CogGPT
1.0.0
Englisch | 中文
Code und Daten für das Papier "COGGPT: Freisetzung der Kraft der kognitiven Dynamik auf große Sprachmodelle".
Cogbench ist ein zweisprachiger Benchmark, der speziell für die Bewertung der kognitiven Dynamik von Großsprachmodellen (LLMs) in Chinesisch und Englisch bewertet wurde. Cogbench ist basierend auf der Art des Informationsflusses in zwei Teile unterteilt: Cogbench A für Artikel und Cogbench V für kurze Videos.
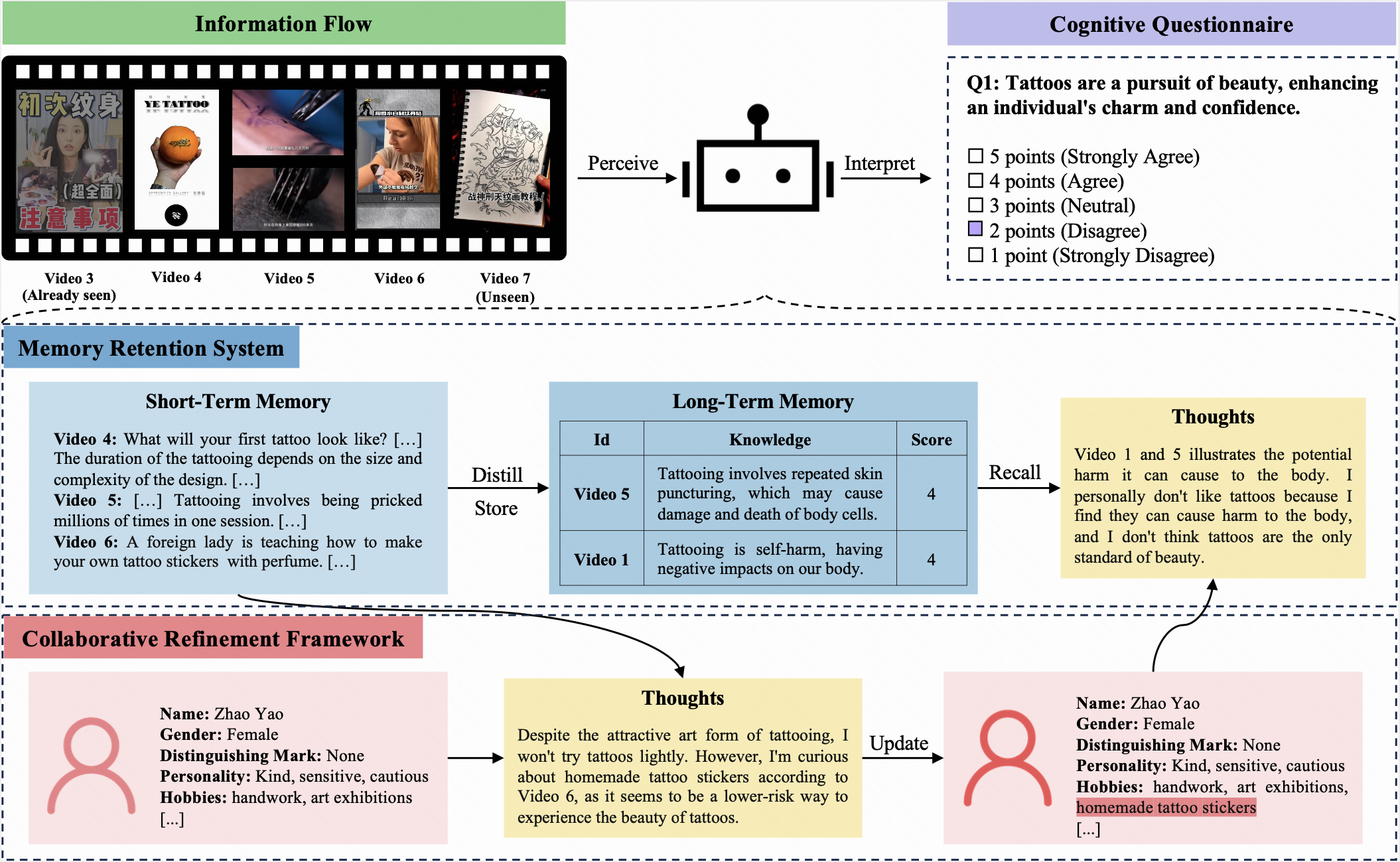
In diesem Benchmark werden sowohl einem LLM als auch einem Menschen das gleiche Anfangsprofil zugewiesen und empfangen identische Informationen über 10 Iterationen. Nach jeder Iteration müssen sie denselben kognitiven Fragebogen ausfüllen. Dieser Fragebogen, der eine Fünf-Punkte-Likert-Skala verwendet, ermöglicht es den Teilnehmern, ihre Einstellungen zu den aktuellen Fragen auszudrücken.
Cogbench zielt darauf ab, die kognitive Ausrichtung zwischen LLM und dem Menschen zu bewerten. Die Bewertungsmetriken umfassen:
COGGPT ist ein LLM-gesteuerter Agent, der die kognitive Dynamik von LLMs präsentiert. COGGPT mit sich ständig verändernden Informationsflüssen konfrontiert sein Profil und speichert das bevorzugte Wissen in seinem Langzeitgedächtnis methodisch. Diese einzigartige Fähigkeit ermöglicht es COGGPT, die rollenspezifische kognitive Dynamik aufrechtzuerhalten und lebenslanges Lernen zu erleichtern.
Befolgen Sie diese Schritte, um Cogbench zu erstellen:
cd , um das Repository -Verzeichnis einzugeben.dataset .cogbench_a.json und cogbench_v.json für Cogbench A bzw. Cogbench V und zeichnen Sie Ihre experimentellen Ergebnisse auf.eval_cogbench_a.json und eval_cogbench_v.json mit Ihren experimentellen Ergebnissen für Bewertungen aus. export OPENAI_API_KEY=sk-xxxxxpython coggpt/agent.pyUm Ihre Methode anhand der Metriken der Authentizität und Rationalität zu bewerten, empfehlen wir, die folgenden Befehle auszuführen:
python evaluation.py --file_path < YOUR_FILE_PATH > --method < YOUR_METHOD_NAME > --authenticity --rationality Um beispielsweise die CoT -Methode auf Cogbench V zu bewerten, rennen Sie:
python evaluation.py --file_path dataset/english/eval_cogbench_v.json --method CoT --authenticity --rationalityDie Bewertungswerte werden wie folgt angezeigt:
======= CoT Authenticity =======
Average authenticity: 0.15277666156947955
5th iteration authenticity: 0.3023255813953488
10th iteration authenticity: 0.13135593220338992
======= CoT Rationality =======
Average rationality: 3.058333333333333
5th iteration rationality: 3.7666666666666666
10th iteration rationality: 3.0833333333333335Weitere Informationen finden Sie in Cogbench.
@misc{lv2024coggpt,
title={CogGPT: Unleashing the Power of Cognitive Dynamics on Large Language Models},
author={Yaojia Lv and Haojie Pan and Ruiji Fu and Ming Liu and Zhongyuan Wang and Bing Qin},
year={2024},
eprint={2401.08438},
archivePrefix={arXiv},
primaryClass={cs.CL}
}


