MAX Image Resolution Enhancer
v1.1.0

이 저장소에는 이미지 해상도 인핸서를 인스턴스화하고 배포하는 코드가 포함되어 있습니다. 이 모델은 사진 현실 세부 사항을 생성하면서 픽셀 화 된 이미지를 4 배로 고급 스케일 할 수 있습니다.
GAN 은이 GitHub 저장소 와이 연구 기사를 기반으로합니다.
이 모델은 OpenImages v4 데이터 세트의 60 만 이미지에 대해 교육을 받았으며 모델 파일은 IBM Cloud Object Storage에서 호스팅됩니다. 이 저장소의 코드는 모델을 Docker 컨테이너의 웹 서비스로 배포합니다. 이 저장소는 IBM Developer Model Asset Exchange의 일부로 개발되었으며 공개 API는 IBM Cloud에 의해 구동됩니다.
| 도메인 | 애플리케이션 | 산업 | 뼈대 | 교육 데이터 | 입력 데이터 형식 |
|---|---|---|---|---|---|
| 비전 | 초-해상도 | 일반적인 | 텐서 플로 | OpenImages v4 | 이미지 (RGB/HWC) |
| 세트 5 | 저자의 Srgan | 이 srgan |
|---|---|---|
| PSNR | 29.40 | 29.56 |
| SSIM | 0.85 | 0.85 |
| set14 | 저자의 Srgan | 이 srgan |
|---|---|---|
| PSNR | 26.02 | 26.25 |
| SSIM | 0.74 | 0.72 |
| BSD100 | 저자의 Srgan | 이 srgan |
|---|---|---|
| PSNR | 25.16 | 24.4 |
| SSIM | 0.67 | 0.67 |
이 구현의 성능은 SET5, SET14 및 BSD100의 세 가지 데이터 세트에서 평가되었습니다. PSNR (피크 신호 대 노이즈 비율) 및 SSIM (구조적 유사성 지수) 메트릭이 평가되었지만 논문은 MOS (평균 의견 점수)를 가장 유리한 메트릭으로 논의합니다. 본질적으로, SRGAN 구현은 인간의 눈에 더 매력적인 결과를 위해 더 나은 PSNR 또는 SSIM 점수를 거래합니다. 이로 인해 더 선명하고 현실적인 세부 사항이있는 출력 이미지 모음이됩니다.
참고 :이 논문의 Srgan은 350k Imagenet 샘플로 훈련 된 반면,이 Srgan은 600k OpenImages v4 그림에서 훈련되었습니다.
| 요소 | 특허 | 링크 |
|---|---|---|
| 이 저장소 | 아파치 2.0 | 특허 |
| 모델 가중치 | 아파치 2.0 | 특허 |
| 모델 코드 (제 3 자) | MIT | 특허 |
| 테스트 샘플 | CC x 2.0 | 자산 readme |
| CC0 | 자산 readme |
docker : Docker 명령 줄 인터페이스. 시스템의 설치 지침을 따르십시오.API를 제공하는 모델을 자동으로 시작하는 Docker 이미지를 실행하려면 실행합니다.
$ docker run -it -p 5000:5000 quay.io/codait/max-image-resolution-enhancer
이렇게하면 quay.io 컨테이너 레지스트리에서 사전 제작 된 이미지를 가져 오거나 (이미 로컬로 캐시 된 경우 기존 이미지를 사용) 실행합니다. 오히려 체크 아웃하고 로컬로 모델을 구축하고 싶다면 아래로 현지 단계를 따라갈 수 있습니다.
이 튜토리얼의 OpenShift 웹 콘솔 또는 OpenShift 컨테이너 플랫폼 CLI에 대한 지침에 따라 quay.io/codait/max-image-resolution-enhancer 를 이미지 이름으로 지정하여 Red Hat OpenShift에 모델 서비스 마이크로 서비스를 배치 할 수 있습니다.
Quay의 최신 Docker 이미지를 사용하여 Kubernetes의 모델을 배포 할 수도 있습니다.
Kubernetes 클러스터에서 다음 명령을 실행하십시오.
$ kubectl apply -f https://github.com/IBM/max-image-resolution-enhancer/raw/master/max-image-resolution-enhancer.yaml
이 모델은 포트 5000 에서 내부적으로 제공되지만 NodePort 통해 외부에 액세스 할 수도 있습니다.
이 최대 모델을 IBM 클라우드에서 제작에 배치하는 방법에 대한보다 정교한 자습서는 여기에서 찾을 수 있습니다.
