open genie
1.0.0
Ce repo contient la mise en œuvre non officielle du génie: des environnements interactifs génératifs Bruce et al. (2024) Tel que présenté par Google Deepmind.
L'objectif du modèle est d'introduire "[...] le premier environnement interactif génératif formé de manière non supervisée à partir de vidéos Internet non marquées".
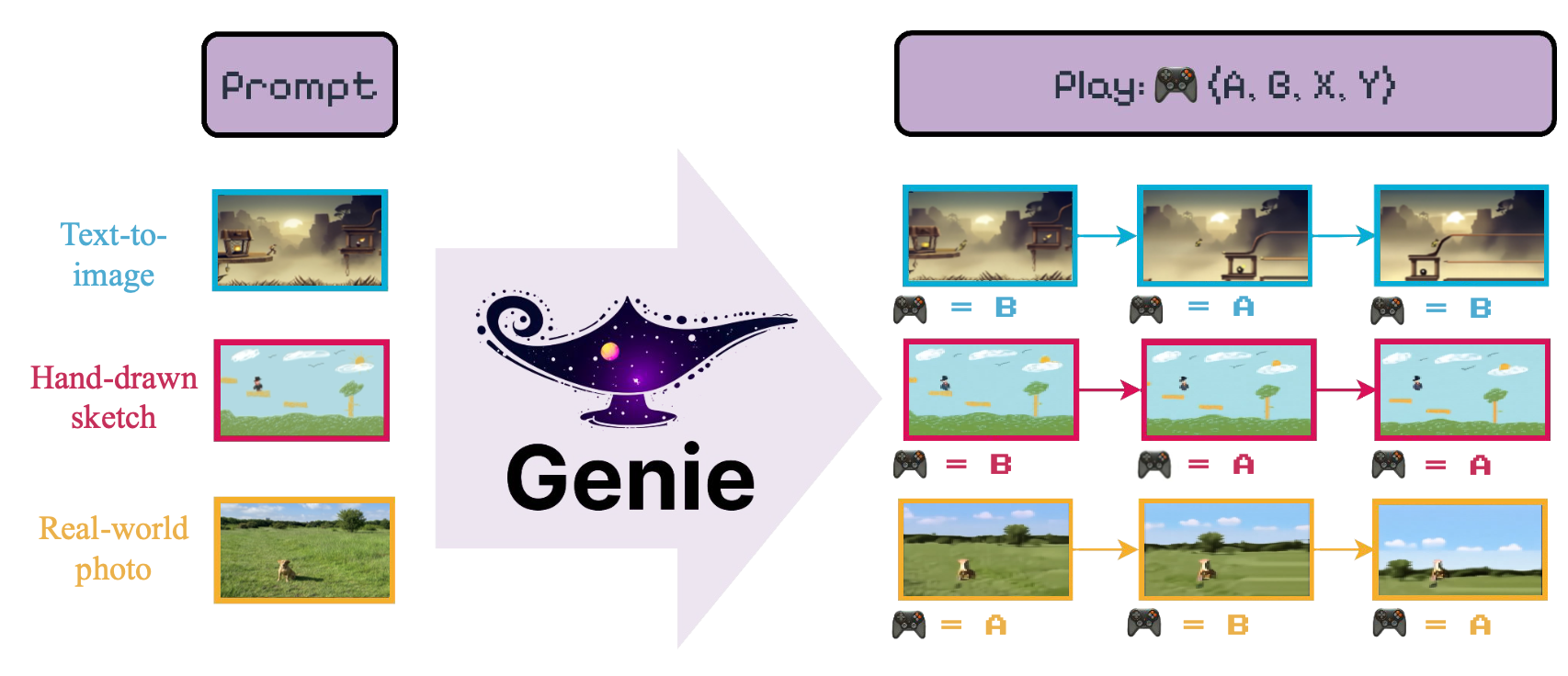
Nous fournissons une interface LightningCLI pour entraîner facilement les plusieurs composants du modèle Genie . En particulier, pour entraîner le VideoTokenizer , il faut exécuter ce qui suit
python tokenizer.py train -config < path_to_conf_file > Pour former à la fois le modèle LatentAction et Dynamics (l'utilisation à son tour exploiterait un VideoTokenizer entièrement formé), on peut à nouveau courir:
python genie.py train -config < path_to_conf_file > Nous fournissons des exemples de fichiers de configuration dans le dossier config .
Dans les sections suivantes, nous fournissons des exemples de codes pour les éléments constitutifs de base qui forment ensemble le module de génie global.
