transformers bloom inference
1.0.0
Catatan
Repositori ini telah diarsipkan dan tidak dipertahankan lagi karena kerangka kerja melayani yang jauh lebih efisien telah dirilis baru -baru ini seperti VLLM dan TGI.
Repo ini menyediakan demo dan paket untuk melakukan solusi inferensi cepat untuk Bloom. Beberapa solusi memiliki repo sendiri dalam hal ini tautan ke repo yang sesuai disediakan sebagai gantinya.
Kami mendukung huggingface mempercepat dan kesimpulan dalam kecepatan untuk generasi.
Instal Paket yang Diperlukan:
pip install flask flask_api gunicorn pydantic accelerate huggingface_hub > =0.9.0 deepspeed > =0.7.3 deepspeed-mii==0.0.2Atau Anda juga dapat menginstal DeepSece dari Sumber:
git clone https://github.com/microsoft/DeepSpeed
cd DeepSpeed
CFLAGS= " -I $CONDA_PREFIX /include/ " LDFLAGS= " -L $CONDA_PREFIX /lib/ " TORCH_CUDA_ARCH_LIST= " 7.0 " DS_BUILD_CPU_ADAM=1 DS_BUILD_AIO=1 DS_BUILD_UTILS=1 pip install -e . --global-option= " build_ext " --global-option= " -j8 " --no-cache -v --disable-pip-version-checkSemua skrip yang disediakan diuji pada 8 A100 80GB GPU untuk Bloom 176B (FP16/BF16) dan 4 A100 80GB GPU untuk Bloom 176B (Int8). Script ini mungkin tidak berfungsi untuk model lain atau jumlah GPU yang berbeda.
Inferensi DS digunakan menggunakan logika yang dipinjam dari perpustakaan MII yang lebih dalam.
Catatan: Terkadang memori GPU tidak dibebaskan ketika penyebaran inferensi DS macet. Anda dapat membebaskan memori ini dengan menjalankan killall python di Terminal.
Untuk menggunakan Bloom Cuantized, gunakan dtype = int8. Juga, ubah model_name menjadi Microsoft/Bloom-Deep-Inference-Int8 untuk Deep-Inference. Untuk HF Accelerate, tidak ada perubahan yang diperlukan untuk model_name.
HF Accelerate menggunakan LLM.Int8 () dan DS-Inference menggunakan Zeroquant untuk kuantisasi pasca-pelatihan.
Ini meminta untuk generate_kwargs setiap kali. Contoh: Generate_Kwargs =
{ "min_length" : 100 , "max_new_tokens" : 100 , "do_sample" : false }python -m inference_server.cli --model_name bigscience/bloom --model_class AutoModelForCausalLM --dtype bf16 --deployment_framework hf_accelerate --generate_kwargs ' {"min_length": 100, "max_new_tokens": 100, "do_sample": false} 'python -m inference_server.cli --model_name microsoft/bloom-deepspeed-inference-fp16 --model_class AutoModelForCausalLM --dtype fp16 --deployment_framework ds_inference --generate_kwargs ' {"min_length": 100, "max_new_tokens": 100, "do_sample": false} ' buat <lodel_name> dapat digunakan untuk meluncurkan server generasi. Harap dicatat bahwa metode penyajian itu sinkron dan pengguna harus menunggu dalam antrian sampai permintaan sebelumnya telah diproses. Contoh permintaan server pemecatan diberikan di sini. Alternatif, DockerFile juga disediakan yang meluncurkan server generasi di port 5000.
UI interaktif dapat diluncurkan melalui perintah berikut untuk terhubung ke server generasi. URL default UI adalah http://127.0.0.1:5001/ . model_name hanya digunakan oleh UI untuk memeriksa apakah modelnya adalah model decoder atau encoder-decoder.
