MAX Image Resolution Enhancer
v1.1.0

該存儲庫包含代碼來實例化和部署圖像分辨率增強程序。該模型能夠以4倍的倍數來將像素化圖像提高,同時生成照片真實的細節。
GAN基於此GitHub存儲庫,並基於本研究文章。
該模型在600,000張OpenImages V4數據集的圖像上進行了培訓,並且模型文件託管在IBM Cloud Object存儲上。此存儲庫中的代碼將模型部署為Docker容器中的Web服務。該存儲庫是作為IBM開發人員模型資產交換的一部分而開發的,公共API由IBM Cloud提供支持。
| 領域 | 應用 | 行業 | 框架 | 培訓數據 | 輸入數據格式 |
|---|---|---|---|---|---|
| 想像 | 超分辨率 | 一般的 | 張量 | 開放映像V4 | 圖像(RGB/HWC) |
| set5 | 作者的Srgan | 這個Srgan |
|---|---|---|
| psnr | 29.40 | 29.56 |
| SSIM | 0.85 | 0.85 |
| set14 | 作者的Srgan | 這個Srgan |
|---|---|---|
| psnr | 26.02 | 26.25 |
| SSIM | 0.74 | 0.72 |
| BSD100 | 作者的Srgan | 這個Srgan |
|---|---|---|
| psnr | 25.16 | 24.4 |
| SSIM | 0.67 | 0.67 |
在三個數據集上評估了該實現的性能:SET5,SET14和BSD100。評估了PSNR(峰信號與噪聲比率)和SSIM(結構相似性指數)指標,儘管該論文將MOS(平均意見分數)視為最有利的度量標準。從本質上講,SRGAN的實施交易更高的PSNR或SSIM得分,以使對人眼更具吸引力。這導致了輸出圖像的集合,這些圖像具有更清晰,更現實的細節。
注意:紙上的Srgan在350k Imagenet樣品上接受了培訓,而該Srgan進行了600K OpenImages V4圖片的培訓。
| 成分 | 執照 | 關聯 |
|---|---|---|
| 這個存儲庫 | Apache 2.0 | 執照 |
| 模型重量 | Apache 2.0 | 執照 |
| 模型代碼(第三方) | 麻省理工學院 | 執照 |
| 測試樣品 | CC由2.0 | 資產讀數 |
| CC0 | 資產讀數 |
docker :Docker命令行接口。按照系統的安裝說明。要運行自動啟動Serving API模型的Docker Image,請運行:
$ docker run -it -p 5000:5000 quay.io/codait/max-image-resolution-enhancer
這將從quay.io容器註冊表中取出預構建的圖像(或使用現有圖像,如果已經在本地緩存)並運行它。如果您想結帳並在本地構建模型,則可以按照下面的本地步驟操作。
您可以通過按照本教程中的OpenShift Web控制台或OpenShift容器平台CLI的指示來在Red Hat OpenShift上部署模型服務的微服務,並指定quay.io/codait/max-image-resolution-enhancer作為圖像名稱。
您還可以使用Quay上的最新Docker映像在Kubernetes上部署模型。
在您的kubernetes群集上,運行以下命令:
$ kubectl apply -f https://github.com/IBM/max-image-resolution-enhancer/raw/master/max-image-resolution-enhancer.yaml
該模型將在端口5000內部提供,但也可以通過NodePort在外部訪問。
可以在此處找到有關如何將這種最大模型部署到IBM雲上生產的更精細的教程。
在本地克隆此存儲庫。在終端中,運行以下命令:
