CogGPT
1.0.0
Anglais | 中文
Code et données pour l'article "COGGPT: déchaîner la puissance de la dynamique cognitive sur les modèles de grande langue".
Cogbench est une référence bilingue spécialement conçue pour évaluer la dynamique cognitive des modèles de grande langue (LLM) en chinois et en anglais. Cogbench est divisé en deux parties en fonction du type de flux d'informations: Cogbench A pour les articles et Cogbench V pour les vidéos courtes.
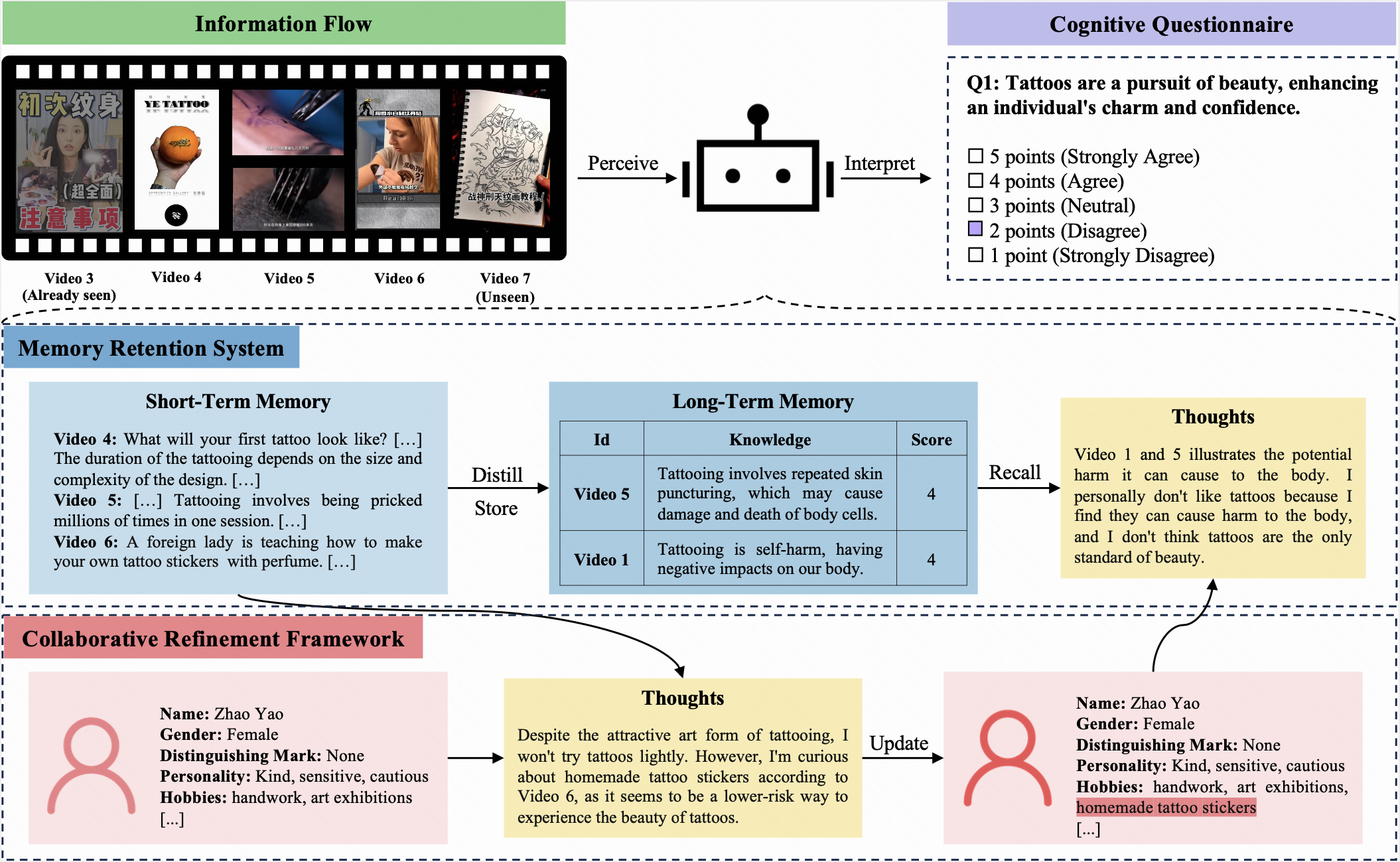
Dans cette référence, un LLM et un humain se voient attribuer le même profil initial et reçoivent des flux d'informations identiques sur 10 itérations. Après chaque itération, ils sont tenus de remplir le même questionnaire cognitif. Ce questionnaire, en utilisant une échelle de Likert à cinq points, permet aux participants d'exprimer leurs attitudes envers les questions actuelles.
Cogbench vise à évaluer l'alignement cognitif entre le LLM et l'humain. Les mesures d'évaluation comprennent:
COGGPT est un agent axé sur le LLM, conçu pour présenter la dynamique cognitive des LLM. Confronté à des flux d'informations en constante évolution, COGGPT met régulièrement à jour son profil et stocke méthodiquement les connaissances préférées dans sa mémoire à long terme. Cette capacité unique permet à COGGPT de maintenir la dynamique cognitive spécifique au rôle, facilitant l'apprentissage tout au long de la vie.
Suivez ces étapes pour construire Cogbench:
cd pour saisir le répertoire du référentiel.dataset .cogbench_a.json et cogbench_v.json pour Cogbench A et Cogbench V , respectivement, et enregistrez vos résultats expérimentaux.eval_cogbench_a.json et eval_cogbench_v.json avec vos résultats expérimentaux pour les évaluations. export OPENAI_API_KEY=sk-xxxxxpython coggpt/agent.pyPour évaluer votre méthode en fonction des mesures d'authenticité et de rationalité, nous vous recommandons d'exécuter les commandes suivantes:
python evaluation.py --file_path < YOUR_FILE_PATH > --method < YOUR_METHOD_NAME > --authenticity --rationality Par exemple, pour évaluer la méthode CoT sur Cogbench V , exécuter:
python evaluation.py --file_path dataset/english/eval_cogbench_v.json --method CoT --authenticity --rationalityLes scores d'évaluation seront affichés comme suit:
======= CoT Authenticity =======
Average authenticity: 0.15277666156947955
5th iteration authenticity: 0.3023255813953488
10th iteration authenticity: 0.13135593220338992
======= CoT Rationality =======
Average rationality: 3.058333333333333
5th iteration rationality: 3.7666666666666666
10th iteration rationality: 3.0833333333333335Veuillez vous référer à Cogbench pour plus de détails.
@misc{lv2024coggpt,
title={CogGPT: Unleashing the Power of Cognitive Dynamics on Large Language Models},
author={Yaojia Lv and Haojie Pan and Ruiji Fu and Ming Liu and Zhongyuan Wang and Bing Qin},
year={2024},
eprint={2401.08438},
archivePrefix={arXiv},
primaryClass={cs.CL}
}