python -m ui --model_name bigscience/bloom Perintah ini meluncurkan UI berikut untuk bermain dengan generasi. Maaf untuk desain jeleknya. Untungnya, keterampilan UI saya hanya sejauh ini. ??? 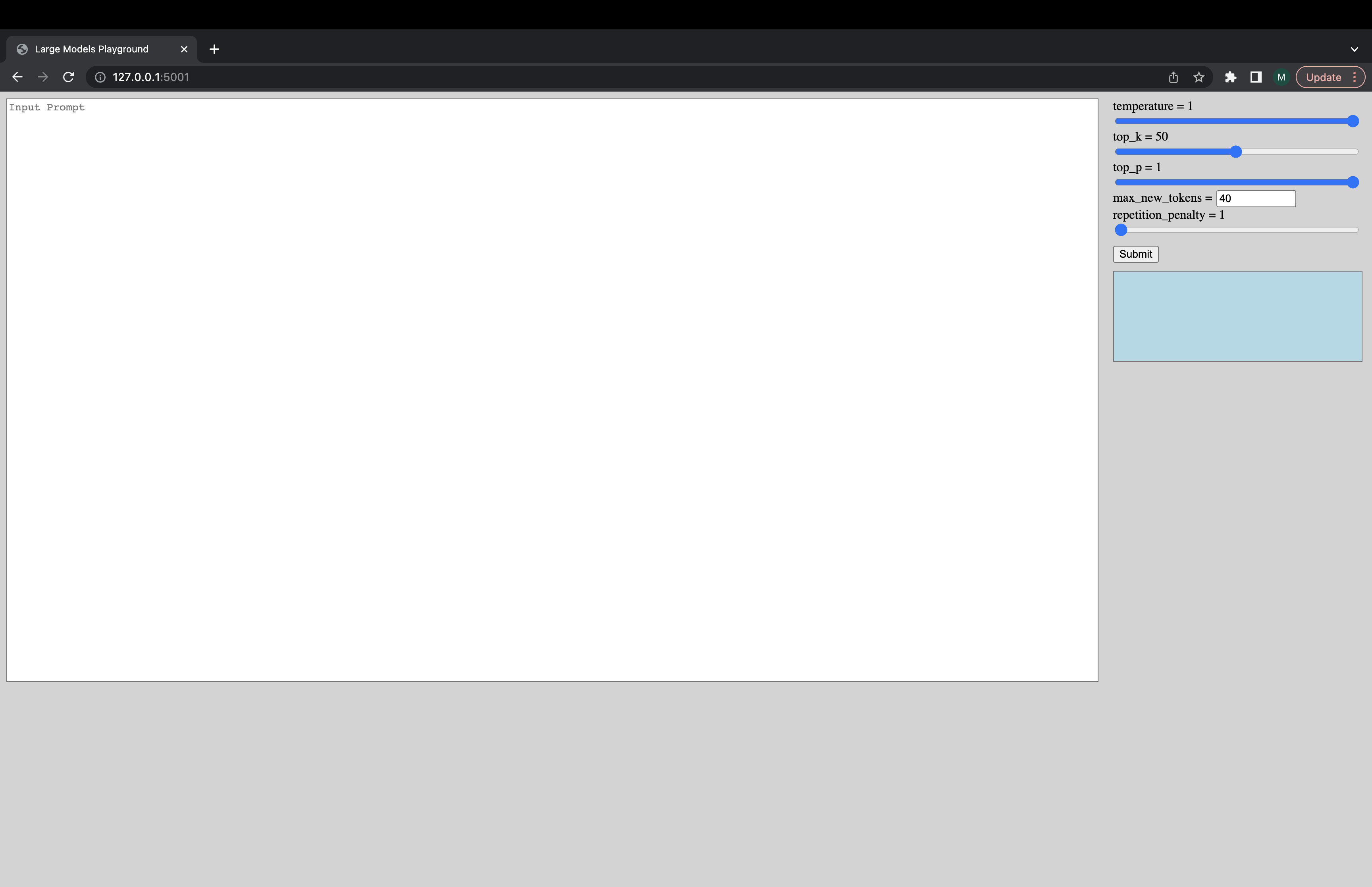
python -m inference_server.benchmark --model_name bigscience/bloom --model_class AutoModelForCausalLM --dtype bf16 --deployment_framework hf_accelerate --benchmark_cycles 5deepspeed --num_gpus 8 --module inference_server.benchmark --model_name bigscience/bloom --model_class AutoModelForCausalLM --dtype fp16 --deployment_framework ds_inference --benchmark_cycles 5Atau, untuk memuat model lebih cepat:
deepspeed --num_gpus 8 --module inference_server.benchmark --model_name microsoft/bloom-deepspeed-inference-fp16 --model_class AutoModelForCausalLM --dtype fp16 --deployment_framework ds_inference --benchmark_cycles 5deepspeed --num_gpus 8 --module inference_server.benchmark --model_name bigscience/bloom --model_class AutoModelForCausalLM --dtype bf16 --deployment_framework ds_zero --benchmark_cycles 5Jika Anda mengalami hal -hal yang tidak berfungsi atau memiliki pertanyaan lain, buka masalah di backend yang sesuai:
Jika ada masalah khusus dengan salah satu skrip dan bukan backend saja maka buka masalah di sini dan tag @mayank31398.
Solusi yang dikembangkan untuk melakukan inferensi batch besar secara lokal:
Jax:
Solusi yang dikembangkan untuk digunakan dalam mode server (yaitu ukuran batch yang bervariasi, tingkat permintaan yang bervariasi) dapat ditemukan di sini. Ini diimplementasikan dalam karat.


