open genie
1.0.0
該回購包含精靈的非正式實施:生成的互動環境Bruce等。 (2024)Google DeepMind介紹。
該模型的目的是引入“ [...]以無標記的互聯網視頻無監督方式訓練的第一個生成互動環境”。
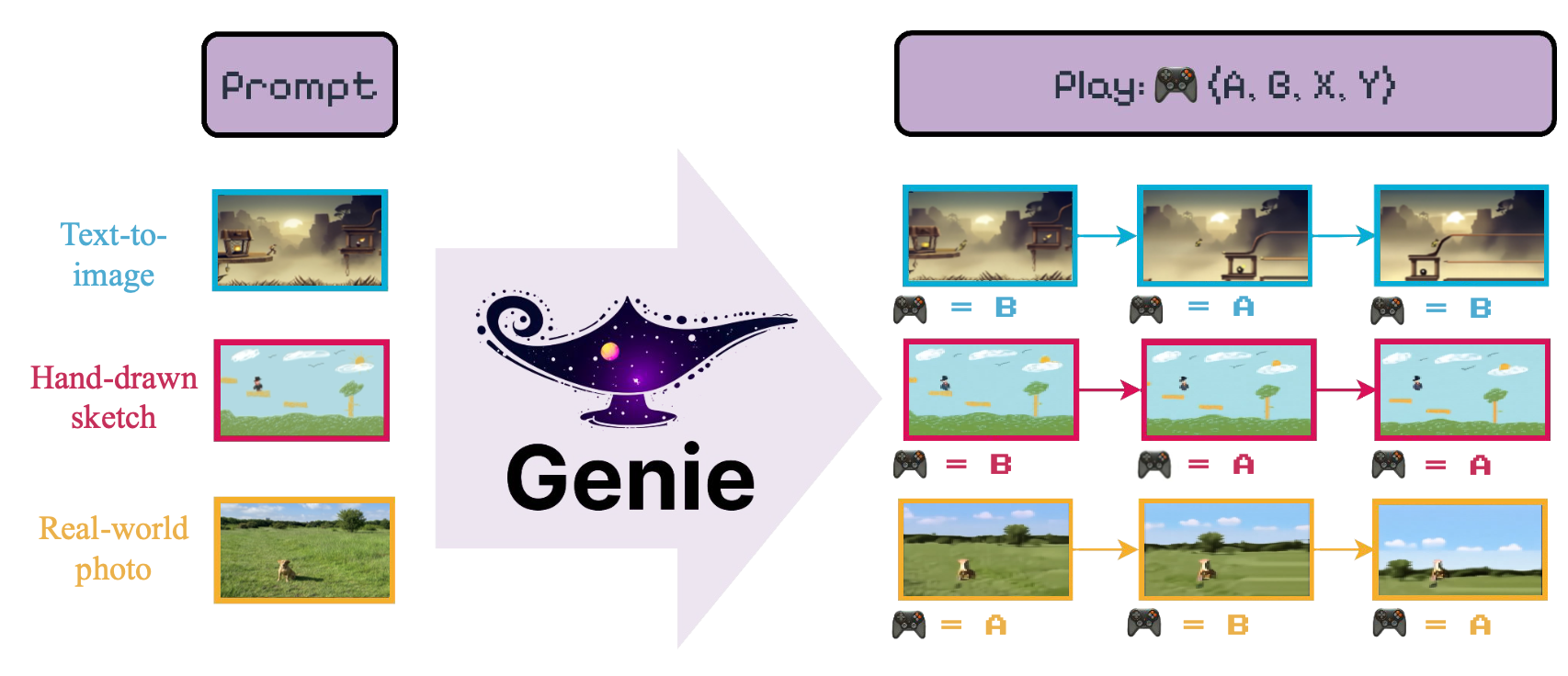
我們提供了LightningCLI界面,以輕鬆訓練Genie模型的幾個組件。特別是,要訓練VideoTokenizer ,應該運行以下
python tokenizer.py train -config < path_to_conf_file >為了培訓LatentAction和Dynamics模型(又使用將利用全面訓練的VideoTokenizer ),人們可以再次簡單地運行:
python genie.py train -config < path_to_conf_file >我們在config文件夾中提供示例配置文件。
在以下各節中,我們為核心構建塊提供了示例代碼,這些核心構建塊共同構成了整個Genie模塊。
Genie依靠VideoTokenizer ,該視頻源會消化輸入視頻並通過其encode - quantize功能將其轉換為離散令牌。這些令牌是Dynamics模塊來操縱潛在視頻空間的方法。 VideoTokenizer模塊接受多個用於廣泛自定義的參數,這是典型用途的示例代碼:
from genie import VideoTokenizer
# Pre-assembled description of MagViT2
# encoder & decoder architecture
from genie import MAGVIT2_ENC_DESC
from genie import MAGVIT2_DEC_DESC
tokenizer = VideoTokenizer (
# We can pass an arbitrary description of the
# encoder architecture, see genie.tokenizer.get_module
# to see which module are supported
enc_desc = (
'causal' , { # A CausalConv3d layer
'in_channels' : 3 ,
'out_channels' : 64 ,
'kernel_size' : 3 ,
}),
( 'residual' , { # Residual Block
'in_channels' : 64 ,
'kernel_size' : 3 ,
'downsample' : ( 1 , 2 ), # Optional down-scaling (time, space)
'use_causal' : True , # Using causal padding
'use_blur' : True , # Using blur-pooling
}),
( 'residual' , {
'in_channels' : 64 ,
'out_channels' : 128 , # Output channels can be different
}),
( 'residual' , {
'n_rep' : 2 , # We can repeat this block N-times
'in_channels' : 128 ,
}),
( 'residual' , {
'in_channels' : 128 ,
'out_channels' : 256 , # We can mix different output channels...