이 저장소를 로컬로 복제하십시오. 터미널에서 다음 명령을 실행하십시오.
$ git clone https://github.com/IBM/max-image-resolution-enhancer.git
디렉토리를 저장소 기본 폴더로 변경하십시오.
$ cd max-image-resolution-enhancer
Docker 이미지를 로컬로 만들려면 다음을 실행하십시오.
$ docker build -t max-image-resolution-enhancer .
필요한 모든 모델 자산은 빌드 프로세스 중에 다운로드됩니다. 현재이 Docker 이미지는 CPU 전용입니다 (나중에 GPU 이미지에 대한 지원을 추가 할 것 입니다).
API를 제공하는 모델을 자동으로 시작하는 Docker 이미지를 실행하려면 실행합니다.
$ docker run -it -p 5000:5000 max-image-resolution-enhancer
API 서버는 대화식 Swagger 문서 페이지를 자동으로 생성합니다. http://localhost:5000 으로 이동하여로드하십시오. 거기에서 API를 탐색하고 테스트 요청을 만들 수도 있습니다.
model/predict 엔드 포인트를 사용하여 테스트 이미지를로드하십시오 ( samples/test_examples/low_resolution 폴더의 테스트 이미지 중 하나를 사용할 수 있음).
이상적인 입력 이미지는 100x100에서 500x500 사이의 해상도가있는 PNG 파일이며, 캡처 후 처리 및 화려한 색상이없는 바람직합니다. 이 모델은 픽셀 화 된 이미지 (낮은 DPI)에서 세부 사항을 생성 할 수 있지만 '흐릿한'이미지를 수정할 수는 없습니다.
 왼쪽 : 입력 이미지 (128 × 80). 오른쪽 : 출력 이미지 (512 × 320)
왼쪽 : 입력 이미지 (128 × 80). 오른쪽 : 출력 이미지 (512 × 320)
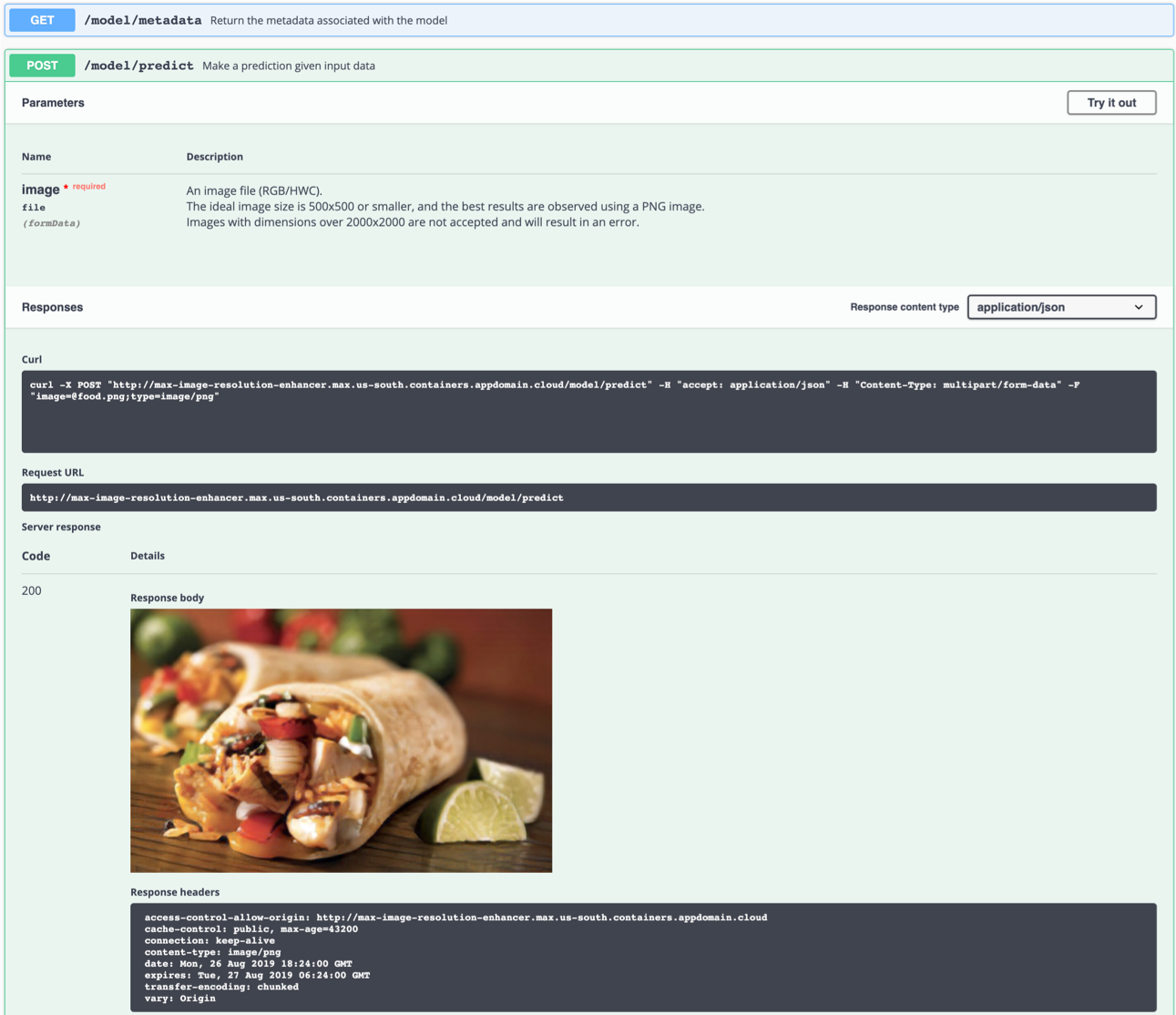
예를 들어 명령 줄에서 테스트 할 수도 있습니다.
