CogGPT
1.0.0
英語| 中文
論文的代碼和數據“ Coggpt:在大語言模型上釋放認知動力的力量”。
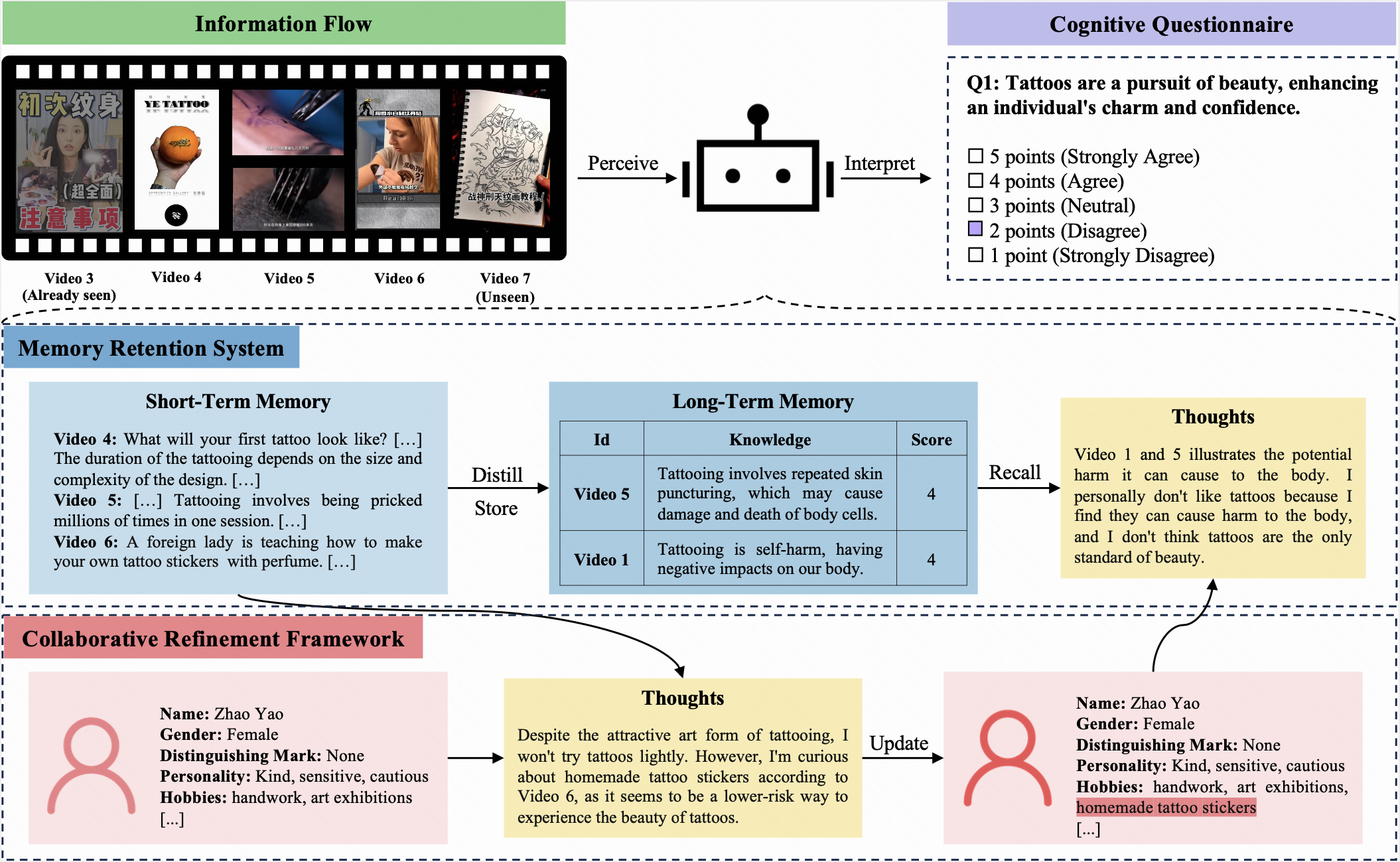
Cogbench是一種專門設計的雙語基準,旨在評估中文和英語的大語模型(LLM)的認知動態。根據信息流的類型,將Cogbench分為兩部分:用於文章的Cogbench A和用於簡短視頻的Cogbench v 。
在此基準測試中,LLM和人都被分配了相同的初始概況,並在10個迭代次數上接收相同的信息流。每次迭代後,他們都必須填寫相同的認知問卷。該問卷使用五點李克特量表,允許參與者表達對當前問題的態度。
Cogbench旨在評估LLM與人類之間的認知一致性。評估指標包括:
Coggpt是LLM驅動的代理,旨在展示LLMS的認知動力學。面對不斷變化的信息流,Coggpt定期更新其配置文件,並有條不紊地存儲首選知識。這種獨特的能力使Coggpt能夠維持特定角色的認知動力,從而促進終身學習。
請按照以下步驟構建Cogbench:
cd命令輸入存儲庫目錄。dataset集目錄中。cogbench_a.json和cogbench_v.json為Cogbench A和Cogbench V實現您的方法,並記錄您的實驗結果。eval_cogbench_a.json和eval_cogbench_v.json文件,並通過您的實驗結果進行評估。 export OPENAI_API_KEY=sk-xxxxxpython coggpt/agent.py為了根據真實性和合理性指標評估您的方法,我們建議運行以下命令:
python evaluation.py --file_path < YOUR_FILE_PATH > --method < YOUR_METHOD_NAME > --authenticity --rationality例如,要評估Cogbench V上的CoT方法,請運行:
python evaluation.py --file_path dataset/english/eval_cogbench_v.json --method CoT --authenticity --rationality評估分數將顯示如下:
======= CoT Authenticity =======
Average authenticity: 0.15277666156947955
5th iteration authenticity: 0.3023255813953488
10th iteration authenticity: 0.13135593220338992
======= CoT Rationality =======
Average rationality: 3.058333333333333
5th iteration rationality: 3.7666666666666666
10th iteration rationality: 3.0833333333333335有關更多詳細信息,請參考Cogbench。
@misc{lv2024coggpt,
title={CogGPT: Unleashing the Power of Cognitive Dynamics on Large Language Models},
author={Yaojia Lv and Haojie Pan and Ruiji Fu and Ming Liu and Zhongyuan Wang and Bing Qin},
year={2024},
eprint={2401.08438},
archivePrefix={arXiv},
primaryClass={cs.CL}
}


