MAX Image Resolution Enhancer
v1.1.0

Этот репозиторий содержит код для создания экземпляра и развертывания усилителя разрешения изображения. Эта модель способна увеличить пиксельное изображение в 4 раза, генерируя фотореалистичные детали.
GAN основан на этом хранилище GitHub и на этой исследовательской статье.
Модель была обучена 600 000 изображений набора данных OpenImages V4, а файлы модели размещены на хранилище облачных объектов IBM. Код в этом хранилище развертывает модель как веб -службу в контейнере Docker. Этот репозиторий был разработан в рамках обмена активами модели разработчика IBM, а публичный API оснащен IBM Cloud.
| Домен | Приложение | Промышленность | Рамки | Данные обучения | Входные данные формат |
|---|---|---|---|---|---|
| Зрение | Супер-разрешение | Общий | Tensorflow | OpenImage v4 | Изображение (RGB/HWC) |
| Set5 | Автор Srgan | Этот Срган |
|---|---|---|
| PSNR | 29,40 | 29,56 |
| SSIM | 0,85 | 0,85 |
| Set14 | Автор Srgan | Этот Срган |
|---|---|---|
| PSNR | 26.02 | 26.25 |
| SSIM | 0,74 | 0,72 |
| BSD100 | Автор Srgan | Этот Срган |
|---|---|---|
| PSNR | 25.16 | 24.4 |
| SSIM | 0,67 | 0,67 |
Производительность этой реализации была оценена на трех наборах данных: SET5, SET14 и BSD100. Были оценены показатели PSNR (пиковое отношение сигнала к шуму) и SSIM (индекс структурного сходства), хотя в статье обсуждаются MOS (средний балл мнения) как наиболее благоприятный показатель. По сути, реализация Srgan торгует лучшим результатом PSNR или SSIM для результата, более привлекательного для человеческого глаза. Это приводит к коллекции выходных изображений с более четкими и реалистичными деталями.
Примечание: Srgan в бумаге был обучен на образцах ImageNet 350K, тогда как этот Srgan был обучен на 600K OpenImages V4 с изображениями.
| Компонент | Лицензия | Связь |
|---|---|---|
| Этот репозиторий | Apache 2.0 | ЛИЦЕНЗИЯ |
| Веса модели | Apache 2.0 | ЛИЦЕНЗИЯ |
| Код модели (сторонняя сторона) | Грань | ЛИЦЕНЗИЯ |
| Тестовые образцы | CC на 2,0 | Asset Readme |
| CC0 | Asset Readme |
docker : интерфейс командной строки Docker. Следуйте инструкциям по установке для вашей системы.Чтобы запустить изображение Docker, которое автоматически запускает модель, обслуживающую API, запустите:
$ docker run -it -p 5000:5000 quay.io/codait/max-image-resolution-enhancer
Это вытащит предварительно построенное изображение из реестра контейнеров Quay.io (или использовать существующее изображение, если уже кэшируется на локальном уровне) и запустите его. Если вы предпочитаете заглянуть и построить модель локально, вы можете выполнить выполнение локально шаги ниже.
Вы можете развернуть микросервис, проводящий модель на Red Hat OpenShift, следуя инструкциям для веб-консоли OpenShift или CLI контейнерной платформы OpenShift в этом учебнике, указав quay.io/codait/max-image-resolution-enhancer в качестве имени изображения.
Вы также можете развернуть модель на Kubernetes, используя последнее изображение Docker на набережной.
На вашем кластере Kubernetes запустите следующие команды:
$ kubectl apply -f https://github.com/IBM/max-image-resolution-enhancer/raw/master/max-image-resolution-enhancer.yaml
Модель будет доступна внутри порта 5000 , но также может быть доступна внешне через NodePort .
Более сложное руководство о том, как развернуть эту максимальную модель для производства на IBM Cloud, можно найти здесь.