Genie s'appuie sur un VideoTokenizer qui digère les vidéos d'entrée et via son encode - quantize Capacités les convertit en jetons discrets. Ces jetons sont ce que le module Dynamics utilise pour manipuler l'espace vidéo latent . Le module VideoTokenizer accepte plusieurs paramètres pour une personnalisation approfondie, voici un exemple de code pour une utilisation typique:
from genie import VideoTokenizer
# Pre-assembled description of MagViT2
# encoder & decoder architecture
from genie import MAGVIT2_ENC_DESC
from genie import MAGVIT2_DEC_DESC
tokenizer = VideoTokenizer (
# We can pass an arbitrary description of the
# encoder architecture, see genie.tokenizer.get_module
# to see which module are supported
enc_desc = (
'causal' , { # A CausalConv3d layer
'in_channels' : 3 ,
'out_channels' : 64 ,
'kernel_size' : 3 ,
}),
( 'residual' , { # Residual Block
'in_channels' : 64 ,
'kernel_size' : 3 ,
'downsample' : ( 1 , 2 ), # Optional down-scaling (time, space)
'use_causal' : True , # Using causal padding
'use_blur' : True , # Using blur-pooling
}),
( 'residual' , {
'in_channels' : 64 ,
'out_channels' : 128 , # Output channels can be different
}),
( 'residual' , {
'n_rep' : 2 , # We can repeat this block N-times
'in_channels' : 128 ,
}),
( 'residual' , {
'in_channels' : 128 ,
'out_channels' : 256 , # We can mix different output channels...
'kernel_size' : 3 ,
'downsample' : 2 , # ...with down-sampling (here time=space=2)
'use_causal' : True ,
}),
( 'proj_out' , { # Output project to quantization module
'in_channels' : 256 ,
'out_channels' : 18 ,
'num_groups' : 8 ,
'kernel_size' : 3 ,
}),
# Save time, use a pre-made configuration!
dec_desc = MAGVIT2_DEC_DESC ,
# Description of GAN discriminator
disc_kwargs = dict (
# Discriminator parameters
inp_size = ( 64 , 64 ), # Size of input frames
model_dim = 64 ,
dim_mults = ( 1 , 2 , 4 ), # Channel multipliers
down_step = ( None , 2 , 2 ), # Down-sampling steps
inp_channels = 3 ,
kernel_size = 3 ,
num_groups = 8 ,
act_fn = 'leaky' , # Use LeakyReLU as activation function
use_blur = True , # Use BlurPooling for down-sampling
use_attn = True , # Discriminator can have spatial attention
num_heads = 4 , # Number of (spatial) attention heads
dim_head = 32 , # Dimension of each spatial attention heads
),
# Keyword for the LFQ module
d_codebook = 18 , # Codebook dimension, should match encoder output channels
n_codebook = 1 , # Support for multiple codebooks
lfq_bias = True ,
lfq_frac_sample = 1. ,
lfq_commit_weight = 0.25 ,
lfq_entropy_weight = 0.1 ,
lfq_diversity_weight = 1. ,
# Keyword for the different loss
perceptual_model = 'vgg16' , # We pick VGG-16 for perceptual loss
# Which layer should we record perceptual features from
perc_feat_layers = ( 'features.6' , 'features.13' , 'features.18' , 'features.25' ),
gan_discriminate = 'frames' , # GAN discriminator looks at individual frames
gan_frames_per_batch = 4 , # How many frames to extract from each video to use for GAN
gan_loss_weight = 1. ,
perc_loss_weight = 1. ,
quant_loss_weight = 1. ,
)
batch_size = 4
num_channels = 3
num_frames = 16
img_h , img_w = 64 , 64
# Example video tensor
mock_video = torch . randn (
batch_size ,
num_channels ,
num_frames ,
img_h ,
img_w
)
# Tokenize input video
tokens , idxs = tokenizer . tokenize ( mock_video )
# Tokenized video has shape:
# (batch_size, d_codebook, num_frames // down_time, H // down_space, W // down_space)
# To decode the video from tokens use:
rec_video = tokenizer . decode ( tokens )
# To train the tokenizer (do many! times)
loss , aux_losses = tokenizer ( mock_video )
loss . backward () Genie implémente un modèle LatentAction dont la seule tâche est de formaliser un livre de codes (discret) des actions latentes. Ce livre de codes est petit par conception pour encourager les actions interprétables (telles que MOVE_RIGHT ). Afin de former un tel livre de codes, le modèle LatentAction est construit sous forme de modèle VQ-VAE , où l'encodeur ingère les cadres vidéo (pixel) et produit des actions (quantifiées) comme des latents. Le décodeur ingère ensuite l'historique du trame précédent et l'action actuelle pour prédire le cadre suivant. L'encodeur et le décodeur sont rejetés au moment de l'inférence car l'action est fournie par l'utilisateur.
