transformers bloom inference
1.0.0
Nota
Este repositorio ha sido archivado y ya no se mantiene ya que se han lanzado recientemente los marcos de servicio mucho más eficientes como VLLM y TGI.
Este repositorio proporciona demostraciones y paquetes para realizar soluciones de inferencia rápida para Bloom. Algunas de las soluciones tienen sus propios reposos en cuyo caso se proporciona un enlace a los reposadores correspondientes.
Apoyamos a Huggingface Acelerate e Infree de velocidad profunda para la generación.
Instalar paquetes requeridos:
pip install flask flask_api gunicorn pydantic accelerate huggingface_hub > =0.9.0 deepspeed > =0.7.3 deepspeed-mii==0.0.2Alternativamente, también puede instalar DeepSpeed desde la fuente:
git clone https://github.com/microsoft/DeepSpeed
cd DeepSpeed
CFLAGS= " -I $CONDA_PREFIX /include/ " LDFLAGS= " -L $CONDA_PREFIX /lib/ " TORCH_CUDA_ARCH_LIST= " 7.0 " DS_BUILD_CPU_ADAM=1 DS_BUILD_AIO=1 DS_BUILD_UTILS=1 pip install -e . --global-option= " build_ext " --global-option= " -j8 " --no-cache -v --disable-pip-version-checkTodos los scripts proporcionados se prueban en 8 GPU de 80GB A100 para Bloom 176B (FP16/BF16) y 4 GPU de 80GB A100 para Bloom 176b (INT8). Es posible que estos scripts no funcionen para otros modelos o un número diferente de GPU.
La inferencia de DS se implementa utilizando la lógica prestada de la biblioteca Deepspeed MII.
Nota: A veces la memoria de GPU no se libera cuando se bloquea la implementación de inferencia de DS. Puedes liberar esta memoria ejecutando killall python en Terminal.
Para usar Bloom Quantized, use dtype = int8. Además, cambie el Model_Name a Microsoft/Bloom-Deepeed-Inference-INT8 para la Inferencia de Speed de Deepeed. Para HF acelerar, no se necesita ningún cambio para model_name.
HF Accelerate usa LLM.Int8 () y DS-Inference usa Zeroquant para la cuantización posterior al entrenamiento.
Esto solicita generar_kwargs cada vez. Ejemplo: generar_kwargs =
{ "min_length" : 100 , "max_new_tokens" : 100 , "do_sample" : false }python -m inference_server.cli --model_name bigscience/bloom --model_class AutoModelForCausalLM --dtype bf16 --deployment_framework hf_accelerate --generate_kwargs ' {"min_length": 100, "max_new_tokens": 100, "do_sample": false} 'python -m inference_server.cli --model_name microsoft/bloom-deepspeed-inference-fp16 --model_class AutoModelForCausalLM --dtype fp16 --deployment_framework ds_inference --generate_kwargs ' {"min_length": 100, "max_new_tokens": 100, "do_sample": false} ' Make <Model_Name> se puede usar para iniciar un servidor de generación. Tenga en cuenta que el método de servicio es sincrónico y los usuarios deben esperar en la cola hasta que se hayan procesado las solicitudes anteriores. Aquí se da un ejemplo de solicitudes de servidor contra incendios. Alternativey, también se proporciona un DockerFile que inicia un servidor de generación en el puerto 5000.
Se puede iniciar una interfaz de usuario interactiva a través del siguiente comando para conectarse al servidor de generación. La URL predeterminada de la UI es http://127.0.0.1:5001/ . La UI acaba de utilizar el model_name para verificar si el modelo es el modelo de decodificador o codificador del codificador.
