transformers bloom inference
1.0.0
บันทึก
พื้นที่เก็บข้อมูลนี้ได้รับการเก็บถาวรและไม่ได้รับการดูแลอีกต่อไปเนื่องจากกรอบการให้บริการที่มีประสิทธิภาพมากขึ้นได้รับการปล่อยตัวเมื่อเร็ว ๆ นี้เช่น VLLM และ TGI
repo นี้ให้การสาธิตและแพ็คเกจเพื่อดำเนินการแก้ปัญหาการอนุมานอย่างรวดเร็วสำหรับ Bloom โซลูชันบางอย่างมี repos ของตัวเองในกรณีนี้มีการเชื่อมโยงไปยัง repos ที่เกี่ยวข้องแทน
เรารองรับ HuggingFace เร่งความเร็วและการอนุมาน DEEPSPEED สำหรับรุ่น
ติดตั้งแพ็คเกจที่ต้องการ:
pip install flask flask_api gunicorn pydantic accelerate huggingface_hub > =0.9.0 deepspeed > =0.7.3 deepspeed-mii==0.0.2หรือคุณสามารถติดตั้ง Deepspeed จากแหล่งที่มา:
git clone https://github.com/microsoft/DeepSpeed
cd DeepSpeed
CFLAGS= " -I $CONDA_PREFIX /include/ " LDFLAGS= " -L $CONDA_PREFIX /lib/ " TORCH_CUDA_ARCH_LIST= " 7.0 " DS_BUILD_CPU_ADAM=1 DS_BUILD_AIO=1 DS_BUILD_UTILS=1 pip install -e . --global-option= " build_ext " --global-option= " -j8 " --no-cache -v --disable-pip-version-checkสคริปต์ที่ให้ไว้ทั้งหมดได้รับการทดสอบใน 8 A100 80GB GPU สำหรับ Bloom 176b (FP16/BF16) และ 4 A100 80GB GPU สำหรับ Bloom 176b (INT8) สคริปต์เหล่านี้อาจไม่ทำงานสำหรับรุ่นอื่นหรือ GPU จำนวนมาก
การอนุมาน DS ถูกปรับใช้โดยใช้ตรรกะที่ยืมมาจากห้องสมุด Deepspeed MII
หมายเหตุ: บางครั้งหน่วยความจำ GPU ไม่ได้เป็นอิสระเมื่อการปรับใช้การอนุมาน DS ล่ม คุณสามารถปลดปล่อยหน่วยความจำนี้ได้โดยใช้ killall python ในเทอร์มินัล
สำหรับการใช้ bloom quantized ให้ใช้ dtype = int8 นอกจากนี้เปลี่ยน model_name เป็น Microsoft/Bloom-Deepspeed-inference-int8 สำหรับการระบุ Deepspeed สำหรับการเร่งความเร็ว HF ไม่จำเป็นต้องมีการเปลี่ยนแปลงสำหรับ model_name
HF Accelerate ใช้ LLM.Int8 () และ DS-INFERIMENT ใช้ Zeroquant สำหรับการฝึกอบรมหลังการฝึกอบรม
สิ่งนี้ขอให้ Generate_kwargs ทุกครั้ง ตัวอย่าง: generate_kwargs =
{ "min_length" : 100 , "max_new_tokens" : 100 , "do_sample" : false }python -m inference_server.cli --model_name bigscience/bloom --model_class AutoModelForCausalLM --dtype bf16 --deployment_framework hf_accelerate --generate_kwargs ' {"min_length": 100, "max_new_tokens": 100, "do_sample": false} 'python -m inference_server.cli --model_name