MAX Image Resolution Enhancer
v1.1.0

Este repositório contém código para instanciar e implantar um intensificador de resolução de imagem. Este modelo é capaz de aumentar uma imagem pixelizada por um fator de 4, enquanto gera detalhes foto-realistas.
O GAN é baseado neste repositório do GitHub e neste artigo de pesquisa.
O modelo foi treinado em 600.000 imagens do conjunto de dados do OpenImages V4 e os arquivos do modelo são hospedados no armazenamento de objetos em nuvem IBM. O código deste repositório implanta o modelo como um serviço da Web em um contêiner do Docker. Esse repositório foi desenvolvido como parte da troca de ativos do IBM Developer Model e a API pública é alimentada pela IBM Cloud.
| Domínio | Aplicativo | Indústria | Estrutura | Dados de treinamento | Formato de dados de entrada |
|---|---|---|---|---|---|
| Visão | Super-resolução | Em geral | Tensorflow | OpenImages v4 | Imagem (RGB/HWC) |
| Set5 | Srgan do autor | Este srgan |
|---|---|---|
| Psnr | 29.40 | 29.56 |
| Ssim | 0,85 | 0,85 |
| Set14 | Srgan do autor | Este srgan |
|---|---|---|
| Psnr | 26.02 | 26.25 |
| Ssim | 0,74 | 0,72 |
| BSD100 | Srgan do autor | Este srgan |
|---|---|---|
| Psnr | 25.16 | 24.4 |
| Ssim | 0,67 | 0,67 |
O desempenho desta implementação foi avaliado em três conjuntos de dados: SET5, SET14 e BSD100. As métricas PSNR (Pico de sinal / ruído) e SSIM (índice de similaridade estrutural) foram avaliadas, embora o artigo discute o MOS (pontuação média de opinião) como a métrica mais favorável. Em essência, a implementação do SRGAN negocia uma melhor pontuação PSNR ou SSIM, para um resultado mais atraente para o olho humano. Isso leva a uma coleção de imagens de saída com detalhes mais nítidos e realistas.
NOTA: O srgan no papel foi treinado em amostras de imagenet de 350k, enquanto este srgan foi treinado em fotos de 600k OpenImages V4.
| Componente | Licença | Link |
|---|---|---|
| Este repositório | Apache 2.0 | LICENÇA |
| Pesos do modelo | Apache 2.0 | LICENÇA |
| Código do modelo (3ª festa) | Mit | LICENÇA |
| Amostras de teste | CC por 2.0 | Readme de ativos |
| CC0 | Readme de ativos |
docker : a interface da linha de comando do docker. Siga as instruções de instalação para o seu sistema.Para executar a imagem do Docker, que inicia automaticamente a API de servir o modelo, execute:
$ docker run -it -p 5000:5000 quay.io/codait/max-image-resolution-enhancer
Isso extrairá uma imagem pré-criada do registro do recipiente do Quay.io (ou usará uma imagem existente se já em cache localmente) e executá-la. Se você preferir verificar e criar o modelo localmente, poderá seguir as etapas de execução localmente abaixo.
Você pode implantar o microsserviço que serve modelo no Red Hat OpenShift, seguindo as instruções para o OpenShift Web Console ou quay.io/codait/max-image-resolution-enhancer plataforma de contêineres OpenShift CLI neste tutorial, especificando o nome da imagem.
Você também pode implantar o modelo no Kubernetes usando a imagem mais recente do Docker no Quay.
Em seu cluster Kubernetes, execute os seguintes comandos:
$ kubectl apply -f https://github.com/IBM/max-image-resolution-enhancer/raw/master/max-image-resolution-enhancer.yaml
O modelo estará disponível internamente na porta 5000 , mas também pode ser acessado externamente através do NodePort .
Um tutorial mais elaborado sobre como implantar esse modelo máximo para produção no IBM Cloud pode ser encontrado aqui.
