transformers bloom inference
1.0.0
Note
Ce référentiel a été archivé et n'est plus maintenu, car de nombreux cadres de service plus efficaces ont été publiés récemment comme VLLM et TGI.
Ce repo fournit des démos et des packages pour effectuer des solutions d'inférence rapides pour Bloom. Certaines des solutions ont leurs propres référentiels, auquel cas un lien avec les référentiels correspondants est fourni à la place.
Nous prenons en charge les huggingface accélérer et l'inférence profonde pour la génération.
Installer les packages requis:
pip install flask flask_api gunicorn pydantic accelerate huggingface_hub > =0.9.0 deepspeed > =0.7.3 deepspeed-mii==0.0.2Vous pouvez également installer Deeppeed à partir de la source:
git clone https://github.com/microsoft/DeepSpeed
cd DeepSpeed
CFLAGS= " -I $CONDA_PREFIX /include/ " LDFLAGS= " -L $CONDA_PREFIX /lib/ " TORCH_CUDA_ARCH_LIST= " 7.0 " DS_BUILD_CPU_ADAM=1 DS_BUILD_AIO=1 DS_BUILD_UTILS=1 pip install -e . --global-option= " build_ext " --global-option= " -j8 " --no-cache -v --disable-pip-version-checkTous les scripts fournis sont testés sur 8 GPU A100 80 Go pour Bloom 176B (FP16 / BF16) et 4 GPU A100 80 Go pour Bloom 176B (INT8). Ces scripts peuvent ne pas fonctionner pour d'autres modèles ou un nombre différent de GPU.
L'inférence DS est déployée à l'aide de la logique empruntée à Deeppeed Mii Library.
Remarque: Parfois, la mémoire GPU n'est pas libérée lorsque le déploiement de l'inférence DS se bloque. Vous pouvez libérer cette mémoire en exécutant killall python dans le terminal.
Pour utiliser Bloom quantifié, utilisez dtype = int8. En outre, modifiez le Model_name en Microsoft / Bloom-Deeppeed-Inference-Int8 pour Deeppeed-Inference. Pour HF Accelerate, aucun changement n'est nécessaire pour Model_name.
HF Accelerate utilise llm.int8 () et DS-Inference utilise le zéro pour la quantification post-formation.
Cela demande à générer_kwargs à chaque fois. Exemple: generate_kwargs =
{ "min_length" : 100 , "max_new_tokens" : 100 , "do_sample" : false }python -m inference_server.cli --model_name bigscience/bloom --model_class AutoModelForCausalLM --dtype bf16 --deployment_framework hf_accelerate --generate_kwargs ' {"min_length": 100, "max_new_tokens": 100, "do_sample": false} 'python -m inference_server.cli --model_name microsoft/bloom-deepspeed-inference-fp16 --model_class AutoModelForCausalLM --dtype fp16 --deployment_framework ds_inference --generate_kwargs ' {"min_length": 100, "max_new_tokens": 100, "do_sample": false} ' Make <Model_name> peut être utilisé pour lancer un serveur de génération. Veuillez noter que la méthode de service est synchrone et que les utilisateurs doivent attendre dans la file d'attente jusqu'à ce que les demandes précédentes aient été traitées. Un exemple pour incendier des demandes de serveur est donné ici. Alternativey, un dockerfile est également fourni qui lance un serveur de génération sur le port 5000.
Une interface utilisateur interactive peut être lancée via la commande suivante pour se connecter au serveur de génération. L'URL par défaut de l'interface utilisateur est http://127.0.0.1:5001/ . Le model_name est juste utilisé par l'interface utilisateur pour vérifier si le modèle est un modèle de décodeur ou d'encodeur.