$ curl -F "image=@samples/test_examples/low_resolution/food.png" -XPOST http://localhost:5000/model/predict > food_high_res.png
위의 명령은 저해상도 food.png 파일을 모델로 보내고 고해상도 출력 이미지를 루트 디렉토리의 food_high_res.png 파일에 저장합니다.
디버그 모드에서 Flask API 앱을 실행하려면 config.py 편집하여 응용 프로그램 설정에서 DEBUG = True 설정하십시오. 그런 다음 Docker 이미지를 재건해야합니다 (1 단계 참조).
프로덕션에서 모델을 실행할 때 DEBUG = False 설정해야합니다.
Docker 컨테이너를 중지하려면 터미널에 CTRL + C 입력하십시오.
model/predict 엔드 포인트는 Killed 메시지로 Docker 컨테이너를 죽입니다.이는 Docker의 메모리 할당이 2GB로 기본 제한으로 인해 발생할 수 있습니다. Docker Desktop 애플리케이션에서
Preferences메뉴로 이동하십시오. 슬라이더를 사용하여 사용 가능한 메모리를 8GB로 늘리고 Docker Desktop을 다시 시작하십시오.
이 모델은 기본적으로 '얇은 공기에서'세부 사항을 생성합니다. 아무것도없는 것을 만들어내는 것은 가정하지 않고는 불가능합니다. 네트워크는 저해상도 이미지에서 요소를 인식하려고 시도하여 현실 (인간의 눈 | 초-해상도)이 어떻게 보일 수 있었는지 추론 할 수 있습니다. 픽셀 그룹이 이미지의 내용과 관련이없는 관찰과 매우 유사하면 '물리적으로 불가능한 결과'를 관찰 할 수 있습니다.
예를 들어, 저해상도 이미지의 흰색 픽셀은 사막에서 원래 그림이 찍은 것일 수 있지만 눈송이로 변환되었을 수 있습니다. 이 예는 상상력이 있으며 실제로 관찰되지 않았습니다.
일부 이미지에서 인공물을 관찰하는 것은 불행히도 모든 신경망이 훈련 데이터의 기술적 한계와 특성을 받기 때문에 불가피합니다.
최상의 결과는 다음과 같이 달성됩니다.
- PNG 이미지
- 프로세스 동안 네트워크는 픽셀 블록을 함께 그룹화합니다. 블록에 네트워크가 생성하는 것보다 더 많은 세부 사항이 포함되어 있으면 결과는 가짜입니다.
- 필터없이 자연광에서 찍은 이미지, 밝고 화려한 색상이 거의 없습니다. 신경망은 심하게 편집 된 이미지에 대해 훈련되지 않았습니다.
- 네트워크를 여러 가지 가능성과 혼동하지 않기에 충분히 높은 해상도를 가진 이미지 (예 : 매우 저해상도 이미지의 유일한 픽셀은 전체 자동차, 사람, 샌드위치, ..)를 나타낼 수 있습니다.)
- 이 모델은 픽셀 화 된 이미지 (낮은 DPI)에서 세부 사항을 생성 할 수 있지만 '흐릿한'이미지를 수정할 수는 없습니다.
Model Asset Exchange 프로젝트에 기여하거나 쿼리가 있으시면 여기에서 지침을 따르십시오.