Клонировать это хранилище локально. В терминале запустите следующую команду:
$ git clone https://github.com/IBM/max-image-resolution-enhancer.git
Изменить каталог в базовую папку репозитория:
$ cd max-image-resolution-enhancer
Чтобы построить изображение Docker локально, запустите:
$ docker build -t max-image-resolution-enhancer .
Все необходимые модельные активы будут загружены в процессе сборки. Обратите внимание , что в настоящее время это изображение Docker является только процессором (мы добавим поддержку изображений GPU позже).
Чтобы запустить изображение Docker, которое автоматически запускает модель, обслуживающую API, запустите:
$ docker run -it -p 5000:5000 max-image-resolution-enhancer
API -сервер автоматически генерирует интерактивную страницу документации Swagger. Перейдите в http://localhost:5000 чтобы загрузить его. Оттуда вы можете исследовать API, а также создать тестовые запросы.
Используйте model/predict конечную точку для загрузки тестового изображения (вы можете использовать одно из тестовых изображений из папки samples/test_examples/low_resolution »), чтобы вернуть выходное изображение высокого разрешения.
Идеальное входное изображение представляет собой файл PNG с разрешением между 100x100 и 500x500, предпочтительно без какой-либо обработки после захвата и ярких цветов. Модель способна генерировать детали с пиксельного изображения (низкий DPI), но не может исправить «размытое» изображение.
 Слева: входное изображение (128 × 80). Справа: выходное изображение (512 × 320)
Слева: входное изображение (128 × 80). Справа: выходное изображение (512 × 320)
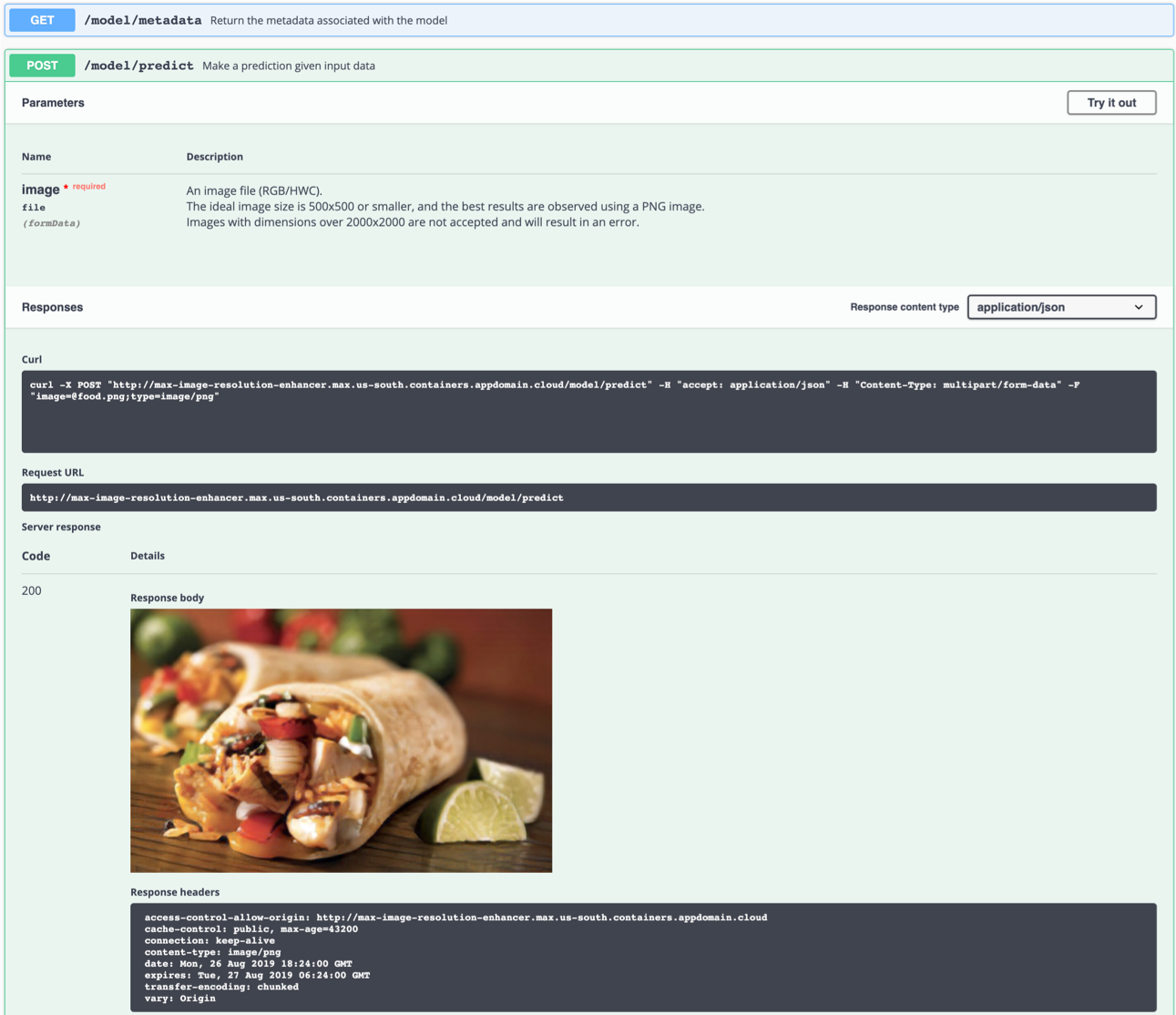
Вы также можете проверить его в командной строке, например:
$ curl -F "image=@samples/test_examples/low_resolution/food.png" -XPOST http://localhost:5000/model/predict > food_high_res.png
food_high_res.png выше команда отправит файл food.png с низким разрешением.
Чтобы запустить приложение Flask API в режиме отладки, отредактируйте config.py , чтобы установить DEBUG = True в настройках приложения. Затем вам нужно будет восстановить изображение Docker (см. Шаг 1).
Пожалуйста, не забудьте установить DEBUG = False при запуске модели в производстве.