Clone este repositório localmente. Em um terminal, execute o seguinte comando:
$ git clone https://github.com/IBM/max-image-resolution-enhancer.git
Altere o diretório para a pasta base do repositório:
$ cd max-image-resolution-enhancer
Para construir a imagem do Docker localmente, execute:
$ docker build -t max-image-resolution-enhancer .
Todos os ativos de modelo necessários serão baixados durante o processo de construção. Observe que atualmente essa imagem do Docker é apenas a CPU (adicionaremos suporte para imagens de GPU posteriormente).
Para executar a imagem do Docker, que inicia automaticamente a API de servir o modelo, execute:
$ docker run -it -p 5000:5000 max-image-resolution-enhancer
O servidor da API gera automaticamente uma página de documentação de arrogância interativa. Vá para http://localhost:5000 para carregá -lo. A partir daí, você pode explorar a API e também criar solicitações de teste.
Use o model/predict o terminal para carregar uma imagem de teste (você pode usar uma das imagens de teste da pasta samples/test_examples/low_resolution ) para obter uma imagem de saída de alta resolução retornada.
A imagem de entrada ideal é um arquivo PNG com uma resolução entre 100x100 e 500x500, de preferência sem qualquer processamento pós-captura e cores chamativas. O modelo é capaz de gerar detalhes a partir de uma imagem pixelizada (DPI baixa), mas não pode corrigir uma imagem 'borrada'.
 Esquerda: imagem de entrada (128 × 80). Direita: Imagem de saída (512 × 320)
Esquerda: imagem de entrada (128 × 80). Direita: Imagem de saída (512 × 320)
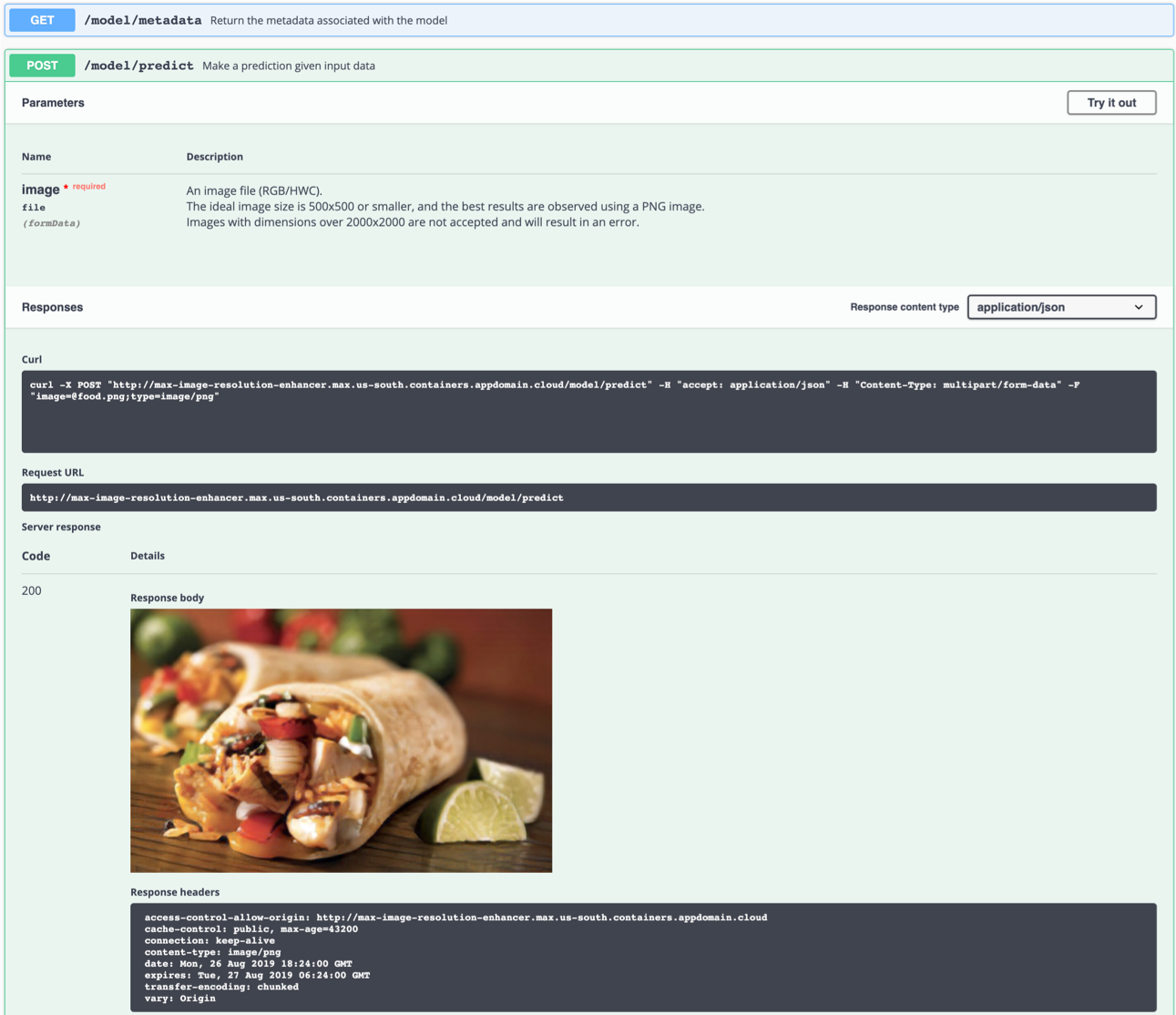
Você também pode testá -lo na linha de comando, por exemplo:
$ curl -F "image=@samples/test_examples/low_resolution/food.png" -XPOST http://localhost:5000/model/predict > food_high_res.png
food_high_res.png comando acima enviará o arquivo de baixa resolução food.png .
Para executar o aplicativo API do Flask no modo de depuração, edite config.py para definir DEBUG = True nas configurações do aplicativo. Você precisará reconstruir a imagem do Docker (consulte a Etapa 1).
Lembre -se de definir DEBUG = False ao executar o modelo em produção.