python -m ui --model_name bigscience/bloom Cette commande lance l'interface utilisateur suivante pour jouer avec la génération. Désolé pour le design merdique. Indépendamment, mes compétences d'interface utilisateur ne vont que si loin. ??? 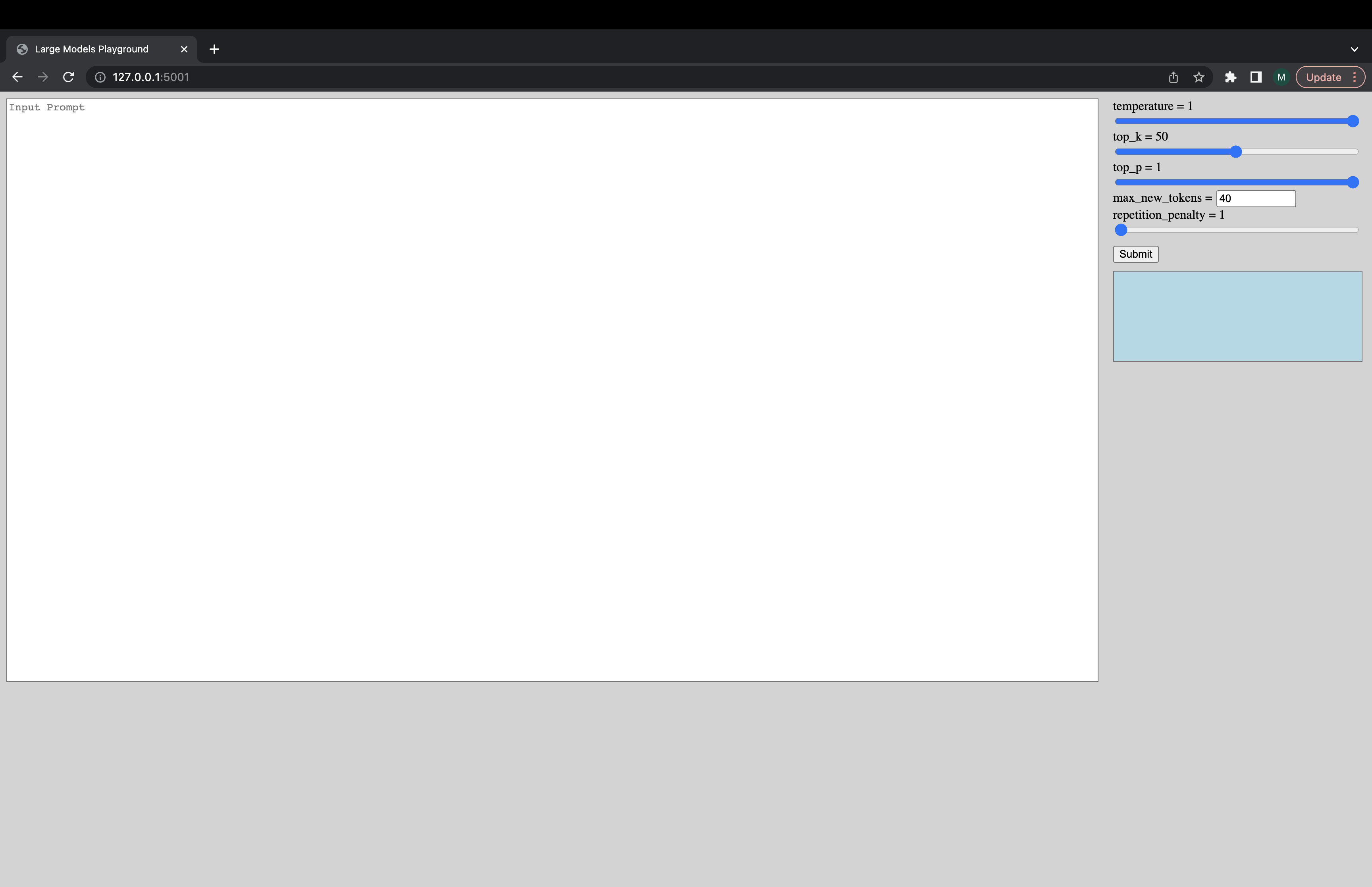
python -m inference_server.benchmark --model_name bigscience/bloom --model_class AutoModelForCausalLM --dtype bf16 --deployment_framework hf_accelerate --benchmark_cycles 5deepspeed --num_gpus 8 --module inference_server.benchmark --model_name bigscience/bloom --model_class AutoModelForCausalLM --dtype fp16 --deployment_framework ds_inference --benchmark_cycles 5Alternativement, pour charger le modèle plus rapidement:
deepspeed --num_gpus 8 --module inference_server.benchmark --model_name microsoft/bloom-deepspeed-inference-fp16 --model_class AutoModelForCausalLM --dtype fp16 --deployment_framework ds_inference --benchmark_cycles 5deepspeed --num_gpus 8 --module inference_server.benchmark --model_name bigscience/bloom --model_class AutoModelForCausalLM --dtype bf16 --deployment_framework ds_zero --benchmark_cycles 5Si vous rencontrez des choses qui ne fonctionnent pas ou si vous avez d'autres questions, veuillez ouvrir un problème dans le backend correspondant:
S'il y a un problème spécifique avec l'un des scripts et non le backend seulement, veuillez ouvrir un problème ici et tag @ Mayank31398.
Solutions développées pour effectuer une grande inférence par lots localement:
Jax:
Une solution développée pour être utilisée en mode serveur (c'est-à-dire la taille variée du lot, le taux de demande varié) peut être trouvé ici. Ceci est mis en œuvre en rouille.