$ git clone https://github.com/IBM/max-image-resolution-enhancer.git
將目錄更改為存儲庫基礎文件夾:
$ cd max-image-resolution-enhancer
要在本地構建Docker映像,請運行:
$ docker build -t max-image-resolution-enhancer .
所有必需的模型資產將在構建過程中下載。請注意,當前此Docker映像僅是CPU(我們將稍後添加對GPU圖像的支持)。
要運行自動啟動Serving API模型的Docker Image,請運行:
$ docker run -it -p 5000:5000 max-image-resolution-enhancer
API服務器會自動生成一個交互式搖搖欲墜的文檔頁面。轉到http://localhost:5000加載它。您可以從那裡探索API並創建測試請求。
使用model/predict端點加載測試圖像(您可以使用samples/test_examples/low_resolution文件夾中的測試圖像之一),以便返回高分辨率輸出圖像。
理想的輸入圖像是一個PNG文件,其分辨率在100x100和500x500之間,最好是沒有任何捕捉後處理和浮華的顏色。該模型能夠從像素化圖像(低DPI)中生成細節,但無法糾正“模糊”圖像。
 左:輸入圖像(128×80)。右:輸出圖像(512×320)
左:輸入圖像(128×80)。右:輸出圖像(512×320)
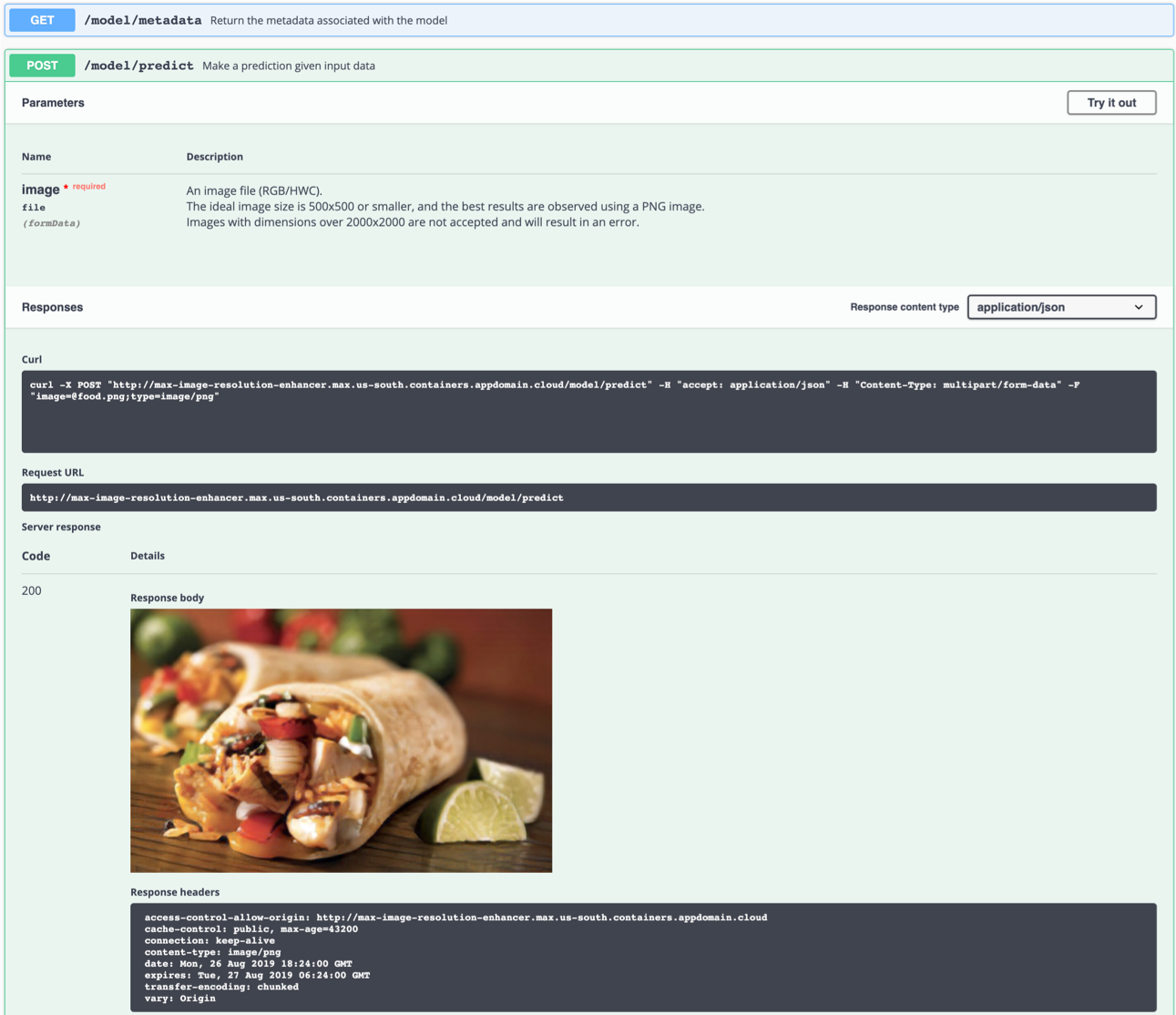
您也可以在命令行上進行測試,例如:
$ curl -F "image=@samples/test_examples/low_resolution/food.png" -XPOST http://localhost:5000/model/predict > food_high_res.png
上面的命令將將低分辨率food.png文件發送到模型,並將高分辨率輸出圖像保存到root目錄中的food_high_res.png文件。
要以調試模式運行Blask API應用程序,請編輯config.py在應用程序設置下設置DEBUG = True 。然後,您需要重建Docker映像(請參閱第1步)。
請記住,在生產中運行模型時,請設置DEBUG = False 。
要停止Docker容器,請在終端中鍵入CTRL + C
model/predict端點會Killed碼頭容器這可能是由於Docker內存分配給2 GB的默認限製而引起的。導航到Docker Desktop應用程序下的
Preferences菜單。使用滑塊將可用的內存增加到8 GB,然後重新啟動Docker桌面。
該模型基本上生成了細節“稀薄的空氣”。沒有做出假設,就不可能創造出任何東西。該網絡試圖在低分辨率圖像中識別元素可以從中推斷出現實(人眼|超分辨率)的外觀。如果一組像素強烈類似於與圖像內容無關的觀察結果,則可能導致觀察結果“物理上可能”。
例如:低分辨率圖像中的白色像素可能已轉換為雪花,儘管原始圖片可能是在沙漠中拍攝的。這個示例是虛構的,實際上尚未觀察到。
不幸的是,在某些圖像中觀察人工製品是不可避免的,因為任何神經網絡都受到培訓數據的技術限制和特徵。
請記住,以下最佳結果是:
- PNG圖像
- 一個足夠放大的圖像。在此過程中,網絡將一個像素塊分組在一起。如果該塊包含的細節多於網絡的產生,則結果將是虛假的。
- 在自然光下拍攝的圖像,沒有過濾器,幾乎沒有明亮或浮華的顏色。神經網絡未經大量編輯的圖像進行培訓。
- 具有足夠高分辨率的圖像不會使網絡與多種可能性混淆(例如,非常低分辨率的圖像中的唯一像素可以代表整個汽車,人,三明治,..)
- 該模型能夠從像素化圖像(低DPI)中生成細節,但無法糾正“模糊”圖像。
如果您有興趣為模型資產交換項目做出貢獻或有任何疑問,請按照此處的說明進行操作。