Para parar o recipiente do docker, digite CTRL + C no seu terminal.
model/predict final mata o recipiente do docker com a mensagem KilledIsso provavelmente é causado devido à limitação padrão da alocação de memória do Docker a 2 GB. Navegue até o menu
Preferencesno aplicativo Docker Desktop. Use o controle deslizante para aumentar a memória disponível para 8 GB e reiniciar o Docker Desktop.
Este modelo gera detalhes basicamente 'do ar'. Criar algo do nada não é possível sem fazer suposições. A rede tenta reconhecer elementos na imagem de baixa resolução da qual pode inferir como a realidade (olho humano | super-resolução) poderia ter parecido. Se um grupo de pixels se assemelha fortemente a uma observação que não está relacionada ao conteúdo da imagem, isso pode levar a observar resultados que não são "fisicamente possíveis".
Por exemplo: Um pixel branco em uma imagem de baixa resolução pode ter sido convertido em um floco de neve, embora a imagem original possa ter sido tirada no deserto. Este exemplo é imaginário e não foi realmente observado.
Infelizmente, observar artefatos em algumas imagens é inevitável, pois qualquer rede neural está sujeita a limitações técnicas e características dos dados de treinamento.
Lembre -se de que os melhores resultados são alcançados com o seguinte:
- Uma imagem PNG
- Uma imagem que é suficientemente ampliada. Durante o processo, a rede agrupa um bloco de pixels. Se o bloco contiver mais detalhes do que a rede produzir, o resultado será espúrio.
- Uma imagem tirada sob luz natural, sem filtros e com poucas cores brilhantes ou chamativas. A rede neural não foi treinada em imagens fortemente editadas.
- Uma imagem que tem uma resolução suficientemente alta para não confundir a rede com várias possibilidades (por exemplo, um pixel único em uma imagem de baixa resolução pode representar um carro inteiro, pessoa, sanduíche, ..)
- O modelo é capaz de gerar detalhes a partir de uma imagem pixelizada (DPI baixa), mas não pode corrigir uma imagem 'borrada'.
Se você estiver interessado em contribuir para o projeto Model Asset Exchange ou tiver alguma dúvida, siga as instruções aqui.