microsoft/bloom-deepspeed-inference-fp16 --model_class AutoModelForCausalLM --dtype fp16 --deployment_framework ds_inference --generate_kwargs ' {"min_length": 100, "max_new_tokens": 100, "do_sample": false} ' Make <Model_name> สามารถใช้เพื่อเปิดเซิร์ฟเวอร์ Generation โปรดทราบว่าวิธีการให้บริการเป็นแบบซิงโครนัสและผู้ใช้จะต้องรอคิวจนกว่าจะมีการประมวลผลคำขอก่อนหน้านี้ ตัวอย่างการร้องขอเซิร์ฟเวอร์ไฟจะได้รับที่นี่ นอกจากนี้ยังมีให้บริการ DockerFile ซึ่งเปิดตัวเซิร์ฟเวอร์รุ่นบนพอร์ต 5000
สามารถเรียกใช้ UI แบบโต้ตอบผ่านคำสั่งต่อไปนี้เพื่อเชื่อมต่อกับเซิร์ฟเวอร์ Generation URL เริ่มต้นของ UI คือ http://127.0.0.1:5001/ ui model_name เพิ่งใช้เพื่อตรวจสอบว่าโมเดลเป็นตัวถอดรหัสหรือโมเดลตัวเข้ารหัสหรือไม่
python -m ui --model_name bigscience/bloom คำสั่งนี้เรียกใช้ UI ต่อไปนี้เพื่อเล่นกับ Generation ขออภัยสำหรับการออกแบบเส็งเคร็ง อย่างไม่หยุดยั้งทักษะ UI ของฉันไปไกลแค่ไหน - 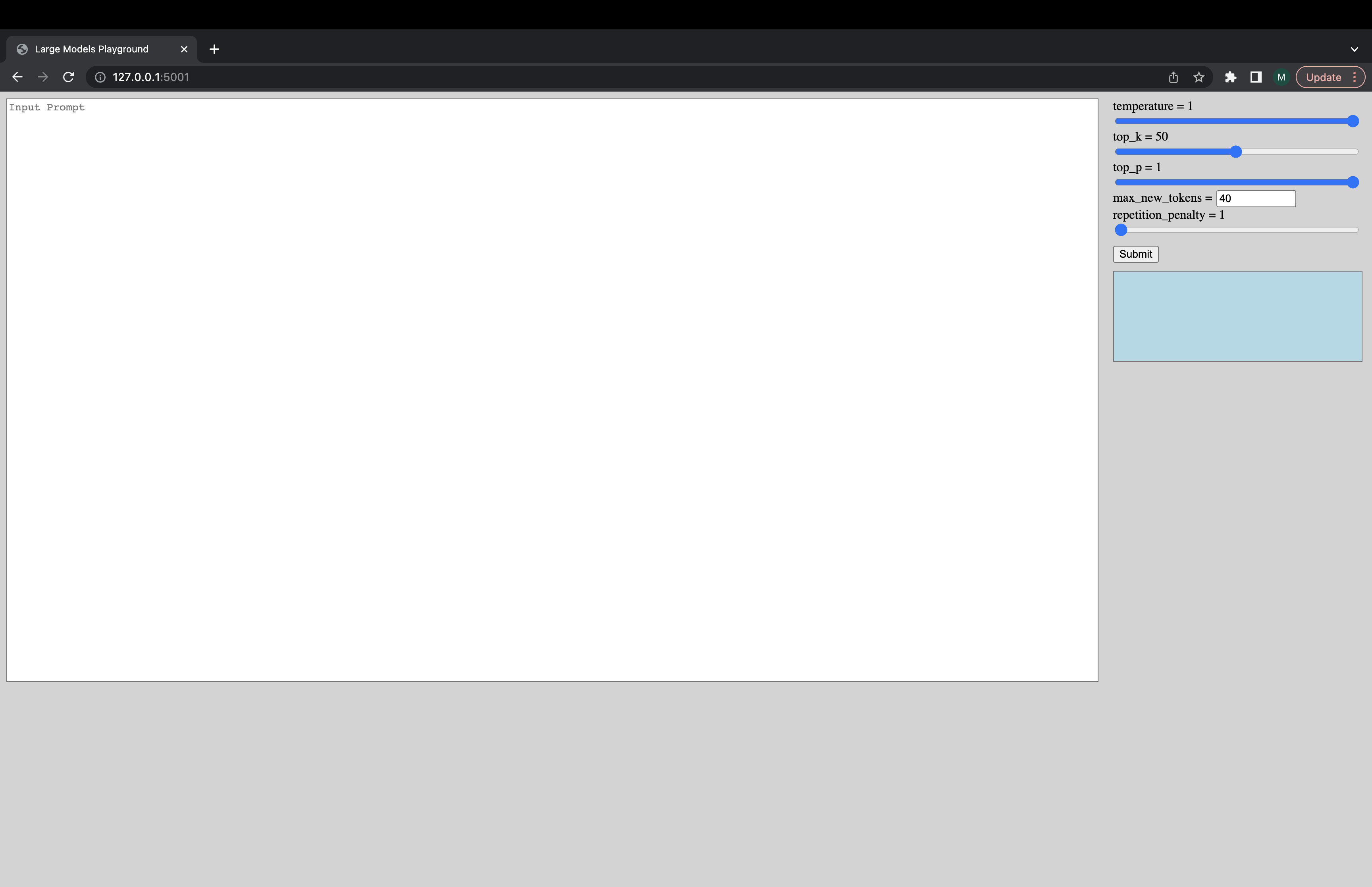
python -m inference_server.benchmark --model_name bigscience/bloom --model_class AutoModelForCausalLM --dtype bf16 --deployment_framework hf_accelerate --benchmark_cycles 5deepspeed --num_gpus 8 --module inference_server.benchmark --model_name bigscience/bloom --model_class AutoModelForCausalLM --dtype fp16 --deployment_framework ds_inference --benchmark_cycles 5อีกทางเลือกหนึ่งในการโหลดรุ่นเร็วขึ้น:
deepspeed --num_gpus 8 --module inference_server.benchmark --model_name microsoft/bloom-deepspeed-inference-fp16 --model_class AutoModelForCausalLM --dtype fp16 --deployment_framework ds_inference --benchmark_cycles 5deepspeed --num_gpus 8 --module inference_server.benchmark --model_name bigscience/bloom --model_class AutoModelForCausalLM --dtype bf16 --deployment_framework ds_zero --benchmark_cycles 5หากคุณพบสิ่งที่ไม่ทำงานหรือมีคำถามอื่น ๆ โปรดเปิดปัญหาในแบ็กเอนด์ที่เกี่ยวข้อง:
หากมีปัญหาเฉพาะกับหนึ่งในสคริปต์และไม่ใช่แบ็กเอนด์เท่านั้นโปรดเปิดปัญหาที่นี่และ tag @mayank31398
โซลูชั่นที่พัฒนาขึ้นเพื่อดำเนินการอนุมานเป็นชุดใหญ่ในพื้นที่:
JAX:
โซลูชันที่พัฒนาขึ้นเพื่อใช้ในโหมดเซิร์ฟเวอร์ (เช่นขนาดแบทช์ที่หลากหลายอัตราการร้องขอที่หลากหลาย) สามารถพบได้ที่นี่ สิ่งนี้ถูกนำไปใช้ใน Rust


