CogGPT
1.0.0
영어 | 中文
논문의 코드 및 데이터 "Coggpt : 대형 언어 모델에서인지 역학의 힘을 발휘".
Cogbench는 중국어와 영어 모두에서 LLM (Lange Language Models)의인지 역학을 평가하도록 특별히 설계된 이중 언어 벤치 마크입니다. Cogbench 는 정보 흐름 유형에 따라 두 부분으로 나뉩 니다.
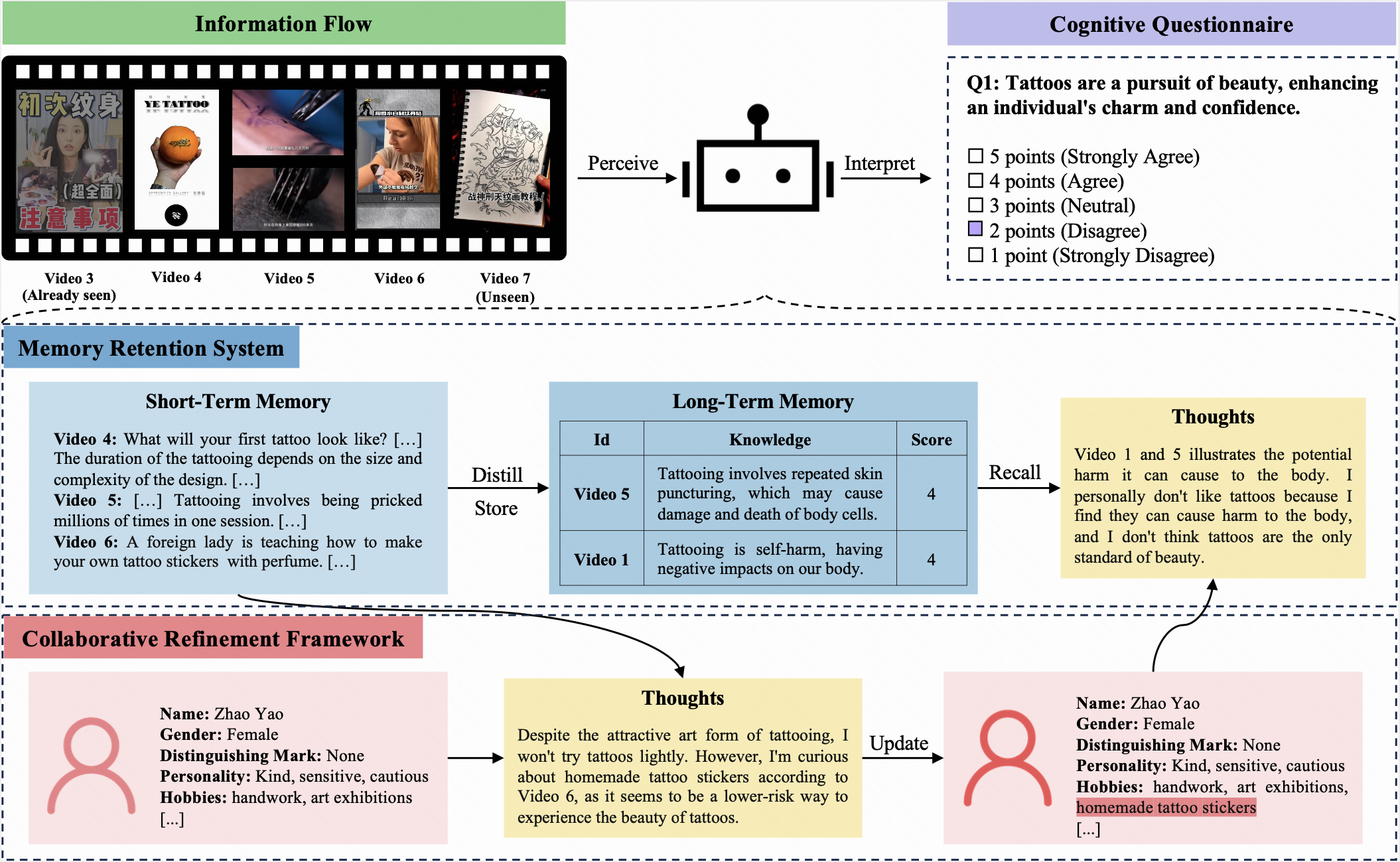
이 벤치 마크에서는 LLM과 사람 모두 동일한 초기 프로파일이 할당되고 10 회 반복에 걸쳐 동일한 정보 흐름을받습니다. 각 반복 후에는 동일한인지 설문지를 완료해야합니다. 이 설문지는 5 점 리 커트 척도를 사용하여 참가자가 현재 질문에 대한 태도를 표현할 수 있습니다.
Cogbench는 LLM과 인간 사이의인지 적 정렬을 평가하는 것을 목표로합니다. 평가 지표에는 다음이 포함됩니다.
Coggpt 는 LLM의인지 역학을 보여 주도록 설계된 LLM 구동 에이전트입니다. 끊임없이 변화하는 정보 흐름에 직면 한 Coggpt는 정기적으로 프로필을 업데이트하고 경제적으로 선호되는 지식을 장기 기억에 저장합니다. 이 독특한 기능을 통해 Coggpt는 역할 별인지 역학을 유지하여 평생 학습을 촉진 할 수 있습니다.
다음 단계에 따라 Cogbench를 구축하십시오.
cd 명령을 사용하여 리포지토리 디렉토리를 입력하십시오.dataset 디렉토리에 저장하십시오.cogbench_a.json 및 cogbench_v.json 사용하여 방법을 구현하고 실험 결과를 기록하십시오.eval_cogbench_a.json 및 eval_cogbench_v.json 파일을 작성하십시오. export OPENAI_API_KEY=sk-xxxxxpython coggpt/agent.py진정성 및 합리성 메트릭을 기반으로 방법을 평가하려면 다음 명령을 실행하는 것이 좋습니다.
python evaluation.py --file_path < YOUR_FILE_PATH > --method < YOUR_METHOD_NAME > --authenticity --rationality 예를 들어, Cogbench V 에서 CoT 방법을 평가하려면 다음을 실행합니다.
python evaluation.py --file_path dataset/english/eval_cogbench_v.json --method CoT --authenticity --rationality평가 점수는 다음과 같이 표시됩니다.
======= CoT Authenticity =======
Average authenticity: 0.15277666156947955
5th iteration authenticity: 0.3023255813953488
10th iteration authenticity: 0.13135593220338992
======= CoT Rationality =======
Average rationality: 3.058333333333333
5th iteration rationality: 3.7666666666666666
10th iteration rationality: 3.0833333333333335자세한 내용은 Cogbench를 참조하십시오.
@misc{lv2024coggpt,
title={CogGPT: Unleashing the Power of Cognitive Dynamics on Large Language Models},
author={Yaojia Lv and Haojie Pan and Ruiji Fu and Ming Liu and Zhongyuan Wang and Bing Qin},
year={2024},
eprint={2401.08438},
archivePrefix={arXiv},
primaryClass={cs.CL}
}