'kernel_size' : 3 ,
'downsample' : 2 , # ...with down-sampling (here time=space=2)
'use_causal' : True ,
}),
( 'proj_out' , { # Output project to quantization module
'in_channels' : 256 ,
'out_channels' : 18 ,
'num_groups' : 8 ,
'kernel_size' : 3 ,
}),
# Save time, use a pre-made configuration!
dec_desc = MAGVIT2_DEC_DESC ,
# Description of GAN discriminator
disc_kwargs = dict (
# Discriminator parameters
inp_size = ( 64 , 64 ), # Size of input frames
model_dim = 64 ,
dim_mults = ( 1 , 2 , 4 ), # Channel multipliers
down_step = ( None , 2 , 2 ), # Down-sampling steps
inp_channels = 3 ,
kernel_size = 3 ,
num_groups = 8 ,
act_fn = 'leaky' , # Use LeakyReLU as activation function
use_blur = True , # Use BlurPooling for down-sampling
use_attn = True , # Discriminator can have spatial attention
num_heads = 4 , # Number of (spatial) attention heads
dim_head = 32 , # Dimension of each spatial attention heads
),
# Keyword for the LFQ module
d_codebook = 18 , # Codebook dimension, should match encoder output channels
n_codebook = 1 , # Support for multiple codebooks
lfq_bias = True ,
lfq_frac_sample = 1. ,
lfq_commit_weight = 0.25 ,
lfq_entropy_weight = 0.1 ,
lfq_diversity_weight = 1. ,
# Keyword for the different loss
perceptual_model = 'vgg16' , # We pick VGG-16 for perceptual loss
# Which layer should we record perceptual features from
perc_feat_layers = ( 'features.6' , 'features.13' , 'features.18' , 'features.25' ),
gan_discriminate = 'frames' , # GAN discriminator looks at individual frames
gan_frames_per_batch = 4 , # How many frames to extract from each video to use for GAN
gan_loss_weight = 1. ,
perc_loss_weight = 1. ,
quant_loss_weight = 1. ,
)
batch_size = 4
num_channels = 3
num_frames = 16
img_h , img_w = 64 , 64
# Example video tensor
mock_video = torch . randn (
batch_size ,
num_channels ,
num_frames ,
img_h ,
img_w
)
# Tokenize input video
tokens , idxs = tokenizer . tokenize ( mock_video )
# Tokenized video has shape:
# (batch_size, d_codebook, num_frames // down_time, H // down_space, W // down_space)
# To decode the video from tokens use:
rec_video = tokenizer . decode ( tokens )
# To train the tokenizer (do many! times)
loss , aux_losses = tokenizer ( mock_video )
loss . backward ()Genie實現了一個LatentAction模型,其唯一任務是正式化(離散的)潛在動作代碼。該代碼簿的設計很小,以鼓勵可解釋的動作(例如MOVE_RIGHT )。為了訓練該代碼書, LatentAction模型是作為VQ-VAE模型構建的,編碼器攝入視頻(像素)幀並產生(量化的)動作作為潛在的動作。然後,解碼器攝入了先前的幀歷史記錄和當前的動作,以預測下一幀。編碼器和解碼器在推理時間都被丟棄,因為用戶提供了操作。
LatentAction模型遵循與VideoTokenizer類似的設計,可以通過Blueprint指定編碼器/解碼器體系結構。這是突出顯示核心組件的示例代碼:
