MAX Image Resolution Enhancer
v1.1.0

Este repositorio contiene código para instanciar e implementar un potenciador de resolución de imagen. Este modelo puede mejorar una imagen pixelada por un factor de 4, al tiempo que genera detalles fotográficos.
El GaN se basa en este repositorio de GitHub y en este artículo de investigación.
El modelo fue capacitado en 600,000 imágenes del conjunto de datos OpenImages V4, y los archivos del modelo se alojan en el almacenamiento de objetos en la nube IBM. El código en este repositorio implementa el modelo como un servicio web en un contenedor Docker. Este repositorio se desarrolló como parte del IBM Developer Model Asset Exchange y la API pública está impulsada por IBM Cloud.
| Dominio | Solicitud | Industria | Estructura | Datos de capacitación | Formato de datos de entrada |
|---|---|---|---|---|---|
| Visión | Súper resolución | General | Flujo tensor | OpenImages V4 | Imagen (RGB/HWC) |
| Set5 | Srgan del autor | Este srgan |
|---|---|---|
| PSNR | 29.40 | 29.56 |
| Ssim | 0.85 | 0.85 |
| Set14 | Srgan del autor | Este srgan |
|---|---|---|
| PSNR | 26.02 | 26.25 |
| Ssim | 0.74 | 0.72 |
| BSD100 | Srgan del autor | Este srgan |
|---|---|---|
| PSNR | 25.16 | 24.4 |
| Ssim | 0.67 | 0.67 |
El rendimiento de esta implementación se evaluó en tres conjuntos de datos: SET5, SET14 y BSD100. Se evaluaron las métricas PSNR (relación de señal a ruido) y SSIM (índice de similitud estructural), aunque el documento discute el MOS (puntaje de opinión media) como la métrica más favorable. En esencia, la implementación de SRGAN intercambia una mejor puntuación PSNR o SSIM por un resultado más atractivo para el ojo humano. Esto conduce a una colección de imágenes de salida con detalles más nítidos y realistas.
Nota: El Srgan en el papel fue entrenado en muestras de 350k Imagenet, mientras que este SRGAN fue entrenado en imágenes de 600k OpenImages V4.
| Componente | Licencia | Enlace |
|---|---|---|
| Este repositorio | Apache 2.0 | LICENCIA |
| Pesas de modelos | Apache 2.0 | LICENCIA |
| Código de modelo (tercero) | MIT | LICENCIA |
| Muestras de prueba | CC por 2.0 | Readme de activos |
| CC0 | Readme de activos |
docker : la interfaz de línea de comandos Docker. Siga las instrucciones de instalación para su sistema.Para ejecutar la imagen Docker, que inicia automáticamente la API de servicio de modelo, ejecute:
$ docker run -it -p 5000:5000 quay.io/codait/max-image-resolution-enhancer
Esto extraerá una imagen preconstruida del registro de contenedores Quay.io (o usará una imagen existente si ya se almacena en caché localmente) y la ejecuta. Si prefiere pagar y construir el modelo localmente, puede seguir los pasos de ejecución locales a continuación.
Puede implementar el microservicio de servicio de modelos en Red Hat OpenShift siguiendo las instrucciones para la consola web OpenShift o la CLI de la plataforma de contenedores OpenShift en este tutorial, especificando quay.io/codait/max-image-resolution-enhancer como el nombre de la imagen.
También puede implementar el modelo en Kubernetes utilizando la última imagen de Docker en Quay.
En su clúster Kubernetes, ejecute los siguientes comandos:
$ kubectl apply -f https://github.com/IBM/max-image-resolution-enhancer/raw/master/max-image-resolution-enhancer.yaml
El modelo estará disponible internamente en el puerto 5000 , pero también se puede acceder externamente a través de NodePort .
Aquí se puede encontrar un tutorial más elaborado sobre cómo implementar este modelo MAX en la producción en IBM Cloud.
Clon este repositorio localmente. En un terminal, ejecute el siguiente comando:
$ git clone https://github.com/IBM/max-image-resolution-enhancer.git
Cambiar el directorio en la carpeta base del repositorio:
$ cd max-image-resolution-enhancer
Para construir la imagen de Docker localmente, ejecute:
$ docker build -t max-image-resolution-enhancer .