Le modèle LatentAction suit une conception similaire à celle du VideoTokenizer , où les architectures d'encodeur / décodeur peuvent être spécifiées via un Blueprint . Voici un exemple de code pour mettre en surbrillance les composants principaux:
from genie import LatentAction
from genie import LATENT_ACT_ENC
model = LatentAction (
# Use a pre-made configuration...
enc_desc = LATENT_ACT_ENC ,
# ...Or specify a brand-new one
dec_desc = (
# Latent Action uses space-time transformer
( 'space-time_attn' , {
'n_rep' : 2 ,
'n_embd' : 256 ,
'n_head' : 4 ,
'd_head' : 16 ,
'has_ext' : True ,
# Decoder uses latent action as external
# conditioning for decoding!
'time_attn_kw' : { 'key_dim' : 8 },
}),
# But we can also down/up-sample to manage resources
# NOTE: Encoder & Decoder should work nicely together
# so that down/up-samples cancel out
( 'spacetime_upsample' , {
'in_channels' : 256 ,
'kernel_size' : 3 ,
'time_factor' : 1 ,
'space_factor' : 2 ,
}),
( 'space-time_attn' , {
'n_rep' : 2 ,
'n_embd' : 256 ,
'n_head' : 4 ,
'd_head' : 16 ,
'has_ext' : True ,
'time_attn_kw' : { 'key_dim' : 8 },
}),
),
d_codebook = 8 , # Small codebook to incentivize interpretability
inp_channels = 3 , # Input video channel
inp_shape = ( 64 , 64 ), # Spatial frame dimensions
n_embd = 256 , # Hidden model dimension
# [...] Other kwargs for controlling LFQ module behavior
)
# Create mock input video
batch_size = 2
video_len = 16
frame_dim = 64 , 64
video = torch . randn ( batch_size , 3 , video_len , * frame_dim )
# Encode the video to extract the latent actions
( actions , encoded ), quant_loss = model . encode ( video )
# Compute the reconstructed video and its loss
recon , loss , aux_losses = model ( video )
# This should work!
assert recon . shape == ( batch_size , 3 , video_len , * frame_dim )
# Train the model
loss . backward () Le DynamicsModel est chargé de prédire le prochain jeton vidéo basé sur les antécédents de jeton vidéo et d'action latente. L'architecture est basée sur le modèle MaskGIT de Chang et al (2022). Voici un exemple de code pour mettre en surbrillance les composants principaux:
from genie import DynamicsModel
blueprint = (
# Describe a Space-Time Transformer
( 'space-time_attn' , {
'n_rep' : 4 , # Number of layers
'n_embd' : 256 , # Hidden dimension
'n_head' : 4 , # Number of attention heads
'd_head' : 16 , # Dimension of each attention head
'transpose' : False ,
}),
)
# Create the model
tok_codebook = 16 # Dimension of video tokenizer codebook
act_codebook = 4 # Dimension of latent action codebook
dynamics = DynamicsModel (
desc = blueprint ,
tok_vocab = tok_codebook ,
act_vocab = act_codebook ,
embed_dim = 256 , # Hidden dimension of the model
)
batch_size = 2
num_frames = 16
img_size = 32
# Create mock token and latent action inputs
mock_tokens = torch . randint ( 0 , tok_codebook , ( batch_size , num_frames , img_size , img_size ))
mock_act_id = torch . randint ( 0 , act_codebook , ( batch_size , num_frames ))
# Compute the reconstruction loss based on Bernoulli
# masking of input tokens
loss = dynamics . compute_loss (
mock_tokens ,
mock_act_id ,
)
# Generate the next video token
new_tokens = dynamics . generate (
mock_tokens ,
mock_act_id ,
steps = 5 , # Number of MaskGIT sampling steps
)
assert new_tokes . shape == ( batch_size , num_frame + 1 , img_size , img_size ) Le code a été testé avec Python 3.11+ et nécessite torch 2.0+ (en raison de l'utilisation de l'attention flash rapide). Pour installer les dépendances requises, exécutez simplement pip install -r requirements.txt
Ce repo s'appuie sur la magnifique implémentation Magvit par LucidRains et la mise en œuvre de Maskgit de Valeoai.
@article { bruce2024genie ,
title = { Genie: Generative Interactive Environments } ,
author = { Bruce, Jake and Dennis, Michael and Edwards, Ashley and Parker-Holder, Jack and Shi, Yuge and Hughes, Edward and Lai, Matthew and Mavalankar, Aditi and Steigerwald, Richie and Apps, Chris and others } ,
journal = { arXiv preprint arXiv:2402.15391 } ,
year = { 2024 }
} @article { yu2023language ,
title = { Language Model Beats Diffusion--Tokenizer is Key to Visual Generation } ,
author = { Yu, Lijun and Lezama, Jos{'e} and Gundavarapu, Nitesh B and Versari, Luca and Sohn, Kihyuk and Minnen, David and Cheng, Yong and Gupta, Agrim and Gu, Xiuye and Hauptmann, Alexander G and others } ,
journal = { arXiv preprint arXiv:2310.05737 } ,
year = { 2023 }
} @inproceedings { chang2022maskgit ,
title = { Maskgit: Masked generative image transformer } ,
author = { Chang, Huiwen and Zhang, Han and Jiang, Lu and Liu, Ce and Freeman, William T } ,
booktitle = { Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition } ,
pages = { 11315--11325 } ,
year = { 2022 }
}