from genie import LatentAction
from genie import LATENT_ACT_ENC
model = LatentAction (
# Use a pre-made configuration...
enc_desc = LATENT_ACT_ENC ,
# ...Or specify a brand-new one
dec_desc = (
# Latent Action uses space-time transformer
( 'space-time_attn' , {
'n_rep' : 2 ,
'n_embd' : 256 ,
'n_head' : 4 ,
'd_head' : 16 ,
'has_ext' : True ,
# Decoder uses latent action as external
# conditioning for decoding!
'time_attn_kw' : { 'key_dim' : 8 },
}),
# But we can also down/up-sample to manage resources
# NOTE: Encoder & Decoder should work nicely together
# so that down/up-samples cancel out
( 'spacetime_upsample' , {
'in_channels' : 256 ,
'kernel_size' : 3 ,
'time_factor' : 1 ,
'space_factor' : 2 ,
}),
( 'space-time_attn' , {
'n_rep' : 2 ,
'n_embd' : 256 ,
'n_head' : 4 ,
'd_head' : 16 ,
'has_ext' : True ,
'time_attn_kw' : { 'key_dim' : 8 },
}),
),
d_codebook = 8 , # Small codebook to incentivize interpretability
inp_channels = 3 , # Input video channel
inp_shape = ( 64 , 64 ), # Spatial frame dimensions
n_embd = 256 , # Hidden model dimension
# [...] Other kwargs for controlling LFQ module behavior
)
# Create mock input video
batch_size = 2
video_len = 16
frame_dim = 64 , 64
video = torch . randn ( batch_size , 3 , video_len , * frame_dim )
# Encode the video to extract the latent actions
( actions , encoded ), quant_loss = model . encode ( video )
# Compute the reconstructed video and its loss
recon , loss , aux_losses = model ( video )
# This should work!
assert recon . shape == ( batch_size , 3 , video_len , * frame_dim )
# Train the model
loss . backward ()DynamicsModel任務是根據過去的視頻令牌和潛在的動作歷史來預測下一個視頻令牌。該體系結構基於Chang等人(2022)的MaskGIT模型。這是突出顯示核心組件的示例代碼:
from genie import DynamicsModel
blueprint = (
# Describe a Space-Time Transformer
( 'space-time_attn' , {
'n_rep' : 4 , # Number of layers
'n_embd' : 256 , # Hidden dimension
'n_head' : 4 , # Number of attention heads
'd_head' : 16 , # Dimension of each attention head
'transpose' : False ,
}),
)
# Create the model
tok_codebook = 16 # Dimension of video tokenizer codebook
act_codebook = 4 # Dimension of latent action codebook
dynamics = DynamicsModel (
desc = blueprint ,
tok_vocab = tok_codebook ,
act_vocab = act_codebook ,
embed_dim = 256 , # Hidden dimension of the model
)
batch_size = 2
num_frames = 16
img_size = 32
# Create mock token and latent action inputs
mock_tokens = torch . randint ( 0 , tok_codebook , ( batch_size , num_frames , img_size , img_size ))
mock_act_id = torch . randint ( 0 , act_codebook , ( batch_size , num_frames ))
# Compute the reconstruction loss based on Bernoulli
# masking of input tokens
loss = dynamics . compute_loss (
mock_tokens ,
mock_act_id ,
)
# Generate the next video token
new_tokens = dynamics . generate (
mock_tokens ,
mock_act_id ,
steps = 5 , # Number of MaskGIT sampling steps
)
assert new_tokes . shape == ( batch_size , num_frame + 1 , img_size , img_size )用Python 3.11+測試了代碼,並且需要torch 2.0+ (由於使用快速閃存注意力)。要安裝所需的依賴項,只需運行pip install -r requirements.txt
該倉庫建立在Lucidrains的美麗Magvit實施的基礎上,以及Valeoai的Maskgit實施。
@article { bruce2024genie ,
title = { Genie: Generative Interactive Environments } ,
author = { Bruce, Jake and Dennis, Michael and Edwards, Ashley and Parker-Holder, Jack and Shi, Yuge and Hughes, Edward and Lai, Matthew and Mavalankar, Aditi and Steigerwald, Richie and Apps, Chris and others } ,
journal = { arXiv preprint arXiv:2402.15391 } ,
year = { 2024 }
} @article { yu2023language ,
title = { Language Model Beats Diffusion--Tokenizer is Key to Visual Generation } ,
author = { Yu, Lijun and Lezama, Jos{'e} and Gundavarapu, Nitesh B and Versari, Luca and Sohn, Kihyuk and Minnen, David and Cheng, Yong and Gupta, Agrim and Gu, Xiuye and Hauptmann, Alexander G and others } ,
journal = { arXiv preprint arXiv:2310.05737 } ,
year = { 2023 }
} @inproceedings { chang2022maskgit ,
title = { Maskgit: Masked generative image transformer } ,
author = { Chang, Huiwen and Zhang, Han and Jiang, Lu and Liu, Ce and Freeman, William T } ,
booktitle = { Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition } ,
pages = { 11315--11325 } ,
year = { 2022 }
}