Todos los activos modelo requeridos se descargarán durante el proceso de compilación. Tenga en cuenta que actualmente esta imagen de Docker es solo CPU (agregaremos soporte para imágenes de GPU más adelante).
Para ejecutar la imagen Docker, que inicia automáticamente la API de servicio de modelo, ejecute:
$ docker run -it -p 5000:5000 max-image-resolution-enhancer
El servidor API genera automáticamente una página de documentación de Swagger interactiva. Vaya a http://localhost:5000 para cargarlo. A partir de ahí, puede explorar la API y también crear solicitudes de prueba.
Use el punto final model/predict para cargar una imagen de prueba (puede usar una de las imágenes de prueba de la carpeta de samples/test_examples/low_resolution ) para que se devuelva una imagen de salida de alta resolución.
La imagen de entrada ideal es un archivo PNG con una resolución entre 100x100 y 500x500, preferiblemente sin ningún procesamiento posterior a la captura y colores llamativos. El modelo puede generar detalles a partir de una imagen pixelada (DPI bajo), pero no puede corregir una imagen 'borrosa'.
 Izquierda: imagen de entrada (128 × 80). Derecha: imagen de salida (512 × 320)
Izquierda: imagen de entrada (128 × 80). Derecha: imagen de salida (512 × 320)
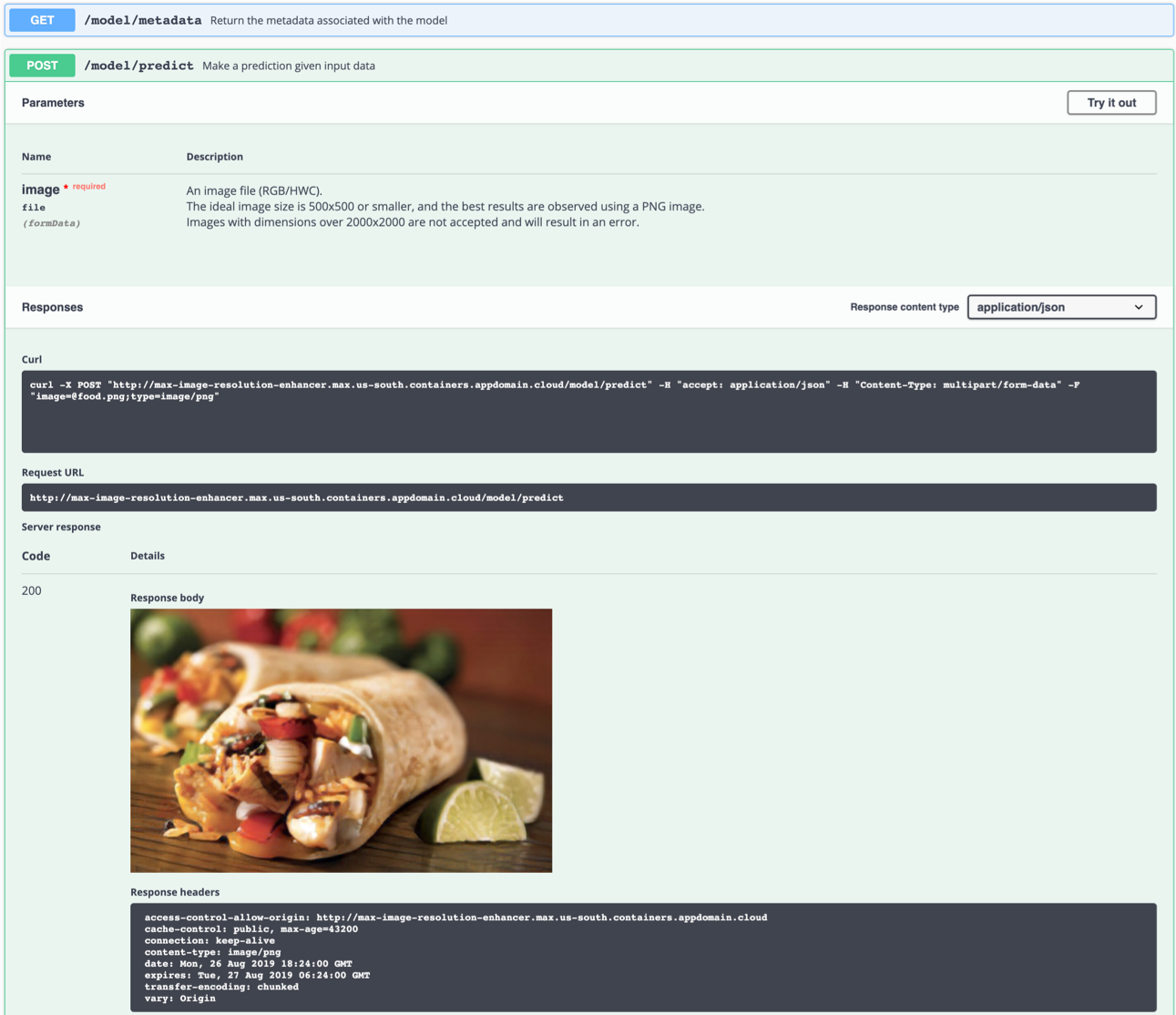
También puede probarlo en la línea de comando, por ejemplo:
$ curl -F "image=@samples/test_examples/low_resolution/food.png" -XPOST http://localhost:5000/model/predict > food_high_res.png
El comando anterior enviará el archivo food.png de baja resolución al modelo y guardará la imagen de salida de alta resolución al archivo food_high_res.png en el directorio raíz.
Para ejecutar la aplicación API de Flask en modo de depuración, edite config.py para establecer DEBUG = True en la configuración de la aplicación. Luego necesitará reconstruir la imagen Docker (ver el paso 1).
Recuerde establecer DEBUG = False al ejecutar el modelo en producción.
Para detener el contenedor Docker, escriba CTRL + C en su terminal.
