CogGPT
1.0.0
Bahasa Inggris | 中文
Kode dan data untuk makalah "Coggpt: Melepaskan Kekuatan Dinamika Kognitif pada Model Bahasa Besar".
Cogbench adalah tolok ukur bilingual yang dirancang khusus untuk mengevaluasi dinamika kognitif model bahasa besar (LLM) dalam bahasa Cina dan Inggris. Cogbench dibagi menjadi dua bagian berdasarkan jenis aliran informasi: Cogbench A untuk artikel dan Cogbench V untuk video pendek.
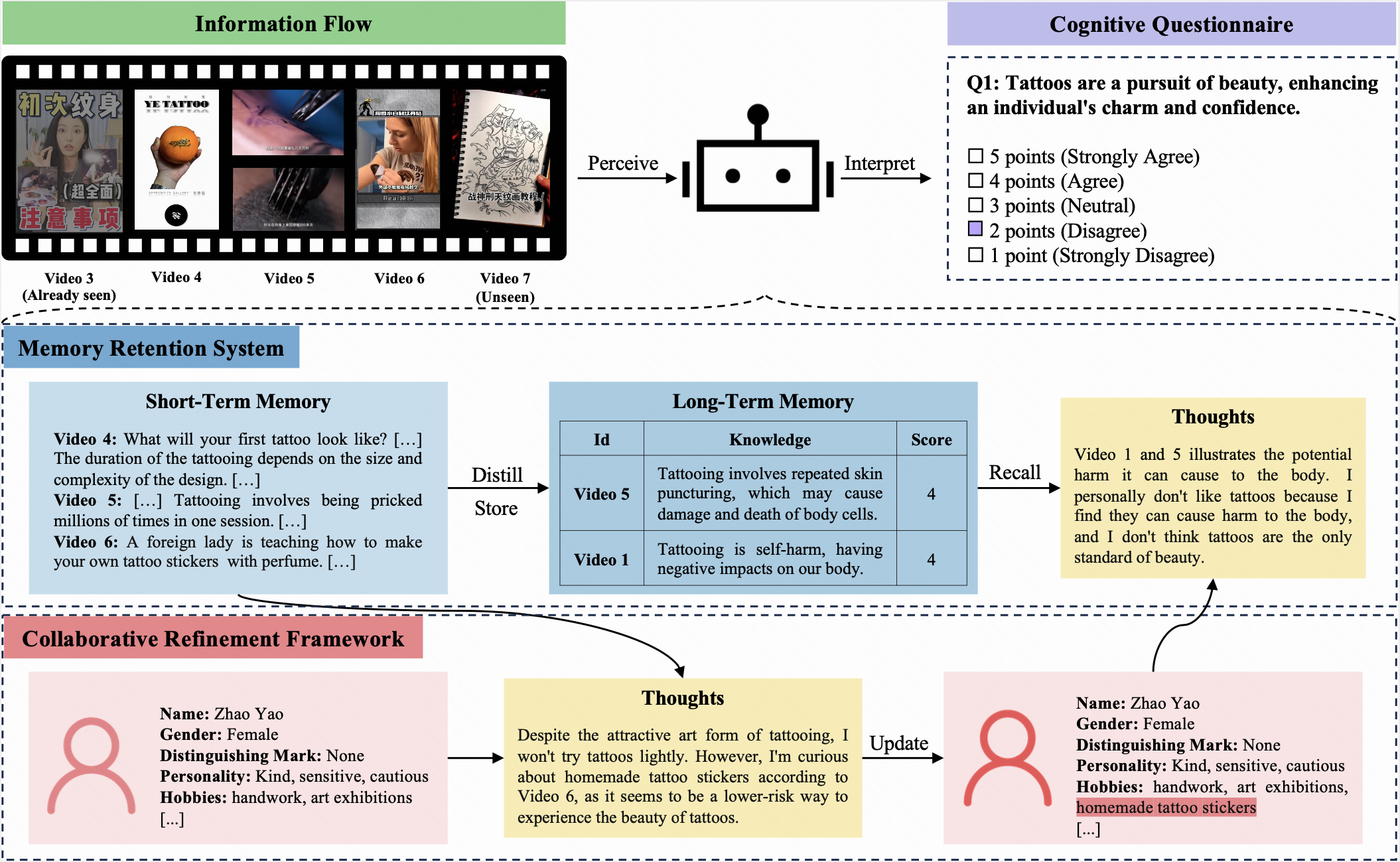
Dalam tolok ukur ini, baik LLM dan manusia diberi profil awal yang sama dan menerima aliran informasi yang identik lebih dari 10 iterasi. Setelah setiap iterasi, mereka diminta untuk mengisi kuesioner kognitif yang sama. Kuesioner ini, menggunakan skala Likert lima poin, memungkinkan peserta untuk mengekspresikan sikap mereka terhadap pertanyaan saat ini.
Cogbench bertujuan untuk menilai penyelarasan kognitif antara LLM dan manusia. Metrik evaluasi meliputi:
COGGPT adalah agen yang digerakkan LLM, yang dirancang untuk menampilkan dinamika kognitif LLMS. Dihadapkan dengan aliran informasi yang terus berubah, CogGpt secara teratur memperbarui profilnya dan secara metodis menyimpan pengetahuan yang disukai dalam memori jangka panjangnya. Kemampuan unik ini memungkinkan COGGPT untuk mempertahankan dinamika kognitif spesifik peran, memfasilitasi pembelajaran seumur hidup.
Ikuti langkah -langkah ini untuk membangun Cogbench:
cd untuk memasukkan direktori repositori.dataset .cogbench_a.json dan cogbench_v.json untuk Cogbench A dan Cogbench V , masing -masing, dan mencatat hasil eksperimen Anda.eval_cogbench_a.json dan eval_cogbench_v.json dengan hasil eksperimen Anda untuk evaluasi. export OPENAI_API_KEY=sk-xxxxxpython coggpt/agent.pyUntuk mengevaluasi metode Anda berdasarkan metrik keaslian dan rasionalitas, kami sarankan menjalankan perintah berikut:
python evaluation.py --file_path < YOUR_FILE_PATH > --method < YOUR_METHOD_NAME > --authenticity --rationality Misalnya, untuk mengevaluasi metode CoT di Cogbench V , Run:
python evaluation.py --file_path dataset/english/eval_cogbench_v.json --method CoT --authenticity --rationalitySkor evaluasi akan ditampilkan sebagai berikut:
======= CoT Authenticity =======
Average authenticity: 0.15277666156947955
5th iteration authenticity: 0.3023255813953488
10th iteration authenticity: 0.13135593220338992
======= CoT Rationality =======
Average rationality: 3.058333333333333
5th iteration rationality: 3.7666666666666666
10th iteration rationality: 3.0833333333333335Silakan merujuk ke Cogbench untuk lebih jelasnya.
@misc{lv2024coggpt,
title={CogGPT: Unleashing the Power of Cognitive Dynamics on Large Language Models},
author={Yaojia Lv and Haojie Pan and Ruiji Fu and Ming Liu and Zhongyuan Wang and Bing Qin},
year={2024},
eprint={2401.08438},
archivePrefix={arXiv},
primaryClass={cs.CL}
}