Чтобы остановить контейнер Docker, введите CTRL + C в вашем терминале.
model/predict конечной точки убивает контейнер Docker с Killed сообщениемЭто, вероятно, вызвано из -за ограничения распределения памяти Docker до 2 ГБ. Перейдите в меню
Preferencesпод настольным приложением Docker. Используйте ползунок, чтобы увеличить доступную память до 8 ГБ и перезапустите Docker Desktop.
Эта модель генерирует детали в основном «из воздуха». Создание чего -то из ничего невозможно без предположений. Сеть пытается распознать элементы на изображении с низким разрешением, из которого она может сделать вывод, как могла бы выглядеть реальность (человеческий глаз | Супер-разрешение). Если группа пикселей сильно напоминает наблюдение, которое не связано с содержанием изображения, это может привести к наблюдению за результатами, которые не являются «физически возможными».
Например: белый пиксель на изображении с низким разрешением мог быть преобразован в снежинок, хотя оригинальная картина могла быть сделана в пустыне. Этот пример является воображаемым и фактически не наблюдался.
Наблюдение за артефактами на некоторых изображениях, к сожалению, неизбежно, поскольку любая нейронная сеть подлежит техническим ограничениям и характеристикам данных обучения.
Имейте в виду, что наилучшие результаты достигнуты со следующими:
- Изображение PNG
- Изображение, которое достаточно увеличено. Во время процесса сетевые группы объединяют блок пикселей. Если блок содержит больше деталей, чем производит сеть, результат будет ложным.
- Изображение, сделанное под естественным светом, без фильтров, и с несколькими яркими или яркими цветами. Нейронная сеть не была обучена сильно отредактированным изображениям.
- Изображение, которое имеет достаточно высокое разрешение, чтобы не путать сеть с множеством возможностей (например, единственный пиксель на изображении с очень низким разрешением может представлять собой целый автомобиль, человек, бутерброд, ..)
- Модель способна генерировать детали с пиксельного изображения (низкий DPI), но не может исправить «размытое» изображение.
Если вы заинтересованы в участии в проекте Model Asset Exchange или имеете какие -либо вопросы, пожалуйста, следуйте инструкциям здесь.


