CogGPT
1.0.0
English | 中文
Code and data for the paper "CogGPT: Unleashing the Power of Cognitive Dynamics on Large Language Models".
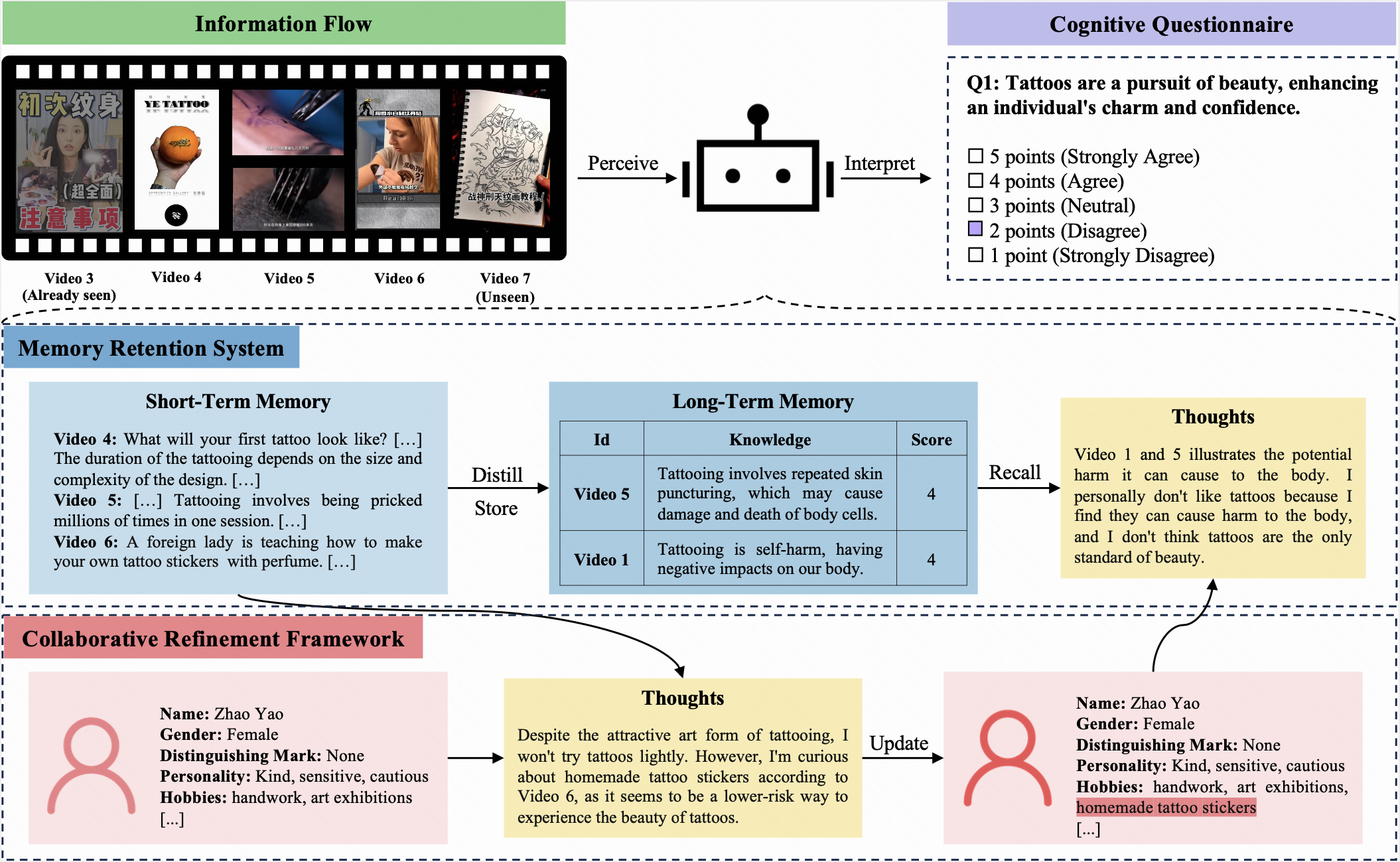
CogBench is a bilingual benchmark specifically designed to evaluate the cognitive dynamics of Large Language Models (LLMs) in both Chinese and English. CogBench is divided into two parts based on the type of information flow: CogBencha for articles and CogBenchv for short videos.
In this benchmark, both an LLM and a human are assigned the same initial profile and receive identical information flows over 10 iterations. After each iteration, they are required to complete the same cognitive questionnaire. This questionnaire, using a five-point Likert scale, allows participants to express their attitudes towards the current questions.
CogBench aims to assess the cognitive alignment between the LLM and the human. The evaluation metrics include:
CogGPT is an LLM-driven agent, designed to showcase the cognitive dynamics of LLMs. Confronted with ever-changing information flows, CogGPT regularly updates its profile and methodically stores preferred knowledge in its long-term memory. This unique capability enables CogGPT to sustain role-specific cognitive dynamics, facilitating lifelong learning.
Follow these steps to build CogBench:
cd command to enter the repository directory.dataset directory.cogbench_a.json and cogbench_v.json for CogBencha and CogBenchv, respectively, and record your experimental results.eval_cogbench_a.json and eval_cogbench_v.json files with your experimental results for evaluations.export OPENAI_API_KEY=sk-xxxxxpython coggpt/agent.pyTo evaluate your method based on the authenticity and rationality metrics, we recommend running the following commands:
python evaluation.py --file_path <YOUR_FILE_PATH> --method <YOUR_METHOD_NAME> --authenticity --rationalityFor example, to evaluate the CoT method on CogBenchv, run:
python evaluation.py --file_path dataset/english/eval_cogbench_v.json --method CoT --authenticity --rationalityThe evaluation scores will be displayed as follows:
======= CoT Authenticity =======
Average authenticity: 0.15277666156947955
5th iteration authenticity: 0.3023255813953488
10th iteration authenticity: 0.13135593220338992
======= CoT Rationality =======
Average rationality: 3.058333333333333
5th iteration rationality: 3.7666666666666666
10th iteration rationality: 3.0833333333333335Please refer to CogBench for more details.
@misc{lv2024coggpt,
title={CogGPT: Unleashing the Power of Cognitive Dynamics on Large Language Models},
author={Yaojia Lv and Haojie Pan and Ruiji Fu and Ming Liu and Zhongyuan Wang and Bing Qin},
year={2024},
eprint={2401.08438},
archivePrefix={arXiv},
primaryClass={cs.CL}
}


