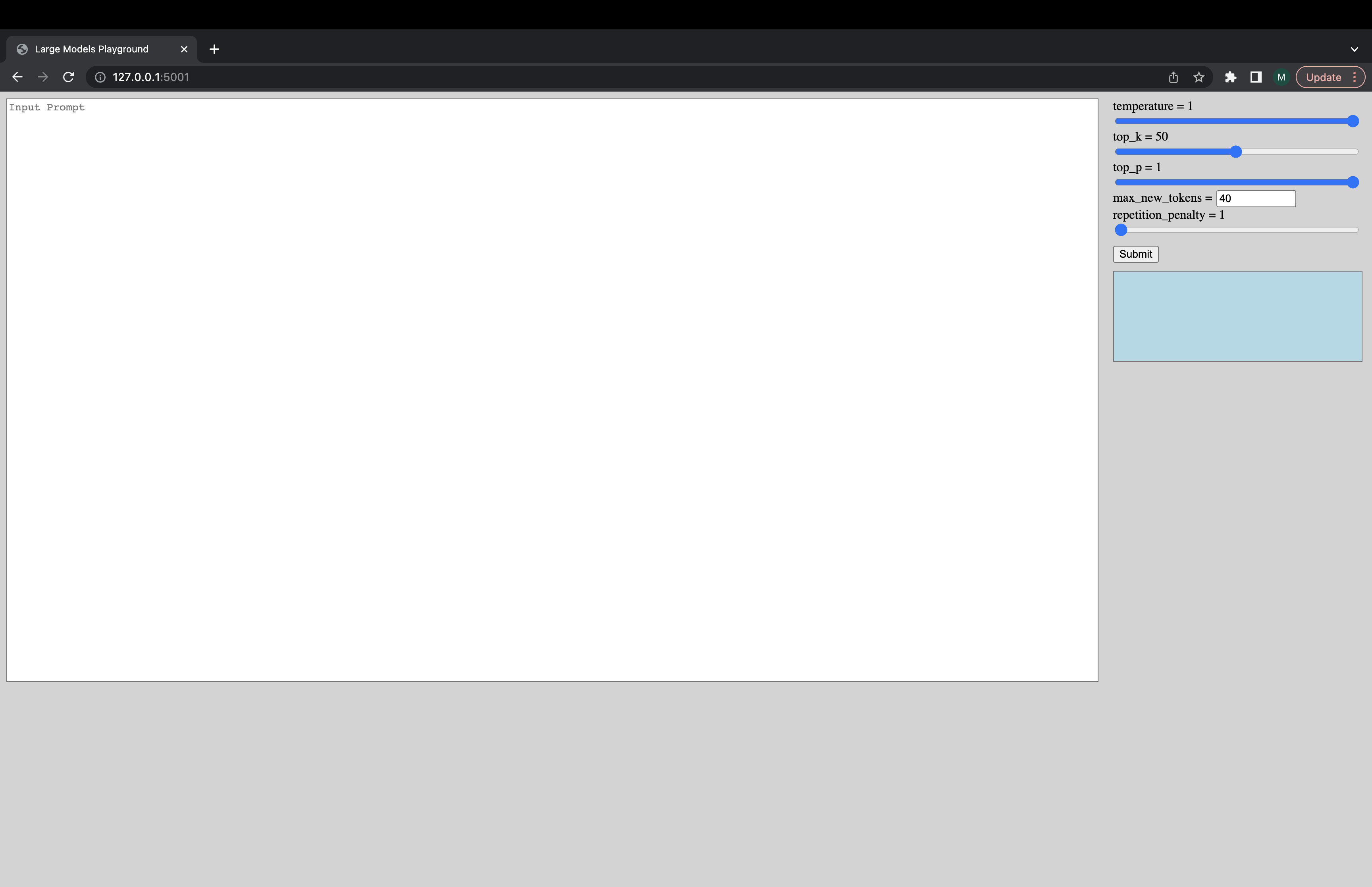
python -m inference_server.benchmark --model_name bigscience/bloom --model_class AutoModelForCausalLM --dtype bf16 --deployment_framework hf_accelerate --benchmark_cycles 5deepspeed --num_gpus 8 --module inference_server.benchmark --model_name bigscience/bloom --model_class AutoModelForCausalLM --dtype fp16 --deployment_framework ds_inference --benchmark_cycles 5或者,加載模型的速度更快:
deepspeed --num_gpus 8 --module inference_server.benchmark --model_name microsoft/bloom-deepspeed-inference-fp16 --model_class AutoModelForCausalLM --dtype fp16 --deployment_framework ds_inference --benchmark_cycles 5deepspeed --num_gpus 8 --module inference_server.benchmark --model_name bigscience/bloom --model_class AutoModelForCausalLM --dtype bf16 --deployment_framework ds_zero --benchmark_cycles 5如果您遇到不起作用或有其他問題的事情,請在相應的後端打開一個問題:
如果其中一個腳本存在特定問題,而不是後端,請在此處打開一個問題,並在 @Mayank31398上打開問題。
開發的解決方案是為了在本地執行大批推斷:
JAX:
可以在此處找到用於在服務器模式下使用的解決方案(即不同的批量大小,不同的請求率)。這是在生鏽中實現的。