model/predict el punto final mata al contenedor Docker con el mensaje KilledEs probable que esto sea causado debido a la limitación predeterminada de la asignación de memoria de Docker a 2 GB. Navegue al menú
Preferencesen la aplicación Docker Desktop. Use el control deslizante para aumentar la memoria disponible a 8 GB y reiniciar Docker Desktop.
Este modelo genera detalles básicamente 'sin aire'. Crear algo de la nada no es posible sin hacer suposiciones. La red intenta reconocer elementos en la imagen de baja resolución a partir de la cual puede inferir cómo podría haber sido la realidad (ojo humano | súper resolución). Si un grupo de píxeles se asemeja fuertemente a una observación que no está relacionada con el contenido de la imagen, podría conducir a la observación de resultados que no son "físicamente posibles".
Por ejemplo: un píxel blanco en una imagen de baja resolución podría haberse convertido en un copo de nieve, aunque la imagen original podría haberse tomado en el desierto. Este ejemplo es imaginario y en realidad no se ha observado.
Desafortunadamente, observar artefactos en algunas imágenes es inevitable ya que cualquier red neuronal está sujeta a limitaciones y características técnicas de los datos de capacitación.
Tenga en cuenta que los mejores resultados se logran con lo siguiente:
- Una imagen de PNG
- Una imagen que se acerca suficientemente. Durante el proceso, la red agrupa un bloque de píxeles juntos. Si el bloque contiene más detalles de los que produce la red, el resultado será espurio.
- Una imagen tomada bajo luz natural, sin filtros, y con pocos colores brillantes o llamativos. La red neuronal no fue entrenada en imágenes muy editadas.
- Una imagen que tiene una resolución suficientemente alta como para no confundir la red con múltiples posibilidades (por ejemplo, un único píxel en una imagen de muy baja resolución podría representar un automóvil completo, persona, sándwich, ...)
- El modelo puede generar detalles a partir de una imagen pixelada (DPI bajo), pero no puede corregir una imagen 'borrosa'.
Si está interesado en contribuir al proyecto de intercambio de activos modelo o tiene alguna consulta, siga las instrucciones aquí.