python -m ui --model_name bigscience/bloom Este comando inicia la siguiente interfaz de usuario para jugar con la generación. Perdón por el diseño de mierda. Desafortunadamente, mis habilidades de UI solo llegan tan lejos. ???? 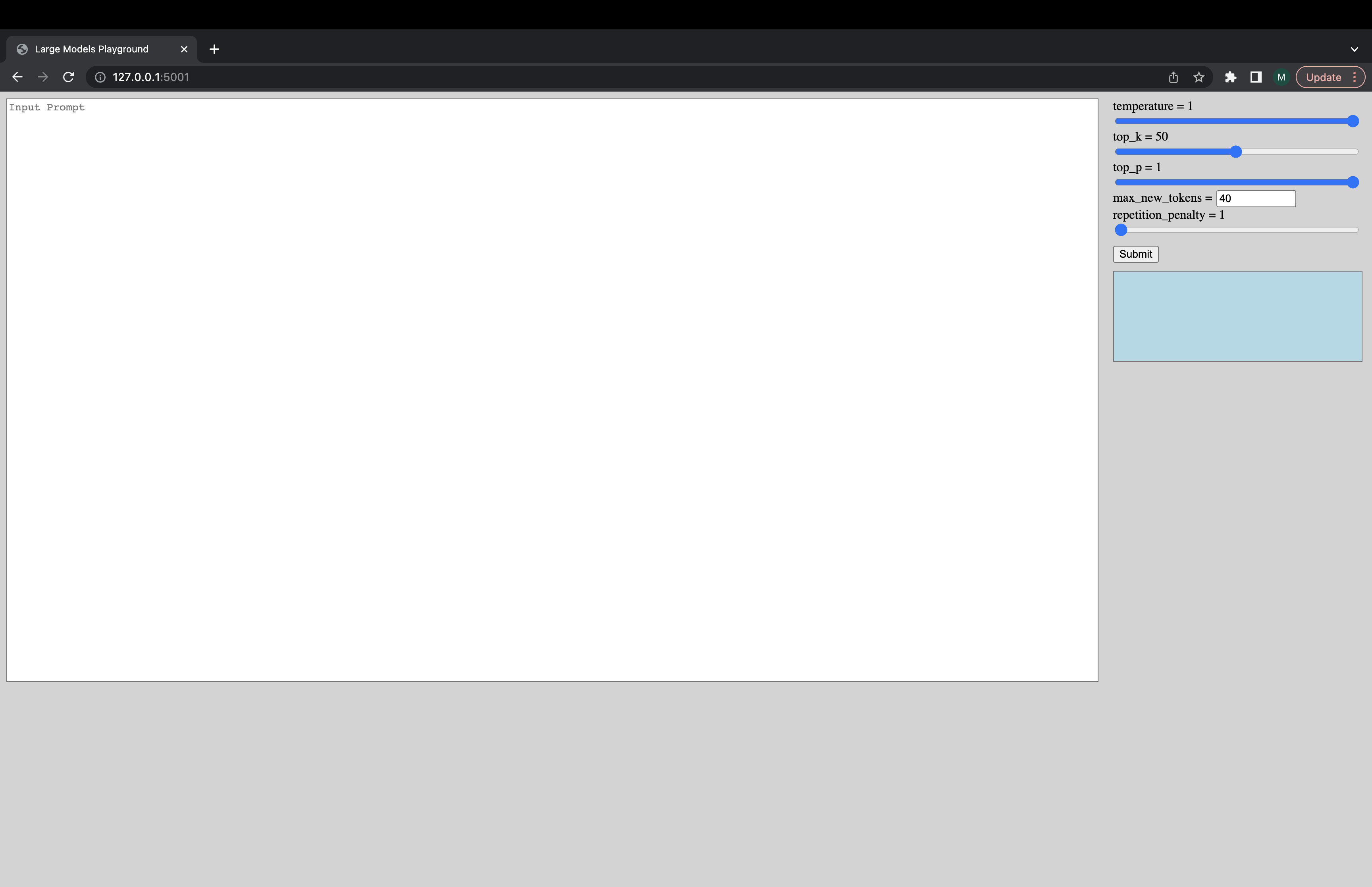
python -m inference_server.benchmark --model_name bigscience/bloom --model_class AutoModelForCausalLM --dtype bf16 --deployment_framework hf_accelerate --benchmark_cycles 5deepspeed --num_gpus 8 --module inference_server.benchmark --model_name bigscience/bloom --model_class AutoModelForCausalLM --dtype fp16 --deployment_framework ds_inference --benchmark_cycles 5Alternativamente, para cargar el modelo más rápido:
deepspeed --num_gpus 8 --module inference_server.benchmark --model_name microsoft/bloom-deepspeed-inference-fp16 --model_class AutoModelForCausalLM --dtype fp16 --deployment_framework ds_inference --benchmark_cycles 5deepspeed --num_gpus 8 --module inference_server.benchmark --model_name bigscience/bloom --model_class AutoModelForCausalLM --dtype bf16 --deployment_framework ds_zero --benchmark_cycles 5Si se encuentra con cosas que no funcionan o tiene otras preguntas, abra un problema en el backend correspondiente:
Si hay un problema específico con uno de los scripts y no el backend solo, abra un problema aquí y etiquete @Mayank31398.
Soluciones desarrolladas para realizar una gran inferencia de lotes localmente:
Jax:
Aquí se puede encontrar una solución desarrollada para usarse en un modo de servidor (es decir, un tamaño de lote variado, tasa de solicitud variada). Esto se implementa en Rust.


